- Java集合框架
- 1.阻塞队列的阻塞是什么含义?
- 2.阻塞队列的实现方式?
- 3.线程不安全的集合变成线程安全的方法?
- 4.HashMap的底层数据结构?
- 5.为什么 HashMap 是线程不安全的?
- 6.平衡二叉树
- 7.HashMap 的 put 流程
- 8.只重写 equals 没重写 hashcode,map put 的时候会发生什么?
- 9.为什么要用高低做异或运算?为什么非得高低 16 位异或?
- 10.为什么 HashMap 的容量是 2 的倍数呢?hashCode 对数组长度取模定位数组下标的优化策略?
- 11.map 集合在使用时候一般都需要写容量值?为什么要写?扩容机制?
- 12.红黑树转回链表的阈值为什么默认是6而不是8?
- 13.JDK8对HashMap的实现原理做了哪些优化?
- 14.HashMap和TreeMap的区别?
- Java并发编程
- 1.你对线程安全的理解是什么?
- 2.线程和进程的区别?
- 3.线程共享内存和进程共享内存的区别?
- 4.有多少种实现线程的方式?
- 5.为什么在项目中使用线程池?
- 6.讲一讲你对线程池的理解,并讲一讲使用的场景
- 7. 线程池在使用时需要注意什么?
- 8.你能设计并实现一个线程池吗?
- 9.调用 start()方法时会执行 run()方法,那怎么不直接调用 run()方法?
- 10.线程有哪些常用的调度方法?
- 11.线程的生命周期和状态?
- 12.什么是线程的上下文切换?
- 13.守护线程了解吗?
- 14.线程间的通信方式?
- 15.sleep 和 wait 的区别?
- 16.举例一个线程安全的使用场景?
- 17.请说一下 ThreadLocal 的作用和使用场景?
- 18.除了 ThreadLocal,还有什么解决线程安全问题的方法?
- 19.ThreadLocal 怎么实现的呢?
- 20.java中的引用类型?
- 21.ThreadLocal内存泄漏是怎么回事?
- 22.ThreadLocal结合线程池使用导致的复用问题?
- 23.ThreadLocal的删除过程?
- 24.ThreadLocalMap的源码分析?
- 25.ThreadLocalMap如何解决Hash冲突?
- 26.ThreadLocalMap的扩容?
- 27.父子线程怎么共享数据?
- 28.为什么线程要使用自己的内存?
- 29.对原子性、可见性、有序性的理解?
- 30.什么是指令重排?
- 31.volatile关键字的实现原理?
- 32.volatile加在基本类型和对象上的区别?
- 33.synchronized 用过吗?怎么使用?
- 34.synchronized和ReentrantLock区别和场景?
- 35.AQS 了解多少?
- 36.ReentrantLock 实现原理?
- 37.ReentrantLock 怎么实现公平锁的?
- 38.CAS 了解多少?
- 39.CAS 有什么问题?如何解决?
- 40.原子操作类了解多少?
- 41.线程死锁了解吗?该如何避免?
- 42.死锁问题怎么排查呢?
- 43.乐观锁和悲观锁?
- 44.CountDownLatch(倒计数器)了解吗?
- 45.CyclicBarrier(同步屏障)了解吗?
- 46.CyclicBarrier 和 CountDownLatch 有什么区别?
- 47.Semaphore(信号量)了解吗?
- 48.Exchanger 了解吗?
- 49.ConcurrentHashMap 对 HashMap 的优化?ConcurrentHashMap 1.8 比 1.7 的优化在哪里?
- 50.为什么 ConcurrentHashMap 在 JDK 1.7 中要用 ReentrantLock,而在 JDK 1.8 要用 synchronized?
- 51.为什么 ConcurrentHashMap 比 Hashtable 效率高
- JVM
- 1.什么是JVM?
- 2.JVM的组织架构?
- 3.JVM内存结构
- 4.说一下 JDK1.6、1.7、1.8 内存区域的变化?
- 5.JDK 1.8 中的元空间(Metaspace)相对于永久代(PermGen)的优势?
- 6.对象的创建销毁的过程?
- 7.JVM 里 new 对象时,堆会发生抢占吗?JVM 是怎么设计来保证线程安全的?
- 8.对象的内存布局,对象的底层数据结构?
- 9.对象如何访问定位?
- 10.说说内存溢出(OOM)和内存泄漏(Leak Memory)的原因?
- 11.Java 堆的内存分区了解吗?
- 12.对象什么时候会进入老年代?
- 13.什么是 Stop The World ? 什么是 OopMap ?什么是安全点?
- 14.对象一定分配在堆中吗?有没有了解逃逸分析技术?
- 15.JVM垃圾回收机制?
- 16.有了 CMS,为什么还要引入 G1?
- 16.有哪些常用的命令行性能监控和故障处理工具?
- 17.了解哪些可视化的性能监控和故障处理工具?
- 18.JVM 的常见参数配置知道哪些?
- 19.线上服务 CPU 占用过高怎么排查?
- 20.内存飙高问题怎么排查?
- 21.频繁 minor gc 怎么办?
- 22.频繁 Full GC 怎么办?
- 23.有没有处理过内存泄漏问题?是如何定位的?
- 24.有没有处理过 OOM 问题?
- 25.了解类的加载机制吗?
- 26.类加载器有哪些?
- 27.能说一下类的生命周期吗?
- 28.什么是双亲委派模型?
- 29.为什么要用双亲委派模型?
- 30.如何破坏双亲委派机制?
- 31.Tomcat 的类加载机制了解吗?
- 32.你觉得应该怎么实现一个热部署功能?
- 33.解释执行和编译执行的区别?
- Spring
- 1.Spring是什么?
- 2.Spring的模块
- 3.Spring有哪些常用注解?
- 4.Spring 中应用了哪些设计模式呢?
- 5.spring的容器、web容器、springmvc的容器之间的区别?
- 6.说一说什么是 IoC?什么是 DI?
- 7.能简单说一下 Spring IoC 的实现机制吗?
- 8.说说 BeanFactory 和 ApplicantContext?
- 9.Spring 的 Bean 实例化方式?
- 10.能说一下 Spring Bean 生命周期吗?
- 11.Bean 定义和依赖定义有哪些方式?
- 12.Spring 有哪些自动装配的方式?
- 13.Spring 中的 Bean 的作用域有哪些?
- 14.Spring 中的单例 Bean 会存在线程安全问题吗?
- 15.循环依赖问题
- 16.@Autowired 的实现原理?
- 17.说说什么是 AOP?
- 18.说说 JDK 动态代理和 CGLIB 代理?
- 19.说说 Spring AOP 和 AspectJ AOP 区别?
- 20.Spring 事务的种类?
- 21.Spring的事务隔离级别?
- 22.Spring 的事务传播机制?
- 23.protected 和 private 加事务会生效吗
- 23.声明式事务实现原理了解吗?
- 24.声明式事务在哪些情况下会失效?
- 25.Spring MVC 的核心组件?
- 26.Spring MVC 的工作流程?
- 27.SpringMVC Restful 风格的接口的流程是什么样的呢?
- 28.介绍一下 SpringBoot,有哪些优点?
- 30.SpringBoot 自动配置原理了解吗?
- 31.如何自定义一个 SpringBoot Srarter?
- 32.Spring Boot Starter 的原理了解吗?
- 33.Spring Boot 启动原理了解吗?
- 34.SpringBoot 和 SpringMVC 的区别?
- 35.Spring Boot 和 Spring 有什么区别?
- 36.对 SpringCloud 了解多少?
- 37.SpringTask 了解吗?
- Redis
- 1.说说什么是 Redis?
- 2.Redis 可以用来干什么?
- 3.Redis 有哪些数据类型?
- 4.Redis 为什么快呢?
- 5.能说一下 I/O 多路复用吗?
- 6.Redis 为什么早期选择单线程?
- 7.Redis6.0 使用多线程是怎么回事?
- 8.Redis 常用命令
- 9.单线程 Redis 的 QPS 是多少?
- 10.Redis 持久化⽅式有哪些?有什么区别?
- 11.RDB 和 AOF 如何选择?
- 12.Redis 的数据恢复?
- 13.Redis主从复制
- 14.Redis 主从有几种常见的拓扑结构?
- 15.Redis 的主从复制原理了解吗?
- 16.说说主从数据同步的方式?
- 17.主从复制存在哪些问题呢?
- 18.Redis 哨兵了解吗?
- 19.Redis 哨兵实现原理知道吗?
- 20.新的主节点是怎样被挑选出来的?
- 21.Redis 集群了解吗?
- 21.切片集群了解吗?
- 22.集群中的数据如何分区
- 23.能说说 Redis 集群的原理吗?
- 24.部署 Redis 集群至少需要几个物理节点?
- 25.说说集群的伸缩?
- 26.什么是缓存击穿、缓存穿透、缓存雪崩?
- 27.能说说布隆过滤器吗?
- 28.如何保证缓存和数据库的数据⼀致性?
- 29.如何保证本地缓存和分布式缓存的一致?
- 30.怎么处理热 key?
- 31.缓存预热怎么做呢?
- 32.热点 key 重建?问题?解决?
- 33.知道无底洞问题吗?如何解决?
- 34.Redis 报内存不足怎么处理?
- 35.Redis 的过期数据回收策略有哪些?
- 36.Redis 有哪些内存淘汰策略?
- 37.Redis 阻塞?怎么解决?
- 38.大 key 问题了解吗?
- 39.Redis 常见性能问题和解决方案?
- 40.使用 Redis 如何实现异步队列?
- 41.Redis 如何实现延时队列?
- 41.Redis 支持事务吗?
- 42.Redis 和 Lua 脚本的使用了解吗?
- 43.Redis 的管道Pipeline了解吗?
- 43.Redis 实现分布式锁了解吗?
- 44.Redis 底层数据结构?
- 45.Redis 的 SDS 和 C 中字符串相比有什么优势?
- 46.字典是如何实现的?Rehash 了解吗?
- 47.跳表是如何实现的?原理?
- 48.压缩列表了解吗?
- 49.快速列表 quicklist 了解吗?
- 50.假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如何将它们全部找出来?
- 51.秒杀问题(错峰、削峰、前端、流量控制)
- MyBatis
- 1.什么是MyBatis?
- 2. Hibernate 和 MyBatis 有什么区别?
- 3.MyBatis 使用过程?生命周期?
- 4.在 mapper 中如何传递多个参数?
- 5.实体类属性名和表中字段名不一样 ,怎么办?
- 6.Mybatis 是否可以映射 Enum 枚举类?
- 7.#{}和${}的区别?
- 8.模糊查询 like 语句该怎么写?
- 9.Mybatis 能执行一对一、一对多的关联查询吗?
- 10.Mybatis 是否支持延迟加载?原理?
- 11.如何获取生成的主键?
- 12.MyBatis 支持动态 SQL 吗?
- 13.MyBatis 如何执行批量操作?
- 14.说说 Mybatis 的一级、二级缓存?
- 15.能说说 MyBatis 的工作原理吗?
- 16.MyBatis 的功能架构是什么样的?
- 17.为什么 Mapper 接口不需要实现类?
- 18.Mybatis 都有哪些 Executor 执行器?
- 19.说说 Mybatis 的插件运行原理,如何编写一个插件?
- 20.MyBatis 是如何进行分页的?分页插件的原理是什么?
- 21.说说 JDBC 的执行步骤?
- 22.创建连接拿到的是什么对象?
- 23.Statement 与 PreparedStatement 的区别
- 24.什么是 SQL 注入?如何防止 SQL 注入?
- MySQL
- 1.MySQL 的内连接、左连接、右连接有什么区别?
- 2.什么是三大范式,为什么要有三大范式,什么场景下不用遵循三大范式,举一个场景?
- 3.varchar 与 char 的区别?
- 4.blob 和 text 有什么区别?
- 5.DATETIME 和 TIMESTAMP 的异同?
- 6.MySQL 中 in 和 exists 的区别?
- 7.MySQL 里记录货币用什么字段类型比较好?
- 8.MySQL 怎么存储 emoji?
- 9.drop、delete 与 truncate 的区别?
- 10.UNION 与 UNION ALL 的区别?
- 11.count(1)、count(*) 与 count(列名) 的区别?
- 12.一条 SQL 查询语句的执行顺序?
- 13.介绍一下 MySQL 的常用命令
- 14.介绍一下 MySQL bin 目录下的可执行文件
- 15.MySQL 第 3-10 条记录怎么查?
- 16.用过哪些 MySQL 函数?
- 17.说说 SQL 的隐式数据类型转换?
- 18.说说 MySQL 的基础架构?
- 19.一条 SQL 查询语句在 MySQL 中如何执行的?
- 20.说说 MySQL 的数据存储形式
- 21.MySQL 有哪些常见存储引擎?
- 22.存储引擎应该怎么选择?
- 23.InnoDB 和 MyISAM 主要有什么区别?
- 24.MySQL 日志文件有哪些?分别介绍下作用?
- 25.binlog 和 redo log 有什么区别?
- 26.一条更新语句怎么执行的了解吗?
- 27.redo log 怎么刷入磁盘的知道吗?
- 28.慢 SQL 如何定位呢?
- 29.有哪些方式优化 SQL?
- 30.怎么看执行计划 explain,如何理解其中各个字段的含义?
- 31.为什么使用索引会加快查询?
- 32.能简单说一下索引的分类吗?
- 从存储位置上分类
- 33.创建索引有哪些注意点?
- 34.索引哪些情况下会失效呢?
- 35.索引不适合哪些场景呢?
Java集合框架
1.阻塞队列的阻塞是什么含义?
阻塞队列的“阻塞”指的是当生产者往队列中添加元素时,如果队列已满,则生产者的添加操作会被阻塞,直到队列中有空闲空间;同样地,当消费者从队列中移除元素时,如果队列为空,则消费者的移除操作会被阻塞,直到队列中有新的元素被添加进来。这种机制确保了在多线程环境下队列的操作是线程安全的,并且能够有效地协调生产者和消费者之间的同步问题。
2.阻塞队列的实现方式?
Java中的BlockingQueue接口定义了阻塞队列的行为,并且Java并发库java.util.concurrent提供了多种BlockingQueue的具体实现。
ArrayBlockingQueue:
基于数组结构的有界阻塞队列。 固定大小的队列,当队列满时,生产者线程会被阻塞,直到队列中的元素被消费掉。 当队列空时,消费者线程会被阻塞,直到队列中有新的元素加入。
LinkedBlockingQueue:
基于链表结构的阻塞队列。 可以指定容量大小,如果不指定,默认为Integer.MAX_VALUE。 当队列满时,生产者线程会被阻塞;当队列空时,消费者线程会被阻塞。
PriorityBlockingQueue:
具有优先级的无界阻塞队列。 类似于PriorityQueue,但是加入了阻塞的功能。 不会阻塞生产者线程,但是可以保证具有较高优先级的元素会被先消费。
DelayQueue:
使用Delayed类型的元素的无界阻塞队列。 队列中的元素只有在其延迟过期后才能被消费者线程消费。 生产者线程不会被阻塞,但消费者线程可能会因为没有到期的元素而被阻塞。
SynchronousQueue:
不存储元素的阻塞队列。 每个插入操作必须等待另一个线程的对应移除操作,反之亦然。 实际上不存储任何元素,更多地用于线程间的数据交换。
LinkedTransferQueue:
基于链表结构的无界阻塞队列。 提供了更强的传递语义,允许生产者直接将元素传给消费者,如果消费者不存在则放入内部队列。 支持传递操作,即生产者可以直接将元素传递给消费者线程
3.线程不安全的集合变成线程安全的方法?
使用synchronizedXxx()方法:
java.util.Collections类提供了一系列静态方法,如synchronizedList(), synchronizedSet(), synchronizedMap()等,可以将线程不安全的集合包装成线程安全的集合。 例如,对于ArrayList,可以使用Collections.synchronizedList(new ArrayList<>())将其转换为线程安全的列表。
使用同步容器:
Java标准库提供了一些内置的线程安全容器,如Vector和Hashtable。 Vector是线程安全的List实现,而Hashtable是线程安全的Map实现。
显式同步:
可以手动对集合的操作进行同步控制,比如在访问集合前加上synchronized关键字,并使用集合对象本身或其外部的对象作为锁。 示例代码如下:
List list = new ArrayList<>();
Object lock = new Object();
synchronized(lock) {
// 在这里执行对list的安全操作
}
使用并发集合:
Java并发包java.util.concurrent提供了线程安全的集合实现,如ConcurrentHashMap, CopyOnWriteArrayList, CopyOnWriteArraySet等。 这些集合在设计时就考虑到了并发访问的问题,因此不需要额外的同步措施。
使用ReentrantLock或其他锁机制:
可以使用更高级的锁机制,如ReentrantLock,来替代synchronized关键字,以获得更细粒度的锁控制。
使用不可变集合:
创建不可变集合,一旦创建就不能改变,这样也避免了并发修改的问题。 不可变集合可以被认为是线程安全的,因为它们的状态不会改变。
4.HashMap的底层数据结构?
JDK 8 中 HashMap 的数据结构是数组+链表+红黑树。
HashMap 的核心是一个动态数组(Node[] table),用于存储键值对。这个数组的每个元素称为一个“桶”(Bucket),每个桶的索引是通过对键的哈希值进行哈希函数处理得到的。
当多个键经哈希处理后得到相同的索引时,会发生哈希冲突。HashMap 通过链表来解决哈希冲突——即将具有相同索引的键值对通过链表连接起来。
不过,链表过长时,查询效率会比较低,于是当链表的长度超过 8 时(且数组的长度大于 64),链表就会转换为红黑树。红黑树的查询效率是 O(logn),比链表的 O(n) 要快。数组的查询效率是 O(1)。
链表转换为红黑树的条件
链表长度:当单个桶(bucket)中的链表长度达到 8 时,该链表会被转换为红黑树。 最小树化容量:HashMap 的总容量(桶数组大小)必须至少为 64。如果 HashMap 的容量小于 64,即使链表长度达到 8,也不会进行树化,而是会选择扩容。
红黑树转换为链表的条件
树节点数量:当红黑树节点元素小于等于 6 时,红黑树会被转换回链表形式。这是因为,在小数据量时,链表的效率更高。
转换逻辑
树化:当一个桶中的链表长度达到 8,并且 HashMap 的容量大于等于 64 时,这个链表会被转换成红黑树。这样做的目的是为了减少链表的长度,从而提高查找的效率。红黑树的平均查找长度是 O(log n),相比于链表的 O(n),在链表长度较长时性能更好。
链表化:当红黑树中的节点数量减少到 6 或更少时,红黑树会被转换回链表。这是因为对于少量的数据,链表的开销较小,转换为链表可以减少不必要的内存占用和管理开销。
扩容机制
扩容:在某些情况下,如果 HashMap 的容量不足以容纳更多的元素,或者链表长度达到树化阈值但容量不足时,HashMap 会进行扩容。扩容操作会将容量加倍,并重新散列所有的元素。
当向 HashMap 中添加一个键值对时,会使用哈希函数计算键的哈希码,确定其在数组中的位置,哈希函数的目标是尽量减少哈希冲突,保证元素能够均匀地分布在数组的每个位置上。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
当向 HashMap 中添加元素时,如果该位置已有元素(发生哈希冲突),则新元素将被添加到链表的末尾或红黑树中。如果键已经存在,其对应的值将被新值覆盖。
当从 HashMap 中获取元素时,也会使用哈希函数计算键的位置,然后根据位置在数组、链表或者红黑树中查找元素。
HashMap 的初始容量是 16,随着元素的不断添加,HashMap 的容量(也就是数组大小)可能不足,于是就需要进行扩容,阈值是capacity * loadFactor,capacity 为容量,loadFactor 为负载因子,默认为 0.75。
扩容后的数组大小是原来的 2 倍,然后把原来的元素重新计算哈希值,放到新的数组中。
总的来说,HashMap 是一种通过哈希表实现的键值对集合,它通过将键哈希化成数组索引,并在冲突时使用链表或红黑树来存储元素,从而实现快速的查找、插入和删除操作。
5.为什么 HashMap 是线程不安全的?
修改操作非原子性
HashMap 的修改操作(如 put 和 remove)并没有使用锁来保证原子性,这意味着在多线程环境中,这些操作可能会被中断,导致数据不一致。 例如,在 put 操作中,HashMap 需要计算哈希值、找到桶的位置、插入键值对等步骤,这些步骤在多线程环境下可能被其他线程干扰。
扩容时的竞态条件
当 HashMap 达到其容量限制时,它会进行扩容操作,这个过程涉及到重新散列所有已存在的键值对。 如果多个线程同时触发扩容操作,可能会导致竞态条件,其中一个线程的扩容操作可能被另一个线程覆盖,从而导致数据丢失或不一致。
链表或红黑树操作的不一致性
当多个线程同时操作同一个桶中的链表或红黑树时,如果没有适当的同步机制,可能会导致链表或红黑树的结构被破坏,进而导致数据丢失或无限循环等问题。
可见性问题
HashMap 中的变量(如容量、阈值等)在多线程环境中如果没有正确的同步机制,可能会导致线程间的可见性问题,即一个线程修改的数据不能被另一个线程及时看到。
解决方案
为了使 HashMap 在多线程环境中安全使用,可以采取以下措施:
使用 Collections.synchronizedMap:将 HashMap 包装成线程安全的集合。
使用 ConcurrentHashMap:这是 HashMap 的线程安全版本,专为多线程环境设计。 显式同步:在访问 HashMap 时手动加锁,确保同一时刻只有一个线程能够修改 HashMap。
6.平衡二叉树
平衡二叉树(Balanced Binary Tree)是一种特殊的二叉树,其中任意节点的左右子树高度差不超过一定范围。常见的平衡二叉树有 AVL 树和红黑树。
AVL 树
AVL 树是一种自平衡的二叉查找树,它通过在每个节点上存储一个平衡因子(balance factor)来保持树的平衡。平衡因子定义为左右子树的高度差,它可以是 -1、0 或 1。
AVL 树的基本操作
插入操作:
插入新节点。 通过旋转操作来保持平衡。
删除操作:
删除指定节点。 通过旋转操作来保持平衡。
查找操作:
在 AVL 树中查找指定键值的节点。
当平衡二叉树(如 AVL 树)的平衡性被破坏时,通常是因为插入或删除了一个节点,导致某些节点的平衡因子(左子树高度与右子树高度之差)的绝对值超过了允许的范围(对于 AVL 树来说是 1)。为了恢复平衡,需要执行一系列旋转操作。
恢复平衡的步骤
确定破坏点:找到第一个平衡因子绝对值大于 1 的节点。
识别破坏模式:根据破坏点与其子节点的关系,确定破坏模式。
执行相应的旋转操作:根据破坏模式执行单旋转或多旋转(双旋转)。
常见的破坏模式和对应的旋转操作
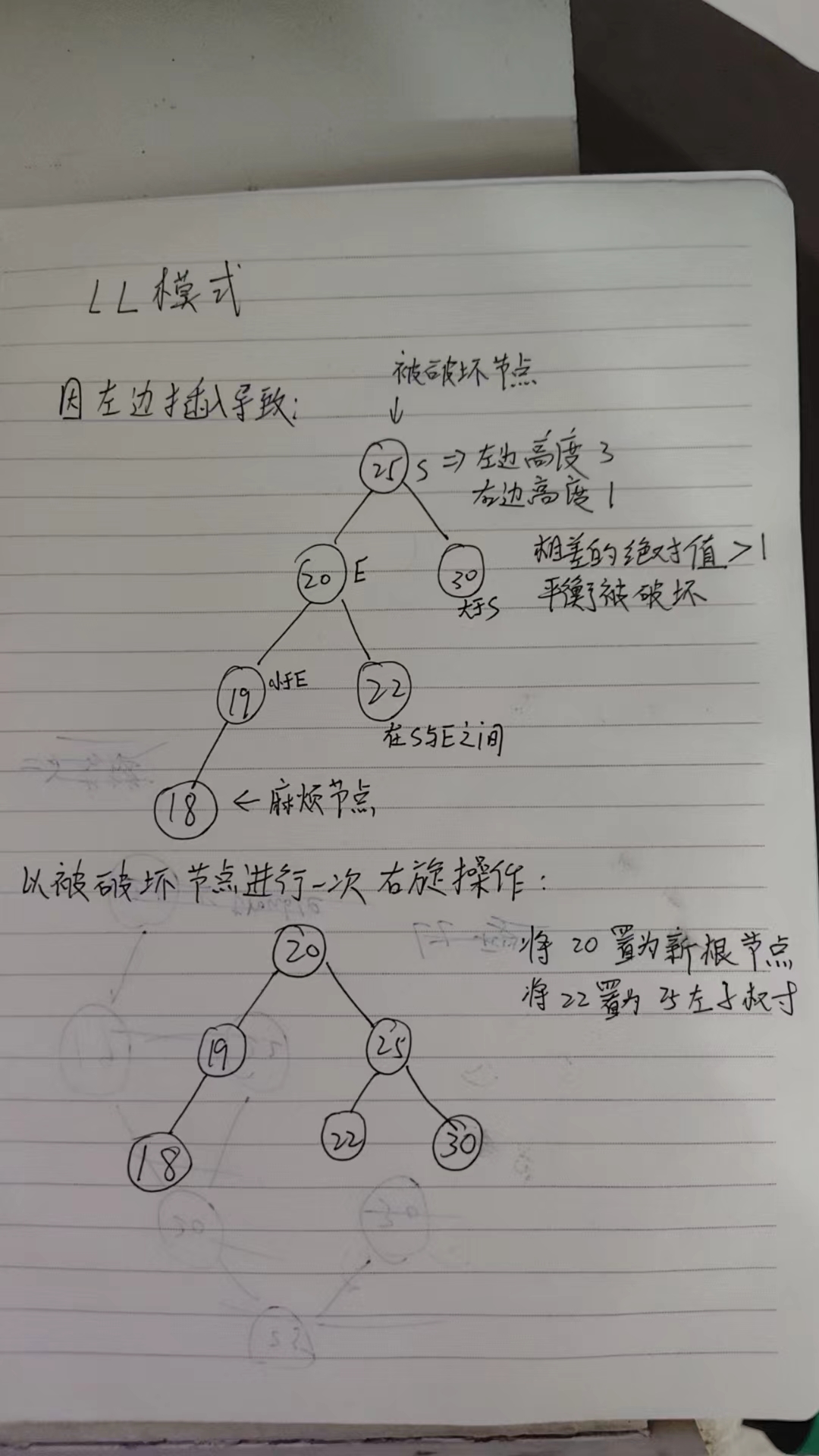
LL(左左):破坏点的左子节点有一个更高的左子树。
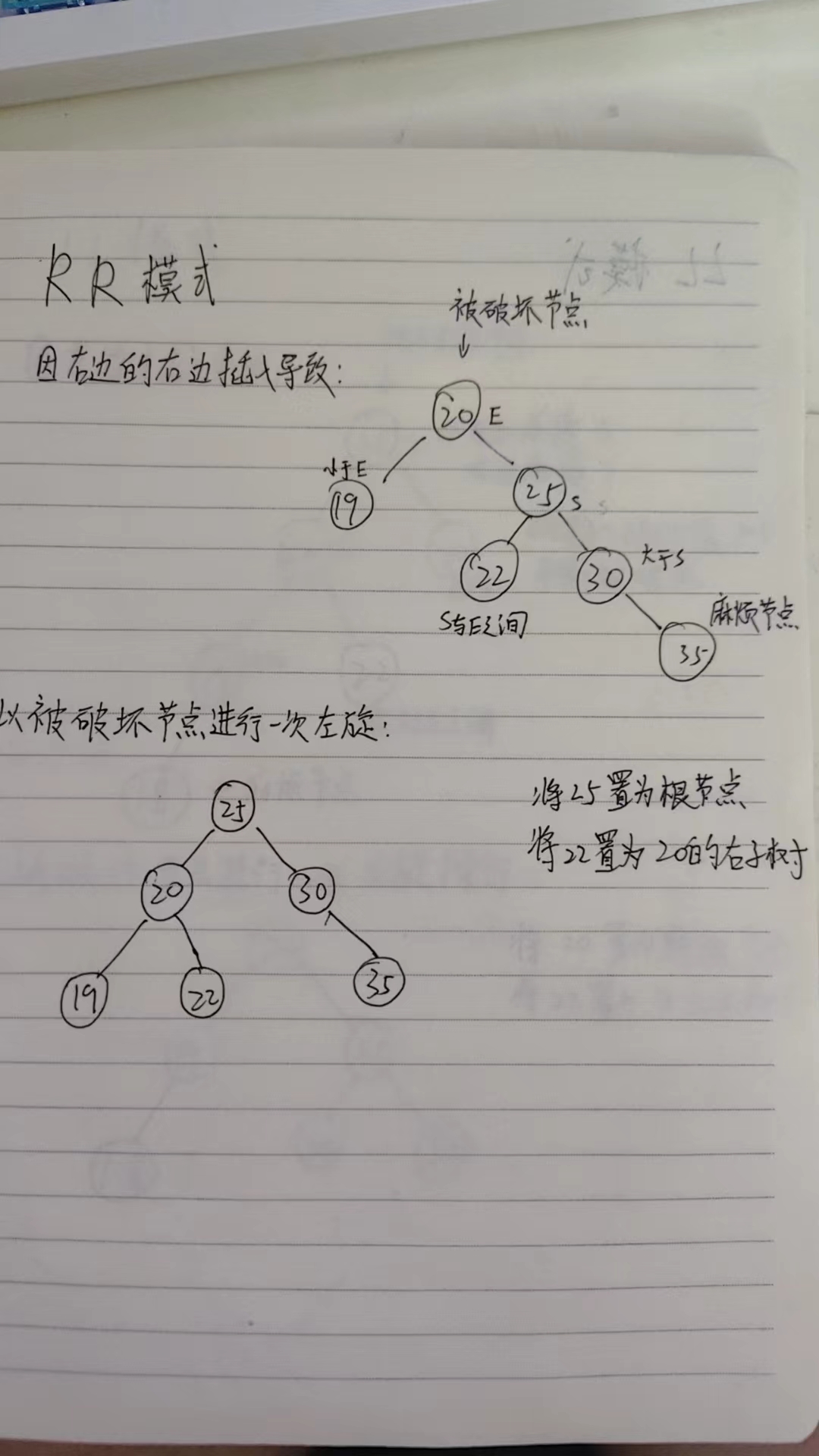
RR(右右):破坏点的右子节点有一个更高的右子树。
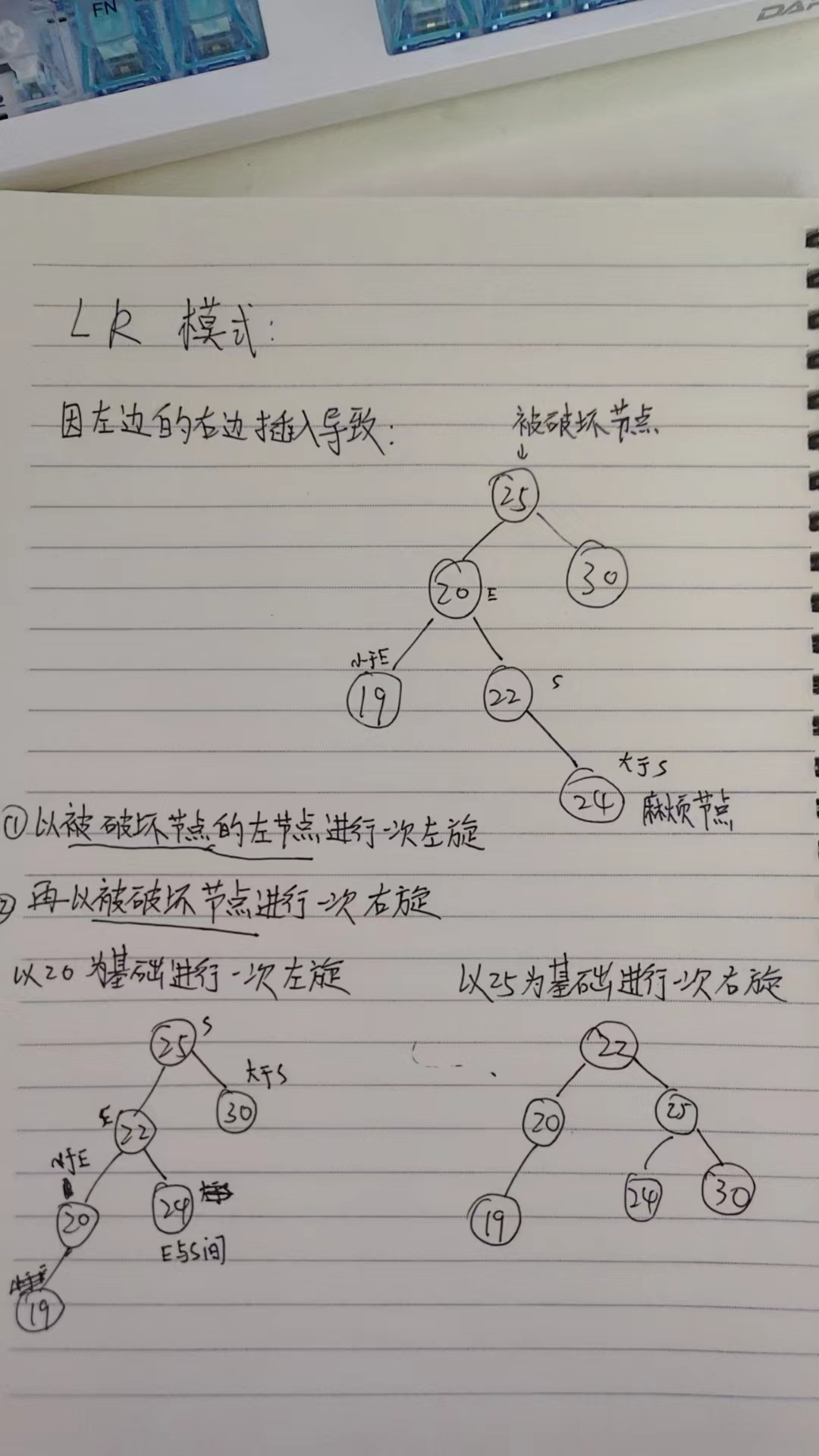
LR(左右):破坏点的左子节点有一个更高的右子树。
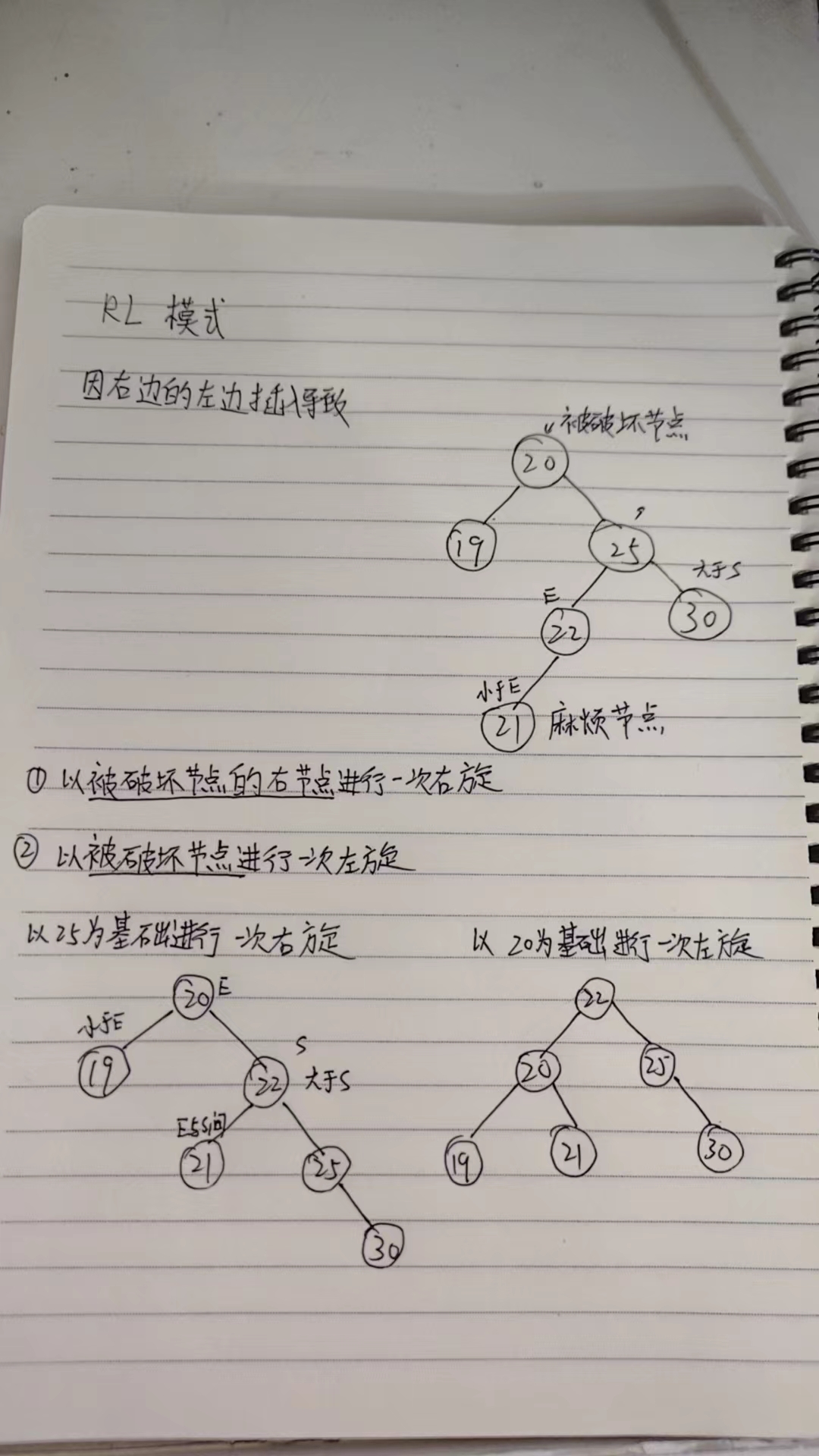
RL(右左):破坏点的右子节点有一个更高的左子树。
旋转操作
单旋转:当破坏模式为 LL 或 RR 时,执行一次旋转即可恢复平衡。
双旋转:当破坏模式为 LR 或 RL 时,首先对破坏点的子节点执行一次旋转,然后对破坏点执行一次旋转。
LL模式的旋转操作
RR模式的旋转操作
LR模式的旋转操作
RL模式的旋转操作
删除的旋转操作
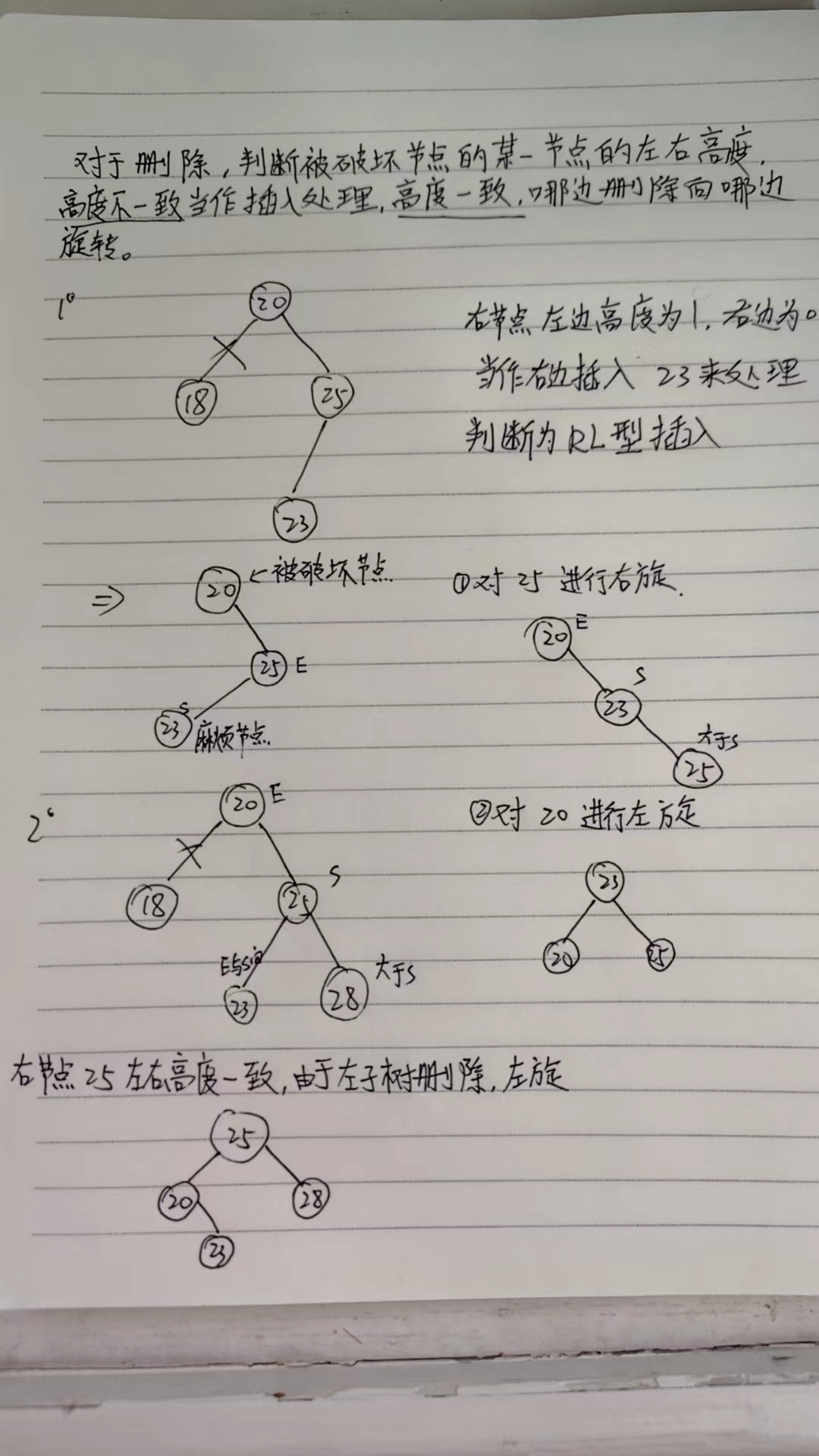
红黑树
红黑树(Red-Black Tree)是一种自平衡的二叉查找树,它通过特定的颜色标记以及旋转和重新着色操作来维持树的近似平衡,从而确保树的高度保持在(O(\log n)),这里(n)是树中节点的数量。这使得红黑树能够高效地执行查找、插入和删除操作。
红黑树的特点
红黑树的每个节点都有一个颜色属性,可以是红色(red)或黑色(black),并且满足以下性质:
节点属性:每个节点要么是红色的,要么是黑色的。
根节点:根节点总是黑色。
叶子节点:所有叶子节点(NIL节点,空节点)都是黑色的。
红色节点:两个红色节点之间不能相邻,即一个红色节点的父节点和子节点必须是黑色。
黑色高度:从任一节点到其每个叶子的所有简单路径上包含相同数量的黑色节点。
插入后恢复平衡的情况
当插入一个新节点后,该节点被标记为红色,并且可能违反红黑树的性质。常见的恢复策略包括:
变色:如果新插入的节点的父节点也是红色,那么需要考虑变色操作(若父节点为黑色则无需自平衡)。如果叔叔节点(父节点的兄弟节点)也是红色,则将父节点和叔叔节点都变为黑色,祖父节点变为红色,然后以祖父节点作为新的起点继续检查(即黑红红改为红黑红)。
旋转:如果叔叔节点是黑色或不存在,则需要进行旋转操作来调整树的结构。具体分为以下几种情况:
左左情况:如果新节点是其父节点的左孩子,而父节点又是其祖父节点的左孩子,则进行一次右旋。
右右情况:如果新节点是其父节点的右孩子,而父节点又是其祖父节点的右孩子,则进行一次左旋。
左右情况:如果新节点是其父节点的右孩子,而父节点是其祖父节点的左孩子,则先对其父节点进行左旋,再对祖父节点进行右旋。
右左情况:如果新节点是其父节点的左孩子,而父节点是其祖父节点的右孩子,则先对其父节点进行右旋,再对祖父节点进行左旋。
删除后的恢复平衡
删除节点后,可能需要调整树的结构来恢复红黑树的性质。主要关注的是删除操作可能导致的黑色高度减少问题。常见的恢复策略包括:
双黑节点:如果删除了一个黑色节点,并且替换它的节点是红色,则直接将其替换为黑色即可。否则,如果替换节点是黑色,则会产生一个“双黑”节点(即节点和其原本的NIL节点都被视为黑色)。
旋转和变色:为了修复双黑问题,需要考虑以下几个方向:
如果双黑节点的兄弟节点是红色,则可以通过旋转和变色来解决。例如,如果兄弟节点是红色,且兄弟节点的外侧子节点是黑色,则可以先进行一次旋转(左旋或右旋),使兄弟节点成为父节点,然后进行变色。
如果兄弟节点是黑色,且兄弟节点的两个子节点都是黑色,则将兄弟节点变为红色,并继续在其父节点处进行检查。
如果兄弟节点是黑色,且兄弟节点的外侧子节点是红色,则可以先进行一次旋转(左旋或右旋),使兄弟节点成为父节点,然后进行变色。
如果兄弟节点是黑色,且兄弟节点的内侧子节点是红色,则可以先进行一次旋转(左旋或右旋),使兄弟节点成为父节点,然后进行变色。
7.HashMap 的 put 流程
第一步,通过 hash 方法计算 key 的哈希值。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
第二步,数组进行第一次扩容。
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
第三步,根据哈希值计算 key 在数组中的下标,如果对应下标正好没有存放数据,则直接插入。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
如果对应下标已经有数据了,就需要判断是否为相同的 key,是则覆盖 value,否则需要判断是否为树节点,是则向树中插入节点,否则向链表中插入数据。
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
}
注意,在链表中插入节点的时候,如果链表长度大于等于 8,则需要把链表转换为红黑树。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
所有元素处理完后,还需要判断是否超过阈值threshold,超过则扩容。
if (++size > threshold)
resize();
8.只重写 equals 没重写 hashcode,map put 的时候会发生什么?
如果只重写 equals 方法,没有重写 hashcode 方法,那么会导致 equals 相等的两个对象,hashcode 不相等,这样的话,这两个对象会被放到不同的桶中,这样就会导致 get 的时候,找不到对应的值。
当你使用一个键去 Map 中获取对应的值时,Map 会首先使用键的 hashCode 方法来定位可能的位置,然后再调用 equals 方法来确认键是否匹配。
如果你只重写了 equals 方法,那么即使两个键 equals 相等,但它们的 hashCode 不同,Map 将无法找到正确的条目,导致返回 null,即使该键实际上存在于 Map 中。
9.为什么要用高低做异或运算?为什么非得高低 16 位异或?
为什么使用高低位进行异或运算?
提高哈希值的均匀性:
哈希函数的目标是将输入数据映射到一个固定大小的空间中,使得输出尽可能均匀分布。 使用高低位异或运算可以帮助混合高阶位和低阶位的信息,从而提高哈希值的均匀性和随机性。
避免局部相关性:
在许多情况下,输入数据的高阶位和低阶位可能存在一定的相关性。通过异或运算,可以打破这种相关性,使得哈希值更加独立和随机。
增强扩散效果:
异或运算可以将高阶位和低阶位的信息混合在一起,从而增强哈希值的扩散效果。这有助于防止哈希冲突,提高哈希函数的质量。
为什么选择高低 16 位进行异或?
字长的一半:
对于 32 位整数,高低 16 位正好是字长的一半。这样可以充分利用整个字长,同时避免了不必要的复杂性。 选择 16 位是因为 16 是一个合理的中间值,既不是太小也不是太大,可以很好地混合高低位信息。
性能考虑:
16 位的位数适中,可以在性能和效果之间取得良好的平衡。如果位数太少,可能不足以充分混合信息;如果位数太多,可能会增加计算复杂度。
经验选择:
在实际应用中,高低 16 位异或已经被证明是一种有效的哈希函数优化方法。许多成熟的哈希函数(如 Jenkins Hash Function)都采用了这种方法。
10.为什么 HashMap 的容量是 2 的倍数呢?hashCode 对数组长度取模定位数组下标的优化策略?
哈希值计算:
HashMap 使用哈希码来确定元素存储的位置。哈希码通过与数组长度进行取模运算 (%) 来计算出元素在数组中的位置。 当数组长度是 2 的幂次方时,取模运算可以简化为位运算。具体来说,hash % capacity 可以简化为 hash & (capacity - 1)。这是因为当 capacity 是 2 的幂次方时,capacity - 1 将会是一个二进制数,其低位全部为 1,高位为 0。因此,hash & (capacity - 1) 实际上是保留了 hash 的低位部分,这比传统的取模运算更快。
减少哈希碰撞:
如果 HashMap 的容量是 2 的幂次方,那么哈希值的分布会更加均匀,从而减少了哈希碰撞的概率。这是因为位运算的结果依赖于哈希值的低位,如果低位分布均匀,则可以更好地分散元素,减少碰撞。
扩容时的重新哈希:
当 HashMap 的容量需要扩展时,如果新的容量仍然是 2 的幂次方,那么重新哈希的过程也会更加均匀。这是因为新的容量与旧的容量之间存在倍数关系,可以使得元素在新的数组中重新分布,减少由于扩容带来的碰撞。
硬件优化:
在现代计算机体系结构中,位运算通常比算术运算(如除法和取模)更快。因此,使用位运算来替代取模运算可以带来性能上的优势。
11.map 集合在使用时候一般都需要写容量值?为什么要写?扩容机制?
在使用 Java 中的 HashMap 时,通常会在创建 HashMap 实例时指定初始容量。这是因为 HashMap 的性能很大程度上取决于它的容量大小。指定合适的初始容量可以帮助避免不必要的扩容操作,从而提高程序的性能。
为什么需要指定容量
-
减少扩容次数:当 HashMap 的容量达到阈值时,会触发一次扩容操作。如果 HashMap 的容量过大,那么每次扩容都需要重新计算哈希值,这可能会导致不必要的性能开销。通过指定合适的初始容量,可以减少扩容操作的次数,提高 HashMap 的性能。
-
减少哈希碰撞:如果 HashMap 的容量过小,可能会导致哈希碰撞(即两个不同的键计算出相同的哈希值)。这会导致在 HashMap 中存在多个键映射到同一个位置,从而导致查找和插入操作的时间复杂度提高。通过指定合适的初始容量,可以减少哈希碰撞,提高 HashMap 的性能。
-
减少内存占用:当 HashMap 的容量过大时,可能会导致 HashMap 的内存占用过多。通过指定合适的初始容量,可以减少 HashMap 的内存占用,提高 HashMap 的性能。
扩容机制
HashMap 的默认初始容量是 16,而且容量总是 2 的幂次方。当 HashMap 中的元素数量超过了当前容量与加载因子(默认为 0.75)的乘积时,就会触发扩容操作。扩容时,HashMap 会创建一个新的数组,其容量通常是原来的两倍,并将原有数组中的所有元素重新散列并放入新的数组中。
12.红黑树转回链表的阈值为什么默认是6而不是8?
因为如果这个阈值也设置成 8,假如发生碰撞,节点增减刚好在 8 附近,会发生链表和红黑树的不断转换,导致资源浪费。
13.JDK8对HashMap的实现原理做了哪些优化?
- 底层数据结构由数组 + 链表改成了数组 + 链表或红黑树的结构。
原因:如果多个键映射到了同一个哈希值,链表会变得很长,在最坏的情况下,当所有的键都映射到同一个桶中时,性能会退化到 O(n),而红黑树的时间复杂度是 O(logn)。
2.链表的插入方式由头插法改为了尾插法。
原因:头插法虽然简单快捷,但扩容后容易改变原来链表的顺序。
3.扩容的时机由插入时判断改为插入后判断。
原因:可以避免在每次插入时都进行不必要的扩容检查,因为有可能插入后仍然不需要扩容。
4.优化了哈希算法
JDK 7 进行了多次移位和异或操作来计算元素的哈希值。JDK 8 优化了这个算法,只进行了一次异或操作,但仍然能有效地减少冲突。并且能够保证扩容后,元素的新位置要么是原位置,要么是原位置加上旧容量大小。
14.HashMap和TreeMap的区别?
1.HashMap 是基于数组+链表+红黑树实现的,put 元素的时候会先计算 key 的哈希值,然后通过哈希值计算出数组的索引,然后将元素插入到数组中,如果发生哈希冲突,会使用链表来解决,如果链表长度大于 8,会转换为红黑树。
get 元素的时候同样会先计算 key 的哈希值,然后通过哈希值计算出数组的索引,如果遇到链表或者红黑树,会通过 key 的 equals 方法来判断是否是要找的元素。
2.TreeMap 是基于红黑树实现的,put 元素的时候会先判断根节点是否为空,如果为空,直接插入到根节点,如果不为空,会通过 key 的比较器来判断元素应该插入到左子树还是右子树。
get 元素的时候会通过 key 的比较器来判断元素的位置,然后递归查找。
由于 HashMap 是基于哈希表实现的,所以在没有发生哈希冲突的情况下,HashMap 的查找效率是 O(1)。适用于查找操作比较频繁的场景。
而 TreeMap 是基于红黑树实现的,所以 TreeMap 的查找效率是 O(logn)。并且保证了元素的顺序,因此适用于需要大量范围查找或者有序遍历的场景。
Java并发编程
1.你对线程安全的理解是什么?
线程安全是并发编程中一个重要的概念,如果一段代码块或者一个方法在多线程环境中被多个线程同时执行时能够正确地处理共享数据,那么这段代码块或者方法就是线程安全的。
可以从三个要素来确保线程安全:
①、原子性:确保当某个线程修改共享变量时,没有其他线程可以同时修改这个变量,即这个操作是不可分割的。
②、可见性:确保一个线程对共享变量的修改可以立即被其他线程看到。
③、活跃性问题:要确保线程不会因为死锁、饥饿、活锁等问题导致无法继续执行。
2.线程和进程的区别?
定义
进程:进程是操作系统中程序的一次执行实例,它是系统进行资源分配和调度的基本单位。每个进程都有独立的地址空间和其他资源(如文件句柄、环境变量等)。
线程:线程是进程内的一个执行流,它是处理器调度和分派的基本单位。同一进程内的线程共享该进程的地址空间和资源。
资源占用
进程拥有独立的内存空间,因此每个进程都有自己的数据段、堆栈段和代码段等,这意味着进程间的资源是隔离的。
线程共享所属进程的数据段、堆栈段和代码段等资源,因此创建线程比创建进程消耗更少的资源。
上下文切换开销
进程间的上下文切换涉及到更多的资源转移和保护,因此开销较大。
线程间的上下文切换仅需保存和恢复少量寄存器值及栈指针,因此开销较小。
通信方式
进程间通信(IPC)通常需要通过操作系统提供的机制来实现,如管道、消息队列、共享内存等,这增加了通信的复杂度。
线程可以直接访问同一进程内的全局变量或数据结构,因此线程间的通信更为简单直接。
生命周期管理
进程的创建和销毁涉及更多资源的初始化和清理工作,因此相对于线程来说更加耗时。
线程的生命周期管理较为轻量级,创建和销毁速度快。
依赖关系
线程依赖于进程的存在,没有进程就没有线程。进程是独立的执行环境,可以不依赖其他进程单独存在。
3.线程共享内存和进程共享内存的区别?
进程共享内存
共享范围
不同进程之间默认情况下是不共享内存的,每个进程都有自己的独立地址空间。进程间的内存共享需要通过特定的技术手段实现,例如通过共享内存段、映射文件等方式。
通信复杂度
进程间通信(IPC)通常需要通过操作系统提供的机制来实现,如管道、消息队列、共享内存、套接字等。这些机制比线程间的直接内存访问要复杂得多。
数据一致性
由于进程间通信需要通过特定的通道进行,因此在设计上更容易实现数据的一致性和安全性。
资源开销
创建进程的资源开销相对较大,因为每个进程都需要自己的虚拟地址空间和系统资源(如文件句柄、环境变量等)。
线程共享内存
共享范围
同一进程内的所有线程共享该进程的整个地址空间,包括代码段、数据段、堆和栈等。
通信复杂度
线程之间的通信非常简单,因为它们可以直接访问同一进程内的全局变量或其他数据结构,无需复杂的同步机制。
数据一致性
虽然共享内存简化了线程间的通信,但也带来了数据一致性和同步的问题,需要通过锁机制(如互斥锁、信号量等)来保证数据访问的原子性和一致性。
资源开销
创建线程的资源开销相对较小,因为不需要额外的内存空间分配,只需为每个线程维护一个栈和一些控制信息即可。
4.有多少种实现线程的方式?
继承Thread类
class ThreadTask extends Thread {
public void run() {
System.out.println("继承Thread类");
}
public static void main(String[] args) {
ThreadTask task = new ThreadTask();
task.start();
}
}
直接继承Thread类,并重写其run方法。这种方式简单直观,但因为Java不支持多重继承,所以如果需要继承其他类,则不能使用这种方法。
实现Runnable接口
class RunnableTask implements Runnable {
public void run() {
System.out.println("实现Runnable接口");
}
public static void main(String[] args) {
RunnableTask task = new RunnableTask();
Thread thread = new Thread(task);
thread.start();
}
}
实现Runnable接口并重写run方法,然后将这个对象传递给Thread类的构造函数创建线程。这种方式更灵活,因为它允许类继承其他类的同时实现多线程功能。
实现Callable接口配合FutureTask使用
class CallableTask implements Callable<String> {
public String call() {
return "实现Callable接口";
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
CallableTask task = new CallableTask();
FutureTask<String> futureTask = new FutureTask<>(task);
Thread thread = new Thread(futureTask);
thread.start();
System.out.println(futureTask.get());
}
}
Callable接口类似于Runnable,不同之处在于Callable的call方法可以返回结果,并且可以抛出异常。通过FutureTask包装Callable对象,然后将其传递给Thread类创建线程。这种方式适合需要返回结果的任务。
使用Executor框架和线程池
5.为什么在项目中使用线程池?
1、频繁地创建和销毁线程会消耗系统资源,线程池能够复用已创建的线程。
2、提高响应速度,当任务到达时,任务可以不需要等待线程创建就立即执行。
3、线程池支持定时执行、周期性执行、单线程执行和并发数控制等功能。
6.讲一讲你对线程池的理解,并讲一讲使用的场景
线程池的概念
线程池是一种管理线程的技术,它预先创建一组线程,并将它们组织在一起,以便能够高效地处理多个任务。线程池的核心思想是复用已创建的线程,而不是每次任务到来时都创建新的线程。
线程池的基本组成
核心线程数(Core Pool Size):线程池中始终维持的最小线程数。
最大线程数(Maximum Pool Size):线程池中允许的最大线程数。
工作队列(Work Queue):用来存储等待执行的任务。
拒绝策略(Rejection Policy):当线程池无法接收更多任务时采取的策略。
线程工厂(Thread Factory):用于创建新线程的对象。
Java中线程池的主要参数
①、corePoolSize
定义了线程池中的核心线程数量。即使这些线程处于空闲状态,它们也不会被回收。这是线程池保持在等待状态下的线程数。
②、maximumPoolSize
线程池允许的最大线程数量。当工作队列满了之后,线程池会创建新线程来处理任务,直到线程数达到这个最大值。
③、keepAliveTime
非核心线程的空闲存活时间。如果线程池中的线程数量超过了 corePoolSize,那么这些多余的线程在空闲时间超过 keepAliveTime 时会被终止。
④、unit
keepAliveTime 参数的时间单位:
TimeUnit.DAYS; 天 TimeUnit.HOURS; 小时 TimeUnit.MINUTES; 分钟 TimeUnit.SECONDS; 秒 TimeUnit.MILLISECONDS; 毫秒 TimeUnit.MICROSECONDS; 微秒 TimeUnit.NANOSECONDS; 纳秒 ⑤、workQueue
用于存放待处理任务的阻塞队列。当所有核心线程都忙时,新任务会被放在这个队列里等待执行。
⑥、threadFactory
一个创建新线程的工厂。它用于创建线程池中的线程。可以通过自定义 ThreadFactory 来给线程池中的线程设置有意义的名字,或设置优先级等。
⑦、handler
拒绝策略 RejectedExecutionHandler,定义了当线程池和工作队列都满了之后对新提交的任务的处理策略。常见的拒绝策略包括抛出异常、直接丢弃、丢弃队列中最老的任务、由提交任务的线程来直接执行任务等。
线程池的工作流程
1.任务提交:当一个任务提交到线程池时,线程池会尝试分配一个线程来执行该任务。
2.核心线程数:如果当前活动线程少于核心线程数,即使有空闲线程,也会创建新的线程来执行任务。
3.工作队列:如果当前活动线程等于核心线程数,但还有任务需要执行,那么这些任务会被放入工作队列中等待执行。
4.最大线程数:如果工作队列已满,线程池会尝试创建新的线程,直到达到最大线程数。
5.拒绝策略:如果线程池已经达到最大线程数且工作队列已满,线程池将根据拒绝策略处理新任务。
线程池的拒绝策略
AbortPolicy:
这是默认的拒绝策略。当线程池无法接受新任务时,它会抛出一个RejectedExecutionException异常。这通常意味着应用程序需要处理这个异常,并可能需要采取补救措施,比如记录日志或者通知管理员。
CallerRunsPolicy:
当线程池无法接受新任务时,这个策略会让调用者所在的线程来运行这个任务。如果调用者的线程本身已经在执行其他任务,那么可能会导致调用者线程的阻塞。这种策略适合于并发度不高、性能要求不是特别高的场景。
DiscardPolicy:
当线程池无法接受新任务时,这个策略会直接丢弃任务而不执行它,也不会抛出异常。这种策略适用于那些可以容忍任务丢失的场景。
DiscardOldestPolicy:
当线程池无法接受新任务时,这个策略会首先丢弃队列中最旧的任务,然后尝试再次提交新任务。这种策略有助于优先处理最新的任务,但可能导致某些任务永远无法被执行。
自定义拒绝策略
除了这些内置的拒绝策略之外,还可以通过实现RejectedExecutionHandler接口来自定义拒绝策略,以适应特定的应用需求。
线程池的阻塞队列
ArrayBlockingQueue:
一个由数组结构组成的有界阻塞队列。
按照先进先出(FIFO)排序元素。
是LinkedBlockingQueue的一个替代品,当需要一个容量固定的队列时使用。
LinkedBlockingQueue:
一个基于链表结构的阻塞队列,吞吐量通常要高于ArrayBlockingQueue。
默认情况下是无界的,但是可以通过构造函数指定队列长度。
适用于需要一个具有较高吞吐量的无界或有限阻塞队列的情况
PriorityBlockingQueue:
一个具有优先级的无界阻塞队列。
支持优先级排序的功能,可以按照优先级来决定哪个任务先被执行。
适用于需要根据任务优先级来调度执行的任务队列。
DelayQueue:
一个使用Delayed元素的无界阻塞队列。
队列中的元素只有在其延迟过期后才能被消费者线程获取。
适用于需要延迟执行的任务。
SynchronousQueue:
一个不存储元素的阻塞队列。
每个插入操作必须等待另一个线程的相应移除操作,反之亦然。
适用于传递元素,而不是存储元素的情况,通常用于实现生产者-消费者模型。
线程池的提交
execute(Runnable command)
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolExample {
public static void main(String[] args) {
// 创建线程池
ExecutorService executor = Executors.newFixedThreadPool(5);
// 提交任务
for (int i = 0; i < 10; i++) {
int taskId = i;
executor.execute(() -> {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
// 关闭线程池
executor.shutdown();
try {
if (!executor.awaitTermination(1, TimeUnit.MINUTES)) {
executor.shutdownNow();
}
} catch (InterruptedException e) {
executor.shutdownNow();
Thread.currentThread().interrupt();
}
}
}
}
execute方法用于提交一个Runnable任务,是最基本的提交方式。它没有返回值,也不支持获取任务执行结果。
submit(Runnable task)
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class ThreadPoolExample {
public static void main(String[] args) {
// 创建线程池
ExecutorService executor = Executors.newFixedThreadPool(5);
// 提交任务
for (int i = 0; i < 10; i++) {
int taskId = i;
Future<?> future = executor.submit(() -> {
System.out.println("Task " + taskId + " is running on thread " + Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
// 关闭线程池
executor.shutdown();
try {
if (!executor.awaitTermination(1, TimeUnit.MINUTES)) {
executor.shutdownNow();
}
} catch (InterruptedException e) {
executor.shutdownNow();
Thread.currentThread().interrupt();
}
}
}
}
submit方法用于提交一个Runnable任务,并返回一个Future对象,可以用来获取任务的执行状态和结果。
线程池的关闭
可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的 interrupt 方法来中断线程,所以无法响应中断的任务可能永远无法终止。
shutdown() 将线程池状态置为 shutdown,并不会立即停止:
停止接收外部 submit 的任务 内部正在跑的任务和队列里等待的任务,会执行完 等到第二步完成后,才真正停止
shutdownNow() 将线程池状态置为 stop。一般会立即停止,事实上不一定:
和 shutdown()一样,先停止接收外部提交的任务 忽略队列里等待的任务 尝试将正在跑的任务 interrupt 中断 返回未执行的任务列表
shutdown 和 shutdownnow 简单来说区别如下:
shutdownNow()能立即停止线程池,正在跑的和正在等待的任务都停下了。这样做立即生效,但是风险也比较大。
shutdown()只是关闭了提交通道,用 submit()是无效的;而内部的任务该怎么跑还是怎么跑,跑完再彻底停止线程池。
线程池的线程数配置
①、对于 CPU 密集型任务,我的目标是尽量减少线程上下文切换,以优化 CPU 使用率。一般来说,核心线程数设置为处理器的核心数或核心数加一(以备不时之需,如某些线程因等待系统资源而阻塞时)是较理想的选择。
②、对于 IO 密集型任务,由于线程经常处于等待状态(等待 IO 操作完成),可以设置更多的线程来提高并发性(比如说 2 倍),从而增加 CPU 利用率。
线程池的种类
newFixedThreadPool (固定线程数目的线程池)
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
线程池特点
核心线程数和最大线程数大小一样
没有所谓的非空闲时间,即 keepAliveTime 为 0
阻塞队列为无界队列 LinkedBlockingQueue,可能会导致 OOM
工作流程
提交任务
如果线程数少于核心线程,创建核心线程执行任务
如果线程数等于核心线程,把任务添加到 LinkedBlockingQueue 阻塞队列
如果线程执行完任务,去阻塞队列取任务,继续执行。
适用场景
FixedThreadPool 适用于处理 CPU 密集型的任务,确保 CPU 在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。
newCachedThreadPool (可缓存线程的线程池)
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
线程池特点
核心线程数为 0
最大线程数为 Integer.MAX_VALUE,即无限大,可能会因为无限创建线程,导致 OOM
阻塞队列是 SynchronousQueue
非核心线程空闲存活时间为 60 秒
当提交任务的速度大于处理任务的速度时,每次提交一个任务,就必然会创建一个线程。极端情况下会创建过多的线程,耗尽 CPU 和内存资源。由于空闲 60 秒的线程会被终止,长时间保持空闲的 CachedThreadPool 不会占用任何资源。
工作流程
提交任务
因为没有核心线程,所以任务直接加到 SynchronousQueue 队列。
判断是否有空闲线程,如果有,就去取出任务执行。
如果没有空闲线程,就新建一个线程执行。
执行完任务的线程,还可以存活 60 秒,如果在这期间,接到任务,可以继续活下去;否则,被销毁。
适用场景
用于并发执行大量短期的小任务。
newSingleThreadExecutor (单线程的线程池)
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
线程池特点
核心线程数为 1
最大线程数也为 1
阻塞队列是无界队列 LinkedBlockingQueue,可能会导致 OOM
keepAliveTime 为 0
工作流程
提交任务
线程池是否有一条线程在,如果没有,新建线程执行任务
如果有,将任务加到阻塞队列
当前的唯一线程,从队列取任务,执行完一个,再继续取,一个线程执行任务。
适用场景
适用于串行执行任务的场景,一个任务一个任务地执行。
newScheduledThreadPool (定时及周期执行的线程池)
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
线程池特点
最大线程数为 Integer.MAX_VALUE,也有 OOM 的风险
阻塞队列是 DelayedWorkQueue
keepAliveTime 为 0
scheduleAtFixedRate() :按某种速率周期执行
scheduleWithFixedDelay():在某个延迟后执行
工作机制
线程从 DelayQueue 中获取已到期的 ScheduledFutureTask(DelayQueue.take())。到期任务是指 ScheduledFutureTask 的 time 大于等于当前时间。
线程执行这个 ScheduledFutureTask。
线程修改 ScheduledFutureTask 的 time 变量为下次将要被执行的时间。
线程把这个修改 time 之后的 ScheduledFutureTask 放回 DelayQueue 中(DelayQueue.add())。
适用场景
周期性执行任务的场景,需要限制线程数量的场景
线程池异常处理
1.try-catch 捕获异常
2.submit执行,Feture.get接受异常
3.重写ThreadPoolExecutor.afterExecute方法,处理传递的异常引用
4.实例化时,传入自己的ThreadFactory,设置Thread.UncaughtExceptionHandler处理未检测的异常
线程池的状态
ThreadPoolExecutor 类使用一个名为 ctl 的原子变量来存储线程池的状态信息。这个变量是一个 long 类型的值,其中一部分位用于表示线程池的状态,另一部分位用于表示线程池中的活动线程数。ctl 变量的低三位用于表示线程池的状态,共有四种状态:
RUNNING
该状态的线程池会接收新任务,并处理阻塞队列中的任务;
调用线程池的 shutdown()方法,可以切换到 SHUTDOWN 状态;
调用线程池的 shutdownNow()方法,可以切换到 STOP 状态;
这是线程池的初始状态
SHUTDOWN
该状态的线程池不会接收新任务,但会处理阻塞队列中的任务;
队列为空,并且线程池中执行的任务也为空,进入 TIDYING 状态;
STOP
该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行的任务;
线程池中执行的任务为空,进入 TIDYING 状态;
TIDYING
该状态表明所有的任务已经运行终止,记录的任务数量为 0。
terminated()执行完毕,进入 TERMINATED 状态
当最后一个任务完成后,线程池会进入 TIDYING 状态。
TERMINATED
线程池已经完成所有清理工作,处于终止状态。
线程池对参数的动态修改
在我们微服务的架构下,可以利用配置中心如 Nacos、Apollo 等等,也可以自己开发配置中心。业务服务读取线程池配置,获取相应的线程池实例来修改线程池的参数。
如果限制了配置中心的使用,也可以自己去扩展ThreadPoolExecutor,重写方法,监听线程池参数变化,来动态修改线程池参数。
7. 线程池在使用时需要注意什么?
①、选择合适的线程池大小
过小的线程池可能会导致任务一直在排队
过大的线程池可能会导致大家都在竞争 CPU 资源,增加上下文切换的开销
可以根据业务是 IO 密集型还是 CPU 密集型来选择线程池大小:
CPU 密集型:指的是任务主要使用来进行大量的计算,没有什么导致线程阻塞。一般这种场景的线程数设置为 CPU 核心数+1。
IO 密集型:当执行任务需要大量的 io,比如磁盘 io,网络 io,可能会存在大量的阻塞,所以在 IO 密集型任务中使用多线程可以大大地加速任务的处理。一般线程数设置为 2*CPU 核心数。
②、任务队列的选择
使用有界队列可以避免资源耗尽的风险,但是可能会导致任务被拒绝
使用无界队列虽然可以避免任务被拒绝,但是可能会导致内存耗尽
一般需要设置有界队列的大小,比如 LinkedBlockingQueue 在构造的时候可以传入参数来限制队列中任务数据的大小,这样就不会因为无限往队列中扔任务导致系统的 oom。
③、尽量使用自定义的线程池,而不是使用 Executors 创建的线程池,因为 newFixedThreadPool 线程池由于使用了 LinkedBlockingQueue,队列的容量默认无限大,实际使用中出现任务过多时会导致内存溢出;
newCachedThreadPool 线程池由于核心线程数无限大,当任务过多的时候会导致创建大量的线程,可能机器负载过高导致服务宕机。
8.你能设计并实现一个线程池吗?
核心流程:
线程池中有 N 个工作线程
把任务提交给线程池运行
如果线程池已满,把任务放入队列
最后当有空闲时,获取队列中任务来执行
代码示例:
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
public class SimpleThreadPool {
private final BlockingQueue<Runnable> workQueue;
private final int corePoolSize;
private final int maximumPoolSize;
private final long keepAliveTime;
private final TimeUnit unit;
private volatile boolean isShutdown = false;
private final AtomicInteger activeThreads = new AtomicInteger(0);
private final ThreadFactory threadFactory;
public SimpleThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, ThreadFactory threadFactory) {
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.keepAliveTime = keepAliveTime;
this.unit = unit;
this.threadFactory = threadFactory;
this.workQueue = new LinkedBlockingQueue<>();
}
public void execute(Runnable command) {
if (isShutdown) {
throw new IllegalStateException("Executor has been shutdown");
}
// 尝试将任务放入队列
if (workQueue.offer(command)) {
addWorker();
} else {
// 队列已满,尝试创建新线程
startWorker(command);
}
}
private void addWorker() {
if (activeThreads.get() < corePoolSize) {
startWorker(null);
}
}
private void startWorker(Runnable firstTask) {
Thread worker = threadFactory.newThread(new Worker(firstTask));
worker.start();
}
private class Worker implements Runnable {
private Runnable currentTask;
public Worker(Runnable firstTask) {
this.currentTask = firstTask;
}
@Override
public void run() {
if (currentTask != null) {
try {
currentTask.run();
} finally {
currentTask = null;
}
}
while (!isShutdown) {
try {
currentTask = workQueue.take();
currentTask.run();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
} catch (RuntimeException e) {
// 处理异常
handleException(e);
}
}
activeThreads.decrementAndGet();
}
}
private void handleException(RuntimeException e) {
System.err.println("Caught exception: " + e.getMessage());
e.printStackTrace();
}
public void shutdown() {
isShutdown = true;
// 中断所有空闲线程
interruptIdleWorkers();
}
private void interruptIdleWorkers() {
for (int i = 0; i < activeThreads.get(); i++) {
Thread worker = new Thread(() -> {});
worker.interrupt();
}
}
public static void main(String[] args) {
SimpleThreadPool executor = new SimpleThreadPool(5, 10, 60, TimeUnit.SECONDS, new CustomThreadFactory("MyThread"));
for (int i = 0; i < 20; i++) {
int taskId = i;
executor.execute(() -> {
System.out.println("Processing task " + taskId);
try {
Thread.sleep(1000); // 模拟任务执行时间
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
System.out.println("Task interrupted");
}
});
}
// 关闭线程池
executor.shutdown();
}
}
class CustomThreadFactory implements ThreadFactory {
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
public CustomThreadFactory(String namePrefix) {
this.namePrefix = namePrefix;
}
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r, namePrefix + threadNumber.getAndIncrement());
t.setUncaughtExceptionHandler((thread, throwable) -> {
System.out.println("Caught exception in thread " + thread.getName() + ": " + throwable.getMessage());
throwable.printStackTrace();
});
return t;
}
}
9.调用 start()方法时会执行 run()方法,那怎么不直接调用 run()方法?
在 Java 中,start() 方法用于启动一个线程,而 run() 方法则用于执行线程的任务。当你调用 start() 方法时,它将启动一个新的线程,并使其运行 run() 方法。
如果直接调用run()方法,那么run()方法就在当前线程中运行,没有新的线程被创建,也就没有实现多线程的效果。
start() 方法的调用会告诉 JVM 准备好所有必要的新线程结构,分配其所需资源,并调用线程的 run() 方法在这个新线程中执行。
10.线程有哪些常用的调度方法?
线程的等待与通知:
①、wait():当一个线程 A 调用一个共享变量的 wait() 方法时,线程 A 会被阻塞挂起,直到发生下面几种情况才会返回 :
线程 B 调用了共享对象 notify()或者 notifyAll() 方法; 其他线程调用了线程 A 的 interrupt() 方法,线程 A 抛出 InterruptedException 异常返回。
②、wait(long timeout) :这个方法相比 wait() 方法多了一个超时参数,它的不同之处在于,如果线程 A 调用共享对象的 wait(long timeout)方法后,没有在指定的 timeout 时间内被其它线程唤醒,那么这个方法还是会因为超时而返回。
③、wait(long timeout, int nanos),其内部调用的是 wait(long timout) 方法。
唤醒线程主要有下面两个方法:
①、notify():一个线程 A 调用共享对象的 notify() 方法后,会唤醒一个在这个共享变量上调用 wait 系列方法后被挂起的线程。
一个共享变量上可能会有多个线程在等待,具体唤醒哪个等待的线程是随机的。
②、notifyAll():不同于在共享变量上调用 notify() 方法会唤醒被阻塞到该共享变量上的一个线程,notifyAll 方法会唤醒所有在该共享变量上调用 wait 系列方法而被挂起的线程。
Thread 类还提供了一个 join() 方法,意思是如果一个线程 A 执行了 thread.join(),当前线程 A 会等待 thread 线程终止之后才从 thread.join() 返回。
线程休眠
sleep(long millis):Thread 类中的静态方法,当一个执行中的线程 A 调用了 Thread 的 sleep 方法后,线程 A 会暂时让出指定时间的执行权。
但是线程 A 所拥有的监视器资源,比如锁,还是持有不让出的。指定的睡眠时间到了后该方法会正常返回,接着参与 CPU 的调度,获取到 CPU 资源后就可以继续运行。
让出优先权
yield():Thread 类中的静态方法,当一个线程调用 yield 方法时,实际是在暗示线程调度器,当前线程请求让出自己的 CPU,但是线程调度器可能会“装看不见”忽略这个暗示。
线程中断
Java 中的线程中断是一种线程间的协作模式,通过设置线程的中断标志并不能直接终止该线程的执行。被中断的线程会根据中断状态自行处理。
void interrupt() 方法:中断线程,例如,当线程 A 运行时,线程 B 可以调用线程 interrupt() 方法来设置线程的中断标志为 true 并立即返回。设置标志仅仅是设置标志, 线程 B 实际并没有被中断,会继续往下执行。
boolean isInterrupted() 方法: 检测当前线程是否被中断。
boolean interrupted() 方法: 检测当前线程是否被中断,与 isInterrupted 不同的是,该方法如果发现当前线程被中断,则会清除中断标志。
为了响应中断,线程的执行代码应该这样编写:
public void run() {
try {
while (!Thread.currentThread().isInterrupted()) {
// 执行任务
}
} catch (InterruptedException e) {
// 线程被中断时的清理代码
} finally {
// 线程结束前的清理代码
}
}
stop 方法用来强制线程停止执行,目前已经处于废弃状态,因为 stop 方法会导致线程立即停止,可能会在不一致的状态下释放锁,破坏对象的一致性,导致难以发现的错误和资源泄漏。
11.线程的生命周期和状态?
新建状态(New):
当创建一个新的线程对象时,线程处于新建状态。此时,JVM已经为线程分配了内存,但尚未开始执行线程。
就绪状态(Runnable):
当调用线程对象的 start() 方法后,线程进入就绪状态。这意味着线程已经准备好被执行,但是还没有被调度器选中占用CPU时间。处于就绪状态的线程被放入可运行池中等待CPU时间片。
运行状态(Running):
当就绪状态的线程被调度器选中并分配了CPU时间片后,线程开始执行其 run() 方法内的代码。此时线程处于运行状态。
阻塞状态(Blocked):
线程由于某些原因暂时停止运行,比如等待I/O操作完成、等待用户输入、等待锁的获取等。阻塞状态下的线程不会占用CPU时间片,只有当阻塞原因解除后,线程才能重新进入就绪状态。
等待状态(Waiting):
线程调用了 Object.wait() 方法或者其他会导致线程等待的方法时,线程会进入等待状态。在此状态下,线程会释放持有的锁,并等待其他线程的通知(通过 notify() 或 notifyAll() 方法)才能继续执行。
定时等待状态(Timed Waiting):
当线程调用了一些具有指定等待时间的方法,如 Thread.sleep()、Object.wait(long timeout) 或 Thread.join(long millis) 时,线程会进入定时等待状态。在指定的时间过后,线程会自动恢复到就绪状态。
死亡状态(Terminated):
当线程执行完毕或因异常退出了 run() 方法后,线程结束其生命周期,进入死亡状态。此时线程不再执行任何操作,也不会被再次调度。
12.什么是线程的上下文切换?
线程的上下文切换是指操作系统在多线程环境中,为了实现线程间的切换而进行的一系列操作。具体来说,当操作系统需要从一个线程切换到另一个线程时,它需要保存当前线程的状态(即上下文信息),然后加载另一个线程的状态,使得后者可以在CPU上继续执行。这个过程称为上下文切换。
上下文切换的过程主要包括以下几个步骤:
保存当前线程的上下文:
记录当前线程的CPU寄存器值(如程序计数器、状态寄存器等)。
保存当前线程的程序状态(如堆栈指针、栈顶指针等)。
更新当前线程的状态信息(如将其标记为就绪或等待状态)。
选择新的线程:
操作系统从就绪队列中选择一个线程作为下一个执行的线程。
恢复新线程的上下文:
加载新线程的CPU寄存器值。
恢复新线程的程序状态。
将新线程的状态更新为运行状态。
上下文切换的影响
开销:上下文切换本身需要消耗时间和CPU资源,包括保存和恢复寄存器、更新任务控制块(TCB)等。频繁的上下文切换会导致额外的开销,从而影响系统的整体性能。
中断:上下文切换通常伴随着中断的发生,这会进一步增加系统的开销。
并发度:虽然上下文切换使得多个线程能够在单个CPU上并发执行,但如果切换过于频繁,反而会降低并发执行的效率。
13.守护线程了解吗?
守护线程(Daemon Thread)是在计算机程序中一种特殊的线程类型,主要用于执行后台任务,而不干扰程序的主要功能。守护线程的特点是它们的存在是为了服务其他线程或整个应用程序,而不是直接为用户提供服务。当所有的非守护线程(也称作用户线程)都结束执行后,Java虚拟机(JVM)会自动终止所有守护线程并退出程序,即使守护线程仍在运行中。
守护线程的特点:
生命周期:
守护线程的生命周期与应用程序的主线程(或非守护线程)紧密相关。当所有的非守护线程都终止时,即使还有守护线程在运行,虚拟机也会认为程序已经不再需要继续执行,并会停止所有守护线程,然后退出程序。
服务性质:
守护线程通常用于执行那些不需要用户交互、对结果不敏感,且在程序运行过程中持续进行的后台任务。例如,垃圾回收(GC)线程、日志记录线程、监控线程、定时任务线程等。
创建与设置:
在Java中,线程默认创建为非守护线程。若要将其设置为守护线程,需要在创建线程后,通过 Thread.setDaemon(true) 方法进行设置。注意,只能在启动线程之前设置线程为守护线程。
退出行为:
当主线程或最后一个非守护线程结束时,即使守护线程还在运行(如循环未结束、阻塞在 I/O 操作等),JVM 也会强制终止守护线程,不会等待其自然结束。因此,守护线程不应该持有任何需要在程序退出时释放的重要资源,也不应该执行任何必须在程序退出前完成的清理工作。
异常处理:
如果守护线程抛出了未捕获的异常,且没有设置默认的未捕获异常处理器,那么该异常会被忽略,并且会导致守护线程立即终止。这与非守护线程不同,非守护线程抛出未捕获异常通常会导致整个程序终止。
14.线程间的通信方式?
①、使用共享对象,多个线程可以访问和修改同一个对象,从而实现信息的传递,比如说 volatile 和 synchronized 关键字。
关键字 volatile 用来修饰成员变量,告知程序任何对该变量的访问均需要从共享内存中获取,而对它的改变必须同步刷新回共享内存,保证所有线程对变量访问的可见性。
关键字 synchronized 可以修饰方法,或者以同步代码块的形式来使用,确保多个线程在同一个时刻,只能有一个线程在执行某个方法或某个代码块。
public class SharedObject {
private String message;
private boolean hasMessage = false;
public synchronized void writeMessage(String message) {
while (hasMessage) {
try {
wait();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
this.message = message;
hasMessage = true;
notifyAll();
}
public synchronized String readMessage() {
while (!hasMessage) {
try {
wait();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
hasMessage = false;
notifyAll();
return message;
}
}
public class Main {
public static void main(String[] args) {
SharedObject sharedObject = new SharedObject();
Thread writer = new Thread(() -> {
sharedObject.writeMessage("Hello from Writer!");
});
Thread reader = new Thread(() -> {
String message = sharedObject.readMessage();
System.out.println("Reader received: " + message);
});
writer.start();
reader.start();
}
}
②、使用 wait() 和 notify(),例如,生产者-消费者模式中,生产者生产数据,消费者消费数据,通过 wait() 和 notify() 方法可以实现生产和消费的协调。
一个线程调用共享对象的 wait() 方法时,它会进入该对象的等待池,并释放已经持有的该对象的锁,进入等待状态,直到其他线程调用相同对象的 notify() 或 notifyAll() 方法。
一个线程调用共享对象的 notify() 方法时,它会唤醒在该对象等待池中等待的一个线程,使其进入锁池,等待获取锁。
Condition 也提供了类似的方法,await() 负责等待、signal() 和 signalAll() 负责通知。
通常与锁(特别是 ReentrantLock)一起使用,为线程提供了一种等待某个条件成真的机制,并允许其他线程在该条件变化时通知等待线程。更灵活、更强大。
class MessageBox {
private String message;
private boolean empty = true;
public synchronized void produce(String message) {
while (!empty) {
try {
wait();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
empty = false;
this.message = message;
notifyAll();
}
public synchronized String consume() {
while (empty) {
try {
wait();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
empty = true;
notifyAll();
return message;
}
}
public class Main {
public static void main(String[] args) {
MessageBox box = new MessageBox();
Thread producer = new Thread(() -> {
box.produce("Message from producer");
});
Thread consumer = new Thread(() -> {
String message = box.consume();
System.out.println("Consumer received: " + message);
});
producer.start();
consumer.start();
}
}
③、使用 Exchanger,Exchanger 是一个同步点,可以在两个线程之间交换数据。一个线程调用 exchange() 方法,将数据传递给另一个线程,同时接收另一个线程的数据。
import java.util.concurrent.Exchanger;
public class Main {
public static void main(String[] args) {
Exchanger<String> exchanger = new Exchanger<>();
Thread thread1 = new Thread(() -> {
try {
String message = "Message from thread1";
String response = exchanger.exchange(message);
System.out.println("Thread1 received: " + response);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
Thread thread2 = new Thread(() -> {
try {
String message = "Message from thread2";
String response = exchanger.exchange(message);
System.out.println("Thread2 received: " + response);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
thread1.start();
thread2.start();
}
}
④、使用 CompletableFuture,CompletableFuture 是 Java 8 引入的一个类,支持异步编程,允许线程在完成计算后将结果传递给其他线程。
public class Main {
public static void main(String[] args) {
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
// 模拟长时间计算
return "Message from CompletableFuture";
});
future.thenAccept(message -> {
System.out.println("Received: " + message);
});
}
}
15.sleep 和 wait 的区别?
sleep() 和 wait() 是 Java 中用于暂停当前线程的两个重要方法,sleep 是让当前线程休眠,不涉及对象类,也不需要获取对象的锁,属于 Thread 类的方法;wait 是让获得对象锁的线程实现等待,前提要获得对象的锁,属于 Object 类的方法。
①、所属类不同
sleep() 方法专属于 Thread 类。 wait() 方法专属于 Object 类。
②、锁行为不同
当线程执行 sleep 方法时,它不会释放任何锁。也就是说,如果一个线程在持有某个对象的锁时调用了 sleep,它在睡眠期间仍然会持有这个锁。
class SleepDoesNotReleaseLock {
private static final Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
Thread sleepingThread = new Thread(() -> {
synchronized (lock) {
System.out.println("Thread 1 会继续持有锁,并且进入睡眠状态");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread 1 醒来了,并且释放了锁");
}
});
Thread waitingThread = new Thread(() -> {
synchronized (lock) {
System.out.println("Thread 2 进入同步代码块");
}
});
sleepingThread.start();
Thread.sleep(1000);
waitingThread.start();
}
}
Thread 1 会继续持有锁,并且进入睡眠状态
Thread 1 醒来了,并且释放了锁
Thread 2 进入同步代码块
从输出中我们可以看到,waitingThread 必须等待 sleepingThread 完成睡眠后才能进入同步代码块。
而当线程执行 wait 方法时,它会释放它持有的那个对象的锁,这使得其他线程可以有机会获取该对象的锁。
class WaitReleasesLock {
private static final Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
Thread waitingThread = new Thread(() -> {
synchronized (lock) {
try {
System.out.println("Thread 1 持有锁,准备等待 5 秒");
lock.wait(5000);
System.out.println("Thread 1 醒来了,并且退出同步代码块");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread notifyingThread = new Thread(() -> {
synchronized (lock) {
System.out.println("Thread 2 尝试唤醒等待中的线程");
lock.notify();
System.out.println("Thread 2 执行完了 notify");
}
});
waitingThread.start();
Thread.sleep(1000);
notifyingThread.start();
}
}
Thread 1 持有锁,准备等待 5 秒
Thread 2 尝试唤醒等待中的线程
Thread 2 执行完了 notify
Thread 1 醒来了,并且退出同步代码块
这表明 waitingThread 在调用 wait 后确实释放了锁。
③、使用条件不同
sleep() 方法可以在任何地方被调用。
wait() 方法必须在同步代码块或同步方法中被调用,这是因为调用 wait() 方法的前提是当前线程必须持有对象的锁。否则会抛出 IllegalMonitorStateException 异常。
④、唤醒方式不同
sleep() 方法在指定的时间过后,线程会自动唤醒继续执行。
wait() 方法需要依靠 notify()、notifyAll() 方法或者 wait() 方法中指定的等待时间到期来唤醒线程。
⑤、抛出异常不同
sleep() 方法在等待期间,如果线程被中断,会抛出 InterruptedException。
如果线程被中断或等待时间到期时,wait() 方法同样会在等待期间抛出 InterruptedException。
sleep()的用法:
class SleepExample {
public static void main(String[] args) {
Thread thread = new Thread(() -> {
System.out.println("线程准备休眠 2 秒");
try {
Thread.sleep(2000); // 线程将睡眠2秒
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程醒来了");
});
thread.start();
}
}
wait()的用法:
class WaitExample {
public static void main(String[] args) {
final Object lock = new Object();
Thread thread = new Thread(() -> {
synchronized (lock) {
try {
System.out.println("线程准备等待 2 秒");
lock.wait(2000); // 线程会等待2秒,或者直到其他线程调用 lock.notify()/notifyAll()
System.out.println("线程结束等待");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread.start();
}
}
16.举例一个线程安全的使用场景?
线程安全是 Java 并发编程中一个非常重要的概念,它指的是多线程环境下,多个线程对共享资源的访问不会导致数据的不一致性。
一个常见的使用场景是在实现单例模式时确保线程安全。
单例模式确保一个类只有一个实例,并提供一个全局访问点。在多线程环境下,如果多个线程同时尝试创建实例,单例类必须确保只创建一个实例。
饿汉式是一种比较直接的实现方式,它通过在类加载时就立即初始化单例对象来保证线程安全。
public class EagerSingleton {
private static final EagerSingleton instance = new EagerSingleton();
private EagerSingleton() {}
public static EagerSingleton getInstance() {
return instance;
}
}
这种方式简单高效,但由于实例在类加载时就已经创建,可能会浪费内存资源。
懒汉式是一种更常用的实现方式,它通过延迟初始化单例对象,在第一次使用时才创建实例。
public class LazySingleton {
private volatile static LazySingleton instance;
private LazySingleton() {}
public static LazySingleton getInstance() {
if (instance == null) {
synchronized (LazySingleton.class) {
if (instance == null) {
instance = new LazySingleton();
}
}
}
return instance;
}
}
双重检查锁定确保了线程安全,并且只在第一次创建实例时加锁,提高了效率。
17.请说一下 ThreadLocal 的作用和使用场景?
ThreadLocal是什么?
ThreadLocal 是 Java 中提供的一种用于实现线程局部变量的工具类。它允许每个线程都拥有自己的独立副本,从而实现线程隔离,用于解决多线程中共享对象的线程安全问题。
ThreadLocal 的工作原理
ThreadLocal 的核心思想是为每个线程提供一个独立的变量副本,这样每个线程都可以独立地修改自己的副本,而不会影响到其他线程的数据。ThreadLocal 类本身维护了一个映射表(ThreadLocalMap),其中键是 ThreadLocal 对象,值则是每个线程对应的变量副本。
ThreadLocal 的使用场景
线程上下文传递
在跨线程调用的场景中,可以使用 ThreadLocal 来存储和传递线程上下文信息。例如,可以将请求 ID、用户身份信息等存储在线程局部变量中,以便在后续的请求处理过程中方便地访问这些信息。
数据库连接管理
在使用数据库连接池的情况下,可以将数据库连接存储在 ThreadLocal 中,这样每个线程可以独立管理自己的数据库连接,避免了线程间的竞争和冲突。例如,MyBatis 中的 SqlSession 对象就使用 ThreadLocal 来存储当前线程的数据库会话信息。
事务管理
在需要手动管理事务的场景下,可以使用 ThreadLocal 来存储事务上下文信息,每个线程可以独立控制自己的事务,保证事务的隔离性。Spring 中的 TransactionSynchronizationManager 就使用 ThreadLocal 来存储事务相关的上下文信息。
工具类或辅助类
有时为了方便,可以将一些工具类或辅助类的实例存储在 ThreadLocal 中,这样在多线程环境中每个线程都有自己独立的实例,避免了线程间的干扰。
临时数据存储
在线程内部,如果需要存储一些临时数据,并且这些数据只在当前线程中有效,可以使用 ThreadLocal 来存储这些数据,避免了复杂的参数传递。
ThreadLocal 的使用步骤
①、创建 ThreadLocal
//创建一个ThreadLocal变量
public static ThreadLocal<String> localVariable = new ThreadLocal<>();
②、设置 ThreadLocal 的值
//设置ThreadLocal变量的值
localVariable.set("java");
③、获取 ThreadLocal 的值
//获取ThreadLocal变量的值
String value = localVariable.get();
④、删除 ThreadLocal 的值
//删除ThreadLocal变量的值
localVariable.remove();
18.除了 ThreadLocal,还有什么解决线程安全问题的方法?
①、Java 中的 synchronized 关键字可以用于方法和代码块,确保同一时间只有一个线程可以执行特定的代码段。
public synchronized void method() {
// 线程安全的操作
}
②、Java 并发包(java.util.concurrent.locks)中提供了 Lock 接口和一些实现类,如 ReentrantLock。相比于 synchronized,ReentrantLock 提供了公平锁和非公平锁。
ReentrantLock lock = new ReentrantLock();
public void method() {
lock.lock();
try {
// 线程安全的操作
} finally {
lock.unlock();
}
}
③、Java 并发包还提供了一组原子变量类(如 AtomicInteger,AtomicLong 等),它们利用 CAS(比较并交换),实现了无锁的原子操作,适用于简单的计数器场景。
AtomicInteger atomicInteger = new AtomicInteger(0);
public void increment() {
atomicInteger.incrementAndGet();
}
④、Java 并发包提供了一些线程安全的集合类,如 ConcurrentHashMap,CopyOnWriteArrayList 等。这些集合类内部实现了必要的同步策略,提供了更高效的并发访问。
ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>();
⑤、volatile 变量保证了变量的可见性,修改操作是立即同步到主存的,读操作从主存中读取。
private volatile boolean flag = false;
19.ThreadLocal 怎么实现的呢?
ThreadLocal 本身并不存储任何值,它只是作为一个映射,来映射线程的局部变量。当一个线程调用 ThreadLocal 的 set 或 get 方法时,实际上是访问线程自己的 ThreadLocal.ThreadLocalMap。
ThreadLocalMap 是 ThreadLocal 的静态内部类,它内部维护了一个 Entry 数组,key 是 ThreadLocal 对象,value 是线程的局部变量本身。
早期的 ThreadLocal 不是这样的,它的 ThreadLocalMap 中使用 Thread 作为 key,这也是最简单的实现方式。
优化后的方案有两个好处,一个是 Map 中存储的键值对变少了;另一个是 ThreadLocalMap 的生命周期和线程一样长,线程销毁的时候,ThreadLocalMap 也会被销毁。
Entry 继承了 WeakReference,它限定了 key 是一个弱引用,弱引用的好处是当内存不足时,JVM 会回收 ThreadLocal 对象,并且将其对应的 Entry 的 value 设置为 null,这样在很大程度上可以避免内存泄漏。
ThreadLocal 的实现原理就是,每个线程维护一个 Map,key 为 ThreadLocal 对象,value 为想要实现线程隔离的对象。
1、当需要存线程隔离的对象时,通过 ThreadLocal 的 set 方法将对象存入 Map 中。
2、当需要取线程隔离的对象时,通过 ThreadLocal 的 get 方法从 Map 中取出对象。
3、Map 的大小由 ThreadLocal 对象的多少决定。
20.java中的引用类型?
在 Java 中,引用类型有四种:强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Reference)和虚引用(Phantom Reference)。每种引用类型都有其特定的用途和行为。下面详细介绍这四种引用类型及其应用场景。
强引用(Strong Reference)
特点:
最常用的引用类型。
只要有强引用指向一个对象,垃圾回收器不会回收该对象。
对象的生命周期最长。
public class StrongReferenceExample {
public static void main(String[] args) {
Object obj = new Object(); // 强引用
obj = null; // 断开强引用
// 如果没有其他强引用指向这个对象,垃圾回收器可以回收它
}
}
应用场景:
适用于需要长期保持对象引用的场景,如全局变量、成员变量等。
软引用(Soft Reference)
特点:
软引用用于描述一些非必需但仍然有用的对象。
当系统即将发生内存溢出(OutOfMemoryError)时,会尝试回收软引用指向的对象。
软引用比弱引用更持久,只有在系统内存不足时才会被回收。
import java.lang.ref.SoftReference;
public class SoftReferenceExample {
public static void main(String[] args) {
Object obj = new Object();
SoftReference<Object> softRef = new SoftReference<>(obj);
obj = null; // 断开强引用
// 如果没有其他强引用指向这个对象,垃圾回收器可以回收它
System.gc(); // 请求垃圾回收
// 检查对象是否已被回收
if (softRef.get() == null) {
System.out.println("对象已被垃圾回收");
} else {
System.out.println("对象还未被垃圾回收");
}
}
}
应用场景:
适用于实现缓存,特别是当缓存对象较大时,可以使用软引用来自动释放内存,避免 OutOfMemoryError。
例如,java.util.WeakHashMap 使用软引用作为键。
弱引用(Weak Reference)
特点:
弱引用用于描述那些非必需的对象。
当垃圾回收器运行时,无论系统内存是否充足,都会回收弱引用指向的对象。
弱引用比软引用更容易被回收。
import java.lang.ref.WeakReference;
public class WeakReferenceExample {
public static void main(String[] args) {
Object obj = new Object();
WeakReference<Object> weakRef = new WeakReference<>(obj);
obj = null; // 断开强引用
// 如果没有其他强引用指向这个对象,垃圾回收器可以回收它
System.gc(); // 请求垃圾回收
// 检查对象是否已被回收
if (weakRef.get() == null) {
System.out.println("对象已被垃圾回收");
} else {
System.out.println("对象还未被垃圾回收");
}
}
}
应用场景:
适用于实现缓存,特别是当缓存对象较小且不需要长期保存时。
例如,java.lang.ref.WeakHashMap 使用弱引用作为键。
虚引用(Phantom Reference)
特点:
虚引用是最弱的一种引用关系。
虚引用并不会决定对象的生命周期。
虚引用主要用于跟踪对象的垃圾回收状态。
虚引用必须与引用队列(ReferenceQueue)关联使用。
import java.lang.ref.PhantomReference;
import java.lang.ref.ReferenceQueue;
public class PhantomReferenceExample {
public static void main(String[] args) {
Object obj = new Object();
ReferenceQueue<Object> queue = new ReferenceQueue<>();
PhantomReference<Object> phantomRef = new PhantomReference<>(obj, queue);
obj = null; // 断开强引用
// 如果没有其他强引用指向这个对象,垃圾回收器可以回收它
System.gc(); // 请求垃圾回收
// 检查对象是否已被回收
if (queue.poll() != null) {
System.out.println("对象已被垃圾回收");
} else {
System.out.println("对象还未被垃圾回收");
}
}
}
应用场景:
适用于跟踪对象的垃圾回收状态,通常用于实现对象的最终化处理。
例如,可以用来实现对象的清理逻辑,确保对象被垃圾回收后执行某些清理操作。
21.ThreadLocal内存泄漏是怎么回事?
通常情况下,随着线程 Thread 的结束,其内部的 ThreadLocalMap 也会被回收,从而避免了内存泄漏。
但如果一个线程一直在运行,并且其 ThreadLocalMap 中的 Entry.value 一直指向某个强引用对象,那么这个对象就不会被回收,从而导致内存泄漏。当 Entry 非常多时,可能就会引发更严重的内存溢出问题。
如何解决内存泄漏问题?
使用完 ThreadLocal 后,及时调用 remove() 方法释放内存空间。
try {
threadLocal.set(value);
// 执行业务操作
} finally {
threadLocal.remove(); // 确保能够执行清理
}
remove() 方法会将当前线程的 ThreadLocalMap 中的所有 key 为 null 的 Entry 全部清除,这样就能避免内存泄漏问题。
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
public void clear() {
this.referent = null;
}
22.ThreadLocal结合线程池使用导致的复用问题?
当 ThreadLocal 与线程池结合使用时,特别容易出现复用问题,主要原因如下:
线程复用:线程池的一个主要特性就是它可以重用已经创建好的线程来执行新任务。这意味着同一个线程可能会被执行多个不同的任务。
数据残留:如果前一个任务在使用 ThreadLocal 变量后没有清理,那么当线程被复用执行下一个任务时,可能会读取到前一个任务留下的 ThreadLocal 变量的值。这对于需要独立上下文的新任务来说是不正确的,可能导致数据混乱或错误的行为。
避免复用问题:为了避免出现复用问题,可以在使用 ThreadLocal 后调用 ThreadLocal 的 remove() 方法来清除 ThreadLocal 变量的值。这样,当线程被复用时,ThreadLocal 变量中的值会被重置,确保每个任务都有自己的独立上下文。
23.ThreadLocal的删除过程?
当一个 ThreadLocal 对象不再被任何强引用持有时,它的生命周期就结束了。此时,ThreadLocalMap 中对应条目的键变成了 null。当 ThreadLocal 的 get() 或 set() 方法被调用时,ThreadLocalMap 会清理掉所有键为 null 的条目,这些条目即为那些已经没有强引用的 ThreadLocal 对象。
此外,如果希望在 ThreadLocal 对象还存在时就清除某个线程上的绑定值,可以调用 ThreadLocal 的 remove() 方法。这会从当前线程的 ThreadLocalMap 中移除该 ThreadLocal 对象的条目。
24.ThreadLocalMap的源码分析?
元素数组
一个 table 数组,存储 Entry 类型的元素,Entry 是 ThreaLocal 弱引用作为 key,Object 作为 value 的结构。
private Entry[] table;
散列方法
散列方法就是怎么把对应的 key 映射到 table 数组的相应下标,ThreadLocalMap 用的是哈希取余法,取出 key 的 threadLocalHashCode,然后和 table 数组长度减一&运算(相当于取余)。
int i = key.threadLocalHashCode & (table.length - 1);
这里的 threadLocalHashCode 计算有点东西,每创建一个 ThreadLocal 对象,它就会新增0x61c88647,这个值很特殊,它是斐波那契数 也叫 黄金分割数。hash增量为 这个数字,带来的好处就是 hash 分布非常均匀。
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
25.ThreadLocalMap如何解决Hash冲突?
使用开放地址法解决哈希冲突。若果某个位置被占用,则继续在当前位置的下一个位置查找,直到找到空位置为止。
26.ThreadLocalMap的扩容?
扩容条件:
当向 ThreadLocalMap 添加一个新的 ThreadLocal 变量时,如果当前 ThreadLocalMap 的大小达到了某个阈值(通常是当前容量的三分之二),那么就会触发扩容操作。
扩容过程:
扩容操作首先会检查当前的 ThreadLocalMap 是否为空,以及是否大于当前容量的三分之二。如果满足条件,则会进行扩容。 扩容的具体操作是创建一个新的数组,其大小通常是原数组大小的两倍。 接着,旧数组中的所有元素会被重新散列,并放入新的数组中。 在此过程中,如果发现某些 ThreadLocal 对象已经被垃圾回收(即它们的引用变为 null),那么这些条目会被清理掉。
重新散列:
重新散列的过程涉及到计算每个 ThreadLocal 对象的哈希值,并确定其在新数组中的位置。 这个过程确保了即使在扩容后,ThreadLocal 对象也能正确地映射到 ThreadLocalMap 中的位置。
更新引用:
完成重新散列后,ThreadLocalMap 内部的指针会被更新以指向新的数组。
垃圾回收:
在扩容过程中,还会检查是否有已经被垃圾回收的 ThreadLocal 对象,并进行相应的清理工作。这是为了防止内存泄漏的发生。
27.父子线程怎么共享数据?
使用 InheritableThreadLocal
InheritableThreadLocal 是 ThreadLocal 的一个子类,它允许子线程继承父线程中的 ThreadLocal 变量。当创建子线程时,如果父线程中有 InheritableThreadLocal 变量,那么这些变量会被复制到子线程中。
// 创建一个可继承的线程局部变量
InheritableThreadLocal<String> inheritableThreadLocal = new InheritableThreadLocal<>();
inheritableThreadLocal.set("Parent Value");
// 创建一个子线程
Thread childThread = new Thread(() -> {
System.out.println("Child Thread Value: " + inheritableThreadLocal.get());
});
childThread.start();
在这个例子中,子线程启动时能够访问到父线程中设置的 InheritableThreadLocal 变量的值。
28.为什么线程要使用自己的内存?
第一,在多线程环境中,如果所有线程都直接操作主内存中的共享变量,会引发更多的内存访问竞争,这不仅影响性能,还增加了线程安全问题的复杂度。通过让每个线程使用本地内存,可以减少对主内存的直接访问和竞争,从而提高程序的并发性能。
第二,现代 CPU 为了优化执行效率,可能会对指令进行乱序执行(指令重排序)。使用本地内存(CPU 缓存和寄存器)可以在不影响最终执行结果的前提下,使得 CPU 有更大的自由度来乱序执行指令,从而提高执行效率。
29.对原子性、可见性、有序性的理解?
原子性:原子性指的是一个操作是不可分割、不可中断的,要么全部执行并且执行的过程不会被任何因素打断,要么就全不执行。
可见性:可见性指的是一个线程修改了共享变量的值,其他线程能够立即看到这个修改。
有序性:有序性指的是对于一个线程的执行代码,从前往后依次执行,单线程下可以认为程序是有序的,但是并发时有可能会发生指令重排。
如何确保原子性、可见性、有序性?
原子性:JMM 只能保证基本的原子性,如果要保证一个代码块的原子性,需要使用synchronized 。
可见性:Java 是利用volatile关键字来保证可见性的,除此之外,final和synchronized也能保证可见性。
有序性:synchronized或者volatile都可以保证多线程之间操作的有序性。
30.什么是指令重排?
指令重排是指编译器或处理器为了优化性能而改变程序中指令执行顺序的行为。虽然重排后的指令在逻辑上仍然遵循程序的语义,但在实际执行时可能会导致一些意想不到的问题,特别是在多线程环境中。
指令重排的原因
指令重排主要有以下几种原因:
编译器优化:
提前计算:编译器可能会提前计算一些表达式的值,以减少运行时的计算开销。
延迟加载:编译器可能会延迟加载一些变量的值,直到真正需要使用时才加载,以减少不必要的内存访问。
处理器优化:
乱序执行:现代处理器采用乱序执行技术,可以在不影响最终结果的情况下调整指令的执行顺序,以充分利用硬件资源。
流水线执行:处理器的流水线技术可以将指令分解成多个阶段并行执行,从而提高执行效率。
内存访问优化:
预取:处理器可能会预先加载一些数据到缓存中,以减少未来的内存访问延迟。
写后置:处理器可能会将写操作推迟到适当的时机,以减少内存访问次数。
指令重排的类型
指令重排可以分为以下几种类型:
编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应 机器指令的执行顺序。
内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
指令重排对多线程程序的影响
指令重排在多线程环境中可能会导致以下问题:
数据不一致:
如果两个线程同时访问和修改同一个变量,指令重排可能会导致数据不一致的问题。
例如,线程 A 先写入变量 x,然后写入变量 y;线程 B 可能会先读取到变量 y 的新值,然后再读取到变量 x 的旧值,导致数据不一致。
内存可见性问题:
指令重排可能会导致内存可见性问题,即一个线程修改的变量值在另一个线程中不可见。
例如,线程 A 修改了变量 x,但由于指令重排,线程 B 可能会读取到变量 x 的旧值。
死锁和活锁:
指令重排可能会导致死锁和活锁问题,特别是在使用锁和其他同步机制时。
例如,线程 A 和线程 B 同时尝试获取两个锁,但由于指令重排,可能会导致死锁。
避免指令重排的方法
使用 volatile 关键字:
volatile 变量的读写操作会插入内存屏障,禁止编译器和处理器对相关指令进行重排序。
volatile int x = 0;
public void writeX() {
x = 1;
}
public void readX() {
if (x == 1) {
// do something
}
}
使用 synchronized 关键字:
synchronized 修饰的方法或代码块会插入内存屏障,禁止编译器和处理器对相关指令进行重排序。
public synchronized void increment() {
count++;
}
使用 final 关键字:
final 变量一旦初始化就不能再改变,确保了线程之间的可见性和有序性。
final int x = 0;
指令重排的限制
两个规则happens-before和as-if-serial来约束。
happens-before规则:
如果一个操作 happens-before 另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
两个操作之间存在 happens-before 关系,并不意味着 Java 平台的具体实现必须要按照 happens-before 关系指定的顺序来执行。如果重排序之后的执行结果,与按 happens-before 关系来执行的结果一致,那么这种重排序并不非法
程序顺序规则:一个线程中的每个操作,happens-before 于该线程中的任意后续操作。
监视器锁规则:对一个锁的解锁,happens-before 于随后对这个锁的加锁。
volatile 变量规则:对一个 volatile 域的写,happens-before 于任意后续对这个 volatile 域的读。
传递性:如果 A happens-before B,且 B happens-before C,那么 A happens-before C。
start()规则:如果线程 A 执行操作 ThreadB.start()(启动线程 B),那么 A 线程的 ThreadB.start()操作 happens-before 于线程 B 中的任意操作。
join()规则:如果线程 A 执行操作 ThreadB.join()并成功返回,那么线程 B 中的任意操作 happens-before 于线程 A 从 ThreadB.join()操作成功返回。
as-if-serial规则:
不管怎么重排序(编译器和处理器为了提高并行度),单线程程序的执行结果不能被改变。编译器、runtime 和处理器都必须遵守 as-if-serial 语义。
为了遵守 as-if-serial 语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。为了具体说明,请看下面计算圆面积的代码示例。
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C
A 和 C 之间存在数据依赖关系,同时 B 和 C 之间也存在数据依赖关系。因此在最终执行的指令序列中,C 不能被重排序到 A 和 B 的前面(C 排到 A 和 B 的前面,程序的结果将会被改变)。但 A 和 B 之间没有数据依赖关系,编译器和处理器可以重排序 A 和 B 之间的执行顺序。
31.volatile关键字的实现原理?
可见性
volatile 变量的主要作用之一是确保变量的可见性。具体来说:
写操作:当一个线程修改了一个 volatile 变量的值时,这个新的值会被立即写回到主内存中。
读操作:当一个线程读取一个 volatile 变量的值时,它会从主内存中读取最新的值,而不是从本地缓存中读取。
有序性
volatile 变量还确保了操作的有序性。具体来说:
内存屏障:volatile 变量的读写操作会插入内存屏障(memory fence),禁止相关的指令重排。
写屏障:在 volatile 变量的写操作前后插入写屏障,确保写操作的有序性。
读屏障:在 volatile 变量的读操作前后插入读屏障,确保读操作的有序性。
写操作
当一个线程修改了一个 volatile 变量的值时:
写操作前插入写屏障:确保之前的写操作已经完成。
写入主内存:将新的值写入主内存。
写操作后插入写屏障:确保后续的写操作不会重排到这个写操作之前。
读操作
当一个线程读取一个 volatile 变量的值时:
读操作前插入读屏障:确保之前的读操作已经完成。
从主内存读取:从主内存中读取最新的值。
读操作后插入读屏障:确保后续的读操作不会重排到这个读操作之前。
32.volatile加在基本类型和对象上的区别?
在 Java 中,volatile 关键字可以用于修饰基本类型和对象。
当 volatile 用于基本数据类型时,能确保该变量的读写操作是直接从主内存中读取或写入的。
当 volatile 用于引用类型时,它确保引用本身的可见性,即确保引用指向的对象地址是最新的。
但是,volatile 并不能保证引用对象内部状态的线程安全性。
33.synchronized 用过吗?怎么使用?
synchronized 是 Java 中用于实现线程同步的关键字,它可以确保共享资源被多个线程安全访问,防止数据不一致的情况发生。synchronized 主要有以下三种用法:
修饰实例方法: 当一个方法被 synchronized 修饰时,该方法被称为同步方法。当一个线程访问某个对象的同步方法时,它首先必须获得该对象的锁,其他试图访问该对象其他同步方法的线程将会阻塞,直到第一个线程执行完毕并释放对象锁。
public class MyClass {
public synchronized void myMethod() {
// 方法体
}
}
修饰静态方法: 当 synchronized 修饰静态方法时,它锁定的是类的 Class 对象,而不是实例对象。这意味着对于所有实例来说,静态同步方法在同一时刻只能被一个线程访问。
public class MyClass {
public static synchronized void myStaticMethod() {
// 方法体
}
}
修饰代码块: synchronized 还可以用来修饰代码块,允许开发者指定一个对象作为锁对象,这样只有获得了该对象锁的线程才能执行这段代码块。
public class MyClass {
private final Object myLock = new Object();
public void myMethod() {
synchronized (myLock) {
// 同步代码块
}
}
}
synchronized 的实现原理?
synchronized 在 Java 中是一个关键字,用于实现线程间的同步。其底层实现原理依赖于 JVM(Java 虚拟机)提供的 Monitor(监视器)机制,并且在不同的 Java 版本中有所优化。以下是 synchronized 的实现原理概览:
Monitor 监视器
每个对象都有一个与之关联的监视器锁,也称为 Monitor。当一个线程进入一个 synchronized 代码块或方法时,它必须先获取对象的 Monitor。
如果该 Monitor 已经被另一个线程持有,请求锁的线程将被阻塞,直到当前持有锁的线程释放锁。
当线程退出 synchronized 块或方法时,它会释放该对象的 Monitor,使得其他线程有机会获取锁。
可重入锁
synchronized 支持可重入性,这意味着同一个线程可以多次获取同一个对象的锁而不会导致死锁。每次进入 synchronized 区域都会增加锁的计数,相应地,每次退出都会减少计数,直到计数归零才真正释放锁。
synchronized 之所以支持可重入,是因为 Java 的对象头包含了一个 Mark Word,用于存储对象的状态,包括锁信息。
当一个线程获取对象锁时,JVM 会将该线程的 ID 写入 Mark Word,并将锁计数器设为 1。
如果一个线程尝试再次获取已经持有的锁,JVM 会检查 Mark Word 中的线程 ID。如果 ID 匹配,表示的是同一个线程,锁计数器递增。
当线程退出同步块时,锁计数器递减。如果计数器值为零,JVM 将锁标记为未持有状态,并清除线程 ID 信息。
锁的优化
从 Java 1.6 开始,为了减少锁的开销,引入了多种锁的状态,包括偏向锁(Biased Locking)、轻量级锁(Lightweight Locking)和重量级锁(Heavyweight Locking)。
偏向锁:当一个线程访问同步代码前,会先检查是否有线程已经获取了锁,如果没有,虚拟机会尝试将对象头的所有者设置为当前线程,同时将状态改为偏向模式。这样后续该线程再次访问时就不需要额外的同步操作。
轻量级锁:当有第二个线程尝试获取锁时,会使用 CAS 操作来尝试获取锁。如果 CAS 失败,则会尝试自旋(Spinning),即循环尝试获取锁。
重量级锁:如果自旋一定次数仍然没有获取到锁,则会放弃自旋,线程进入阻塞状态,等待锁的持有线程释放锁后再通过操作系统内核调度唤醒。
锁的升级
①、从无锁到偏向锁:
当一个线程首次访问同步块时,如果此对象无锁状态且偏向锁未被禁用,JVM 会将该对象头的锁标记改为偏向锁状态,并记录下当前线程的 ID。此时,对象头中的 Mark Word 中存储了持有偏向锁的线程 ID。
如果另一个线程尝试获取这个已被偏向的锁,JVM 会检查当前持有偏向锁的线程是否活跃。如果持有偏向锁的线程不活跃,则可以将锁重偏向至新的线程;如果持有偏向锁的线程还活跃,则需要撤销偏向锁,升级为轻量级锁。
②、偏向锁的轻量级锁:
进行偏向锁撤销时,会遍历堆栈的所有锁记录,暂停拥有偏向锁的线程,并检查锁对象。如果这个过程中发现有其他线程试图获取这个锁,JVM 会撤销偏向锁,并将锁升级为轻量级锁。
当有两个或以上线程竞争同一个偏向锁时,偏向锁模式不再有效,此时偏向锁会被撤销,对象的锁状态会升级为轻量级锁。
③、轻量级锁到重量级锁:
轻量级锁通过线程自旋来等待锁释放。如果自旋超过预定次数(自旋次数是可调的,并且自适应的),表明锁竞争激烈,轻量级锁的自旋已经不再高效。
当自旋等待失败,或者有线程在等待队列中等待相同的轻量级锁时,轻量级锁会升级为重量级锁。在这种情况下,JVM 会在操作系统层面创建一个互斥锁(Mutex),所有进一步尝试获取该锁的线程将会被阻塞,直到锁被释放。
锁的获取与释放:
synchronized 的实现依赖于 JVM 的内部指令 monitorenter 和 monitorexit。当线程执行到 synchronized 代码块之前,会执行 monitorenter 指令获取锁;当执行完 synchronized 代码块之后,会执行 monitorexit 指令释放锁。
34.synchronized和ReentrantLock区别和场景?
synchronized 和 ReentrantLock 都是 Java 中用于实现线程同步的重要工具,但它们之间存在一些关键的区别,这些区别决定了它们在不同场景下的适用性。以下是两者的主要区别及适用场景:
使用方式:
synchronized 是 Java 关键字,直接在代码级别声明同步区域或方法。
ReentrantLock 是一个类,实现了 Lock 接口,需要显式地调用 lock() 方法获取锁,以及 unlock() 方法释放锁。
// synchronized 修饰方法
public synchronized void method() {
// 业务代码
}
// synchronized 修饰代码块
synchronized (this) {
// 业务代码
}
// ReentrantLock 加锁
ReentrantLock lock = new ReentrantLock();
lock.lock();
try {
// 业务代码
} finally {
lock.unlock();
}
锁的释放:
synchronized 在线程抛出异常时能够自动释放锁,因此不需要担心由于异常而导致的死锁。
ReentrantLock 必须显式地调用 unlock() 方法释放锁,如果在 try 块中获取锁而在 finally 块中释放锁,则可以保证即使抛出异常也能释放锁,否则可能导致死锁。
响应中断:
synchronized 不支持响应中断,如果一个线程在等待锁时被中断,它仍然会等待锁。
ReentrantLock 支持响应中断,可以通过 lockInterruptibly() 方法来允许等待锁的线程响应中断。
锁的公平性:
synchronized 总是非公平锁,即新来的线程可能会优先于已经在等待的线程获取锁。
ReentrantLock 可以选择是公平锁还是非公平锁,通过构造函数传入 true 或 false 参数来决定。
扩展性:
synchronized 提供的功能较为简单,主要用于基本的同步需求。
ReentrantLock 提供了更丰富的功能,如尝试锁(tryLock)、可中断锁(lockInterruptibly)、定时锁(tryLock(long time, TimeUnit unit))等高级功能。
适用场景:
synchronized 更适合于简单的同步需求,尤其是在代码简洁性和安全性更为重要的情况下。它的使用更加简单,不需要额外的代码来管理锁的获取和释放。
ReentrantLock 适用于需要更精细控制锁行为的场景,比如需要支持中断或者希望实现公平锁,以及需要在等待锁时进行超时处理等。它提供了更多的灵活性和控制力
性能考量:
在性能方面,早期 synchronized 的性能较差,但在 Java 6 之后,随着 JVM 对 synchronized 的优化(如引入偏向锁、轻量级锁等),在某些低竞争场景下,synchronized 的性能可能优于 ReentrantLock。然而,在高竞争场景下,ReentrantLock 可能表现出更好的性能,因为它的实现可以更好地利用现代多核处理器的优势。
并发量大的情况下,使用 synchronized 还是 ReentrantLock?
在并发量特别高的情况下,ReentrantLock 的性能可能会优于 synchronized,原因包括:
ReentrantLock 提供了超时和公平锁等特性,可以更好地应对复杂的并发场景 。
ReentrantLock 允许更细粒度的锁控制,可以有效减少锁竞争。
ReentrantLock 支持条件变量 Condition,可以实现比 synchronized 更复杂的线程间通信机制。
35.AQS 了解多少?
AQS,全称是 AbstractQueuedSynchronizer,中文意思是抽象队列同步器,由 Doug Lea 设计,是 Java 并发包java.util.concurrent的核心框架类,许多同步类的实现都依赖于它,如 ReentrantLock、Semaphore、CountDownLatch 等。
AQS 的思想是,如果被请求的共享资源空闲,则当前线程能够成功获取资源;否则,它将进入一个等待队列,当有其他线程释放资源时,系统会挑选等待队列中的一个线程,赋予其资源。
整个过程通过维护一个 int 类型的状态和一个先进先出(FIFO)的队列,来实现对共享资源的管理。
①、同步状态 state 由 volatile 修饰,保证了多线程之间的可见性;
private volatile int state;
②、同步队列是通过内部定义的 Node 类来实现的,每个 Node 包含了等待状态、前后节点、线程的引用等。
static final class Node {
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
volatile Node prev;
volatile Node next;
volatile Thread thread;
}
AQS 支持两种同步方式:
独占模式:这种方式下,每次只能有一个线程持有锁,例如 ReentrantLock。
共享模式:这种方式下,多个线程可以同时获取锁,例如 Semaphore 和 CountDownLatch。
子类可以通过继承 AQS 并实现它的方法来管理同步状态,这些方法包括:
tryAcquire:独占方式尝试获取资源,成功则返回 true,失败则返回 false;
tryRelease:独占方式尝试释放资源;
tryAcquireShared(int arg):共享方式尝试获取资源;
tryReleaseShared(int arg):共享方式尝试释放资源;
isHeldExclusively():该线程是否正在独占资源。
如果共享资源被占用,需要一种特定的阻塞等待唤醒机制来保证锁的分配,AQS 会将竞争共享资源失败的线程添加到一个 CLH 队列中。
在 CLH 锁中,当一个线程尝试获取锁并失败时,它会将自己添加到队列的尾部并自旋,等待前一个节点的线程释放锁。
36.ReentrantLock 实现原理?
ReentrantLock 是可重入的独占锁,只能有一个线程可以获取该锁,其它获取该锁的线程会被阻塞。
可重入表示当前线程获取该锁后再次获取不会被阻塞,也就意味着同一个线程可以多次获得同一个锁而不会发生死锁。
new ReentrantLock() 默认创建的是非公平锁 NonfairSync。
公平锁 FairSync
在公平锁模式下,锁会授予等待时间最长的线程。
非公平锁 NonfairSync
在非公平锁模式下,锁可能会授予刚刚请求它的线程,而不考虑等待时间。
ReentrantLock 内部通过一个计数器来跟踪锁的持有次数。
当线程调用lock()方法获取锁时,ReentrantLock 会检查当前状态,判断锁是否已经被其他线程持有。如果没有被持有,则当前线程将获得锁;如果锁已被其他线程持有,则当前线程将根据锁的公平性策略,可能会被加入到等待队列中。
线程首次获取锁时,计数器值变为 1;如果同一线程再次获取锁,计数器增加;每释放一次锁,计数器减 1。
当线程调用unlock()方法时,ReentrantLock 会将持有锁的计数减 1,如果计数到达 0,则释放锁,并唤醒等待队列中的线程来竞争锁。
37.ReentrantLock 怎么实现公平锁的?
在 ReentrantLock 中,公平锁的实现主要通过 FairSync 类来完成,它是 ReentrantLock.Sync 的子类,继承自 AbstractQueuedSynchronizer(AQS)。公平锁的核心在于确保线程获取锁的顺序符合它们在队列中的位置。
公平锁意味着在多个线程竞争锁时,获取锁的顺序与线程请求锁的顺序相同,即先来先服务(FIFO)。
虽然能保证锁的顺序,但实现起来比较复杂,因为需要额外维护一个有序队列。
非公平锁不保证线程获取锁的顺序,当锁被释放时,任何请求锁的线程都有机会获取锁,而不是按照请求的顺序。
38.CAS 了解多少?
CAS(Compare-and-Swap)是一种乐观锁的实现方式,全称为“比较并交换”,是一种无锁的原子操作。
在 Java 中,我们可以使用 synchronized关键字和 CAS 来实现加锁效果。
synchronized 是悲观锁,尽管随着 JDK 版本的升级,synchronized 关键字已经“轻量级”了很多,但依然是悲观锁,线程开始执行第一步就要获取锁,一旦获得锁,其他的线程进入后就会阻塞并等待锁。
CAS 是乐观锁,线程执行的时候不会加锁,它会假设此时没有冲突,然后完成某项操作;如果因为冲突失败了就重试,直到成功为止。
在 CAS 中,有这样三个值:
V:要更新的变量(var)
E:预期值(expected)
N:新值(new)
比较并交换的过程如下:
判断 V 是否等于 E,如果等于,将 V 的值设置为 N;如果不等,说明已经有其它线程更新了 V,于是当前线程放弃更新,什么都不做。
这里的预期值 E 本质上指的是“旧值”。
这个比较和替换的操作是原子的,即不可中断,确保了数据的一致性。
举个例子,变量当前的值为 0,需要将其更新为 1,可以借助 AtomicInteger 类的 compareAndSet 方法来实现。
AtomicInteger atomicInteger = new AtomicInteger(0);
int expect = 0;
int update = 1;
atomicInteger.compareAndSet(expect, update);
compareAndSet 就是一个 CAS 方法,它调用的是 Unsafe 的 compareAndSwapInt。
Unsafe 对 CAS 的实现是通过 C++ 实现的,它的具体实现和操作系统、CPU 都有关系。
Linux 的 X86 下主要是通过 cmpxchgl 这个指令在 CPU 上完成 CAS 操作的,但在多处理器情况下,必须使用 lock 指令加锁来完成。当然,不同的操作系统和处理器在实现方式上肯定会有所不同。
39.CAS 有什么问题?如何解决?
ABA 问题
描述:即使 CAS 操作成功,也不能保证在这段时间内没有发生过其他变化。例如,一个值从 A 变成 B 再变回 A,此时 CAS 操作仍然会成功,但实际上已经发生了改变。
解决方案:
使用带有版本号或时间戳的原子引用类型(如 AtomicStampedReference),每次更新时都带上版本号,从而避免 ABA 问题。
public class OptimisticLockExample {
private int version;
private int value;
public synchronized boolean updateValue(int newValue, int currentVersion) {
if (this.version == currentVersion) {
this.value = newValue;
this.version++;
return true;
}
return false;
}
}
忙等待问题
描述:当 CAS 操作失败时,通常会进行自旋重试,这可能导致 CPU 资源浪费。
解决方案:
引入延时重试机制,增加重试间隔时间。
结合其他同步机制,如锁,来避免长时间的忙等待。
在 Java 中,很多使用自旋 CAS 的地方,会有一个自旋次数的限制,超过一定次数,就停止自旋。
只能保证单个变量的原子性
描述:CAS 操作只能保证单个变量更新的原子性,对于多个变量同时更新无法保证原子性。
解决方案:
对于多个变量的操作,可以考虑使用锁或其他更复杂的同步机制。
将多个变量封装成一个对象,然后对整个对象进行 CAS 操作。
40.原子操作类了解多少?
Atomic 包里的类基本都是使用 Unsafe 实现的包装类。
使用原子的方式更新基本类型,Atomic 包提供了以下 3 个类:
AtomicBoolean:原子更新布尔类型。
AtomicInteger:原子更新整型。
AtomicLong:原子更新长整型。
通过原子的方式更新数组里的某个元素,Atomic 包提供了以下 4 个类:
AtomicIntegerArray:原子更新整型数组里的元素。
AtomicLongArray:原子更新长整型数组里的元素。
AtomicReferenceArray:原子更新引用类型数组里的元素。
AtomicIntegerArray 类主要是提供原子的方式更新数组里的整型
原子更新基本类型的 AtomicInteger,只能更新一个变量,如果要原子更新多个变量,就需要使用这个原子更新引用类型提供的类。Atomic 包提供了以下 3 个类:
AtomicReference:原子更新引用类型。
AtomicReferenceFieldUpdater:原子更新引用类型里的字段。
AtomicMarkableReference:原子更新带有标记位的引用类型。可以原子更新一个布尔类型的标记位和引用类型。构造方法是 AtomicMarkableReference(V initialRef,boolean initialMark)。
如果需原子地更新某个类里的某个字段时,就需要使用原子更新字段类,Atomic 包提供了以下 3 个类进行原子字段更新:
AtomicIntegerFieldUpdater:原子更新整型的字段的更新器。
AtomicLongFieldUpdater:原子更新长整型字段的更新器。
AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
以 AtomicInteger 的添加方法为例:
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
通过Unsafe类的实例来进行添加操作,来看看具体的 CAS 操作:
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
compareAndSwapInt 是一个 native 方法,基于 CAS 来操作 int 类型变量。其它的原子操作类基本都是大同小异。
41.线程死锁了解吗?该如何避免?
线程死锁是指两个或多个线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象。在这种情况下,每个线程都在等待另一个线程释放它所需要的资源,结果导致所有相关线程都无法继续执行下去。
死锁的必要条件
互斥条件:至少有一个资源必须处于非共享模式,即一次只能有一个线程使用。如果另一个线程想要使用该资源,那么它必须等待,直到拥有该资源的线程释放它。
请求与保持条件:一个线程已经持有了至少一个资源,但又提出了新的资源请求,而该资源已被其它线程占有,因此请求线程被阻塞。
不可抢占条件:线程已经获得的资源,在结束前不能被其他线程强行抢占,只能主动释放。
循环等待条件:存在一种涉及两个或多个线程的循环等待链,每个线程都在等待下一个线程持有的资源。
避免死锁的方法
打破循环等待条件:
给资源分配一个全局唯一的顺序,所有线程按照相同的顺序请求资源。例如,如果系统中有多个锁,则按照锁对象的地址排序,线程总是按照从小到大的顺序获取锁。
使用超时机制,当线程请求资源时设置一个超时时间,超时后放弃资源请求。
打破不可抢占条件:
允许持有较少资源的线程释放资源,让持有更多资源的线程先完成任务。
打破请求与保持条件:
要求线程一次性请求所有需要的资源,而不是在持有部分资源的情况下再请求其他资源。
打破互斥条件:
虽然完全避免互斥条件不太现实,但是可以通过减少互斥资源的数量或使用替代方案来降低死锁的可能性。
42.死锁问题怎么排查呢?
使用 jstack 命令
jstack 是一个 Java 工具,它可以打印出 Java 进程中的所有线程的堆栈跟踪信息。
命令示例:
jstack <pid>
在输出的信息中,你可以看到每个线程的状态,包括 BLOCKED 状态,这可能是死锁的迹象。
使用 jconsole 工具
jconsole 是一个图形化的监控工具,可以显示 JVM 的详细信息,包括线程状态。
使用方法:通过 jconsole 连接到目标 JVM,然后查看线程监视器图表,可以发现死锁的线程。
使用 VisualVM
VisualVM 是一个集成的工具,它提供了类似 jconsole 的功能,但还包含了更多的分析工具。
使用方法:打开 VisualVM,连接到目标 JVM,然后查看线程视图,查找死锁情况。
43.乐观锁和悲观锁?
对于悲观锁来说,它总是认为每次访问共享资源时会发生冲突,所以必须对每次数据操作加上锁,以保证临界区的程序同一时间只能有一个线程在执行。
悲观锁的代表有 synchronized 关键字和 Lock 接口。
乐观锁,顾名思义,它是乐观派。乐观锁总是假设对共享资源的访问没有冲突,线程可以不停地执行,无需加锁也无需等待。一旦多个线程发生冲突,乐观锁通常使用一种称为 CAS 的技术来保证线程执行的安全性。
由于乐观锁假想操作中没有锁的存在,因此不太可能出现死锁的情况,换句话说,乐观锁天生免疫死锁。
乐观锁多用于“读多写少“的环境,避免频繁加锁影响性能;
悲观锁多用于”写多读少“的环境,避免频繁失败和重试影响性能。
44.CountDownLatch(倒计数器)了解吗?
CountDownLatch 是 Java 并发包(java.util.concurrent)中的一个同步辅助类,用于协调多个线程之间的同步。它允许一个或多个线程等待,直到在其他线程中执行的一组操作完成。
工作原理:
CountDownLatch 通过一个计数器来实现,该计数器初始化为一个正整数。每当一个线程完成了它的工作后,计数器就会减一。当计数器的值变为零时,所有等待的线程都会被唤醒,继续执行。
主要方法:
CountDownLatch(int count):构造一个用给定计数初始化的 CountDownLatch。
void await():使当前线程等待,直到计数器的值变为零,除非线程被中断。
boolean await(long timeout, TimeUnit unit):使当前线程等待,直到计数器的值变为零,或者等待超时,或者线程被中断。
void countDown():递减计数器的值。如果计数器的值变为零,则所有等待的线程都会被唤醒。
示例代码:
import java.util.concurrent.CountDownLatch;
public class CountDownLatchExample {
public static void main(String[] args) {
int threadCount = 3;
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
new Thread(new Worker(latch)).start();
}
try {
// 主线程等待,直到计数器变为零
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("所有工作线程已完成,主线程继续执行。");
}
}
class Worker implements Runnable {
private final CountDownLatch latch;
public Worker(CountDownLatch latch) {
this.latch = latch;
}
@Override
public void run() {
try {
// 模拟工作
Thread.sleep((long) (Math.random() * 1000));
System.out.println(Thread.currentThread().getName() + " 完成工作");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 递减计数器
latch.countDown();
}
}
}
在这个示例中,主线程创建了三个工作线程,并使用 CountDownLatch 来等待所有工作线程完成工作。每个工作线程在完成工作后都会调用 countDown() 方法递减计数器。当计数器的值变为零时,主线程会被唤醒,继续执行后续操作。
45.CyclicBarrier(同步屏障)了解吗?
CyclicBarrier 是 Java 并发包(java.util.concurrent)中的一个同步辅助类,用于协调多个线程在某个点上相互等待,直到所有线程都到达这个点后再继续执行。它类似于 CountDownLatch,但 CyclicBarrier 可以被重用
工作原理:
CyclicBarrier 通过一个计数器来实现,该计数器初始化为一个正整数,表示需要等待的线程数。每当一个线程到达屏障点时,计数器减一。当计数器的值变为零时,所有等待的线程都会被唤醒,继续执行。如果需要,CyclicBarrier 可以在所有线程被唤醒之前执行一个可选的屏障操作。
主要方法:
CyclicBarrier(int parties):构造一个新的 CyclicBarrier,它将在指定数量的线程(parties)都调用 await 方法时触发。
CyclicBarrier(int parties, Runnable barrierAction):构造一个新的 CyclicBarrier,它将在指定数量的线程(parties)都调用 await 方法时触发,并在所有线程被唤醒之前执行给定的屏障操作。
int await():使当前线程在屏障点等待,直到所有线程都到达屏障点。
int await(long timeout, TimeUnit unit):使当前线程在屏障点等待,直到所有线程都到达屏障点,或者等待超时,或者线程被中断。
示例代码:
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class CyclicBarrierExample {
public static void main(String[] args) {
int threadCount = 3;
CyclicBarrier barrier = new CyclicBarrier(threadCount, new Runnable() {
@Override
public void run() {
System.out.println("所有线程都到达屏障点,继续执行...");
}
});
for (int i = 0; i < threadCount; i++) {
new Thread(new Worker(barrier)).start();
}
}
}
class Worker implements Runnable {
private final CyclicBarrier barrier;
public Worker(CyclicBarrier barrier) {
this.barrier = barrier;
}
@Override
public void run() {
try {
// 模拟工作
Thread.sleep((long) (Math.random() * 1000));
System.out.println(Thread.currentThread().getName() + " 到达屏障点");
barrier.await();
System.out.println(Thread.currentThread().getName() + " 继续执行");
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
}
在这个示例中,主线程创建了三个工作线程,并使用 CyclicBarrier 来让所有线程在某个点上相互等待。每个工作线程在到达屏障点后都会调用 await() 方法。当所有线程都到达屏障点时,屏障操作会被执行,然后所有线程继续执行后续操作。
46.CyclicBarrier 和 CountDownLatch 有什么区别?
两者最核心的区别:
CountDownLatch 是一次性的,而 CyclicBarrier 则可以多次设置屏障,实现重复利用;
CountDownLatch 中的各个子线程不可以等待其他线程,只能完成自己的任务;而 CyclicBarrier 中的各个线程可以等待其他线程
| CyclicBarrier | CountDownLatch |
|---|---|
| CyclicBarrier 是可重用的,其中的线程会等待所有的线程完成任务。届时,屏障将被拆除,并可以选择性地做一些特定的动作。 | CountDownLatch 是一次性的,不同的线程在同一个计数器上工作,直到计数器为 0. |
| CyclicBarrier 面向的是线程数 | CountDownLatch 面向的是任务数 |
| 在使用 CyclicBarrier 时,你必须在构造中指定参与协作的线程数,这些线程必须调用 await()方法 | 使用 CountDownLatch 时,则必须要指定任务数,至于这些任务由哪些线程完成无关紧要 |
| CyclicBarrier 可以在所有的线程释放后重新使用 | CountDownLatch 在计数器为 0 时不能再使用 |
| 在 CyclicBarrier 中,如果某个线程遇到了中断、超时等问题时,则处于 await 的线程都会出现问题 | 在 CountDownLatch 中,如果某个线程出现问题,其他线程不受影响 |
47.Semaphore(信号量)了解吗?
Semaphore 是 Java 并发包(java.util.concurrent)中的一个同步辅助类,用于控制对某个资源的访问数量。它可以用来限制同时访问某些资源的线程数量。
工作原理:
Semaphore 维护了一个许可计数器,表示可以同时访问资源的最大线程数。线程在访问资源前需要获取许可,访问结束后需要释放许可。如果没有可用的许可,线程将被阻塞,直到有可用的许可为止。
主要方法:
Semaphore(int permits):构造一个具有给定许可数量的 Semaphore。
Semaphore(int permits, boolean fair):构造一个具有给定许可数量和公平性设置的 Semaphore。公平性设置为 true 时,Semaphore 会按照线程请求许可的顺序分配许可。
void acquire():获取一个许可,如果没有可用的许可,线程将被阻塞,直到有可用的许可。
void acquire(int permits):获取指定数量的许可。
void release():释放一个许可。
void release(int permits):释放指定数量的许可。
int availablePermits():返回当前可用的许可数量。
示例代码:
import java.util.concurrent.Semaphore;
public class SemaphoreExample {
public static void main(String[] args) {
int threadCount = 5;
Semaphore semaphore = new Semaphore(2); // 允许同时访问的线程数为2
for (int i = 0; i < threadCount; i++) {
new Thread(new Worker(semaphore)).start();
}
}
}
class Worker implements Runnable {
private final Semaphore semaphore;
public Worker(Semaphore semaphore) {
this.semaphore = semaphore;
}
@Override
public void run() {
try {
// 获取许可
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + " 获取许可,开始工作");
// 模拟工作
Thread.sleep((long) (Math.random() * 1000));
System.out.println(Thread.currentThread().getName() + " 释放许可,结束工作");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放许可
semaphore.release();
}
}
}
在这个示例中,主线程创建了五个工作线程,并使用 Semaphore 来限制同时访问资源的线程数量为两个。每个工作线程在获取许可后开始工作,工作结束后释放许可。这样,最多只有两个线程可以同时访问资源。
Semaphore 用于控制对某个资源的访问数量,限制同时访问资源的线程数量。
主要方法 包括 acquire() 和 release(),分别用于获取和释放许可。
应用场景 包括限制同时访问某个资源的线程数量、实现资源池等。
48.Exchanger 了解吗?
Exchanger 是 Java 并发包(java.util.concurrent)中的一个同步点类,用于在两个线程之间交换数据。它提供了一个同步点,两个线程可以在这个同步点上交换数据。
工作原理: Exchanger 允许两个线程在同步点上交换数据。每个线程在到达同步点时,都会将自己的数据传递给对方,并接收对方的数据。这个交换操作是同步的,即两个线程必须都到达同步点,交换才会发生。
主要方法:
Exchanger():构造一个新的 Exchanger。
V exchange(V x):在同步点上与另一个线程交换数据。如果另一个线程还没有到达同步点,则当前线程将等待。
V exchange(V x, long timeout, TimeUnit unit):在同步点上与另一个线程交换数据,带有超时设置。如果在指定的时间内没有另一个线程到达同步点,则抛出 TimeoutException。
示例代码:
import java.util.concurrent.Exchanger;
public class ExchangerExample {
public static void main(String[] args) {
Exchanger<String> exchanger = new Exchanger<>();
Thread thread1 = new Thread(new Worker(exchanger, "数据来自线程1"));
Thread thread2 = new Thread(new Worker(exchanger, "数据来自线程2"));
thread1.start();
thread2.start();
}
}
class Worker implements Runnable {
private final Exchanger<String> exchanger;
private final String data;
public Worker(Exchanger<String> exchanger, String data) {
this.exchanger = exchanger;
this.data = data;
}
@Override
public void run() {
try {
System.out.println(Thread.currentThread().getName() + " 交换前的数据: " + data);
String exchangedData = exchanger.exchange(data);
System.out.println(Thread.currentThread().getName() + " 交换后的数据: " + exchangedData);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
在这个示例中,两个线程分别创建了自己的数据,并使用 Exchanger 在同步点上交换数据。每个线程在交换前打印自己的数据,然后在交换后打印接收到的数据。
Exchanger 用于在两个线程之间交换数据
主要方法 包括 exchange(),用于在同步点上交换数据。
应用场景 包括需要在两个线程之间交换数据的场景,例如,生产者和消费者之间的数据交换。
49.ConcurrentHashMap 对 HashMap 的优化?ConcurrentHashMap 1.8 比 1.7 的优化在哪里?
ConcurrentHashMap 是 Java 并发包中的一个线程安全的哈希表实现,它对 HashMap 进行了多方面的优化,以支持高并发环境下的高效操作。
取消分段锁:
在 Java 1.7 中,ConcurrentHashMap 使用分段锁,每个段有一个独立的锁。虽然这种方式提高了并发性能,但仍然存在锁竞争的问题。
在 Java 1.8 中,ConcurrentHashMap 取消了分段锁,转而使用更细粒度的锁(桶锁)和 CAS 操作。这种方式减少了锁的粒度,提高了并发性能。
引入红黑树:
在 Java 1.7 中,ConcurrentHashMap 使用链表来处理哈希冲突。当链表长度较长时,查找和插入的性能会下降。
在 Java 1.8 中,当链表长度超过一定阈值时,链表会转换为红黑树,从而提高查找和插入的性能。
更高效的扩容机制:
在 Java 1.8 中,ConcurrentHashMap 的扩容机制也进行了优化。扩容时,多个线程可以并发地进行数据迁移,从而提高扩容的效率。
50.为什么 ConcurrentHashMap 在 JDK 1.7 中要用 ReentrantLock,而在 JDK 1.8 要用 synchronized?
性能优化:
在 JDK 1.6 之后,synchronized 的性能得到了显著优化,特别是在偏向锁和轻量级锁的情况下,synchronized 的开销非常小。
synchronized 是 JVM 内置的锁机制,能够更好地与 JVM 的其他优化机制配合。
代码简化:
使用 synchronized 可以简化代码结构,使代码更易于维护和理解。
synchronized 是一种内置的锁机制,不需要显式地管理锁对象,减少了代码的复杂性。
更细粒度的锁:
JDK 1.7 中的 ConcurrentHashMap 使用了分段锁机制,即 Segment 锁,每个 Segment 都是一个 ReentrantLock,这样可以保证每个 Segment 都可以独立地加锁,从而实现更高级别的并发访问。
JDK 1.8 中的 ConcurrentHashMap 使用更细粒度的锁,只对特定的桶(bucket)进行加锁,而不是整个段。这种方式减少了锁的粒度,提高了并发性能。
51.为什么 ConcurrentHashMap 比 Hashtable 效率高
ConcurrentHashMap 比 Hashtable 效率高的原因主要在于它们的锁机制和并发控制方式的不同。
Hashtable 的锁机制
Hashtable 是一个线程安全的哈希表实现,但它的线程安全是通过对整个哈希表进行同步来实现的。每次对 Hashtable 的读写操作都会锁住整个哈希表,这意味着在高并发环境下,多个线程不能同时访问 Hashtable,从而导致性能瓶颈。
public synchronized V get(Object key) {
// 获取操作
}
public synchronized V put(K key, V value) {
// 插入操作
}
ConcurrentHashMap 的锁机制
ConcurrentHashMap通过更细粒度的锁机制来实现线程安全,从而提高了并发性能。
JDK 1.7 中的 ConcurrentHashMap
在 JDK 1.7 中,ConcurrentHashMap 使用了分段锁(Segmented Locking)机制。整个哈希表被分成多个段(Segment),每个段是一个独立的哈希表,并且有自己的锁。这样,多个线程可以并发地访问不同段的数据,从而提高并发性能。
final Segment<K,V>[] segments;
static final class Segment<K,V> extends ReentrantLock implements Serializable {
// Segment 内部实现
}
JDK 1.8 中的 ConcurrentHashMap
在 JDK 1.8 中,ConcurrentHashMap摒弃了分段锁机制,转而使用更细粒度的锁和 CAS(Compare-And-Swap)操作。具体来说,JDK 1.8 中的 ConcurrentHashMap主要使用 synchronized和 CAS 操作来保证线程安全。
- CAS 操作:CAS 是一种无锁的并发编程技术,通过比较和交换操作来保证数据的一致性。在大多数情况下,CAS 操作比锁机制更高效,因为它避免了线程的阻塞和上下文切换。
- 细粒度锁:在插入新节点时,只对特定的桶(bucket)进行加锁,而不是整个哈希表。这种方式减少了锁的粒度,提高了并发性能。
static final class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
// 使用 synchronized 和 CAS 操作进行数据迁移
synchronized (f) {
// 迁移逻辑
}
}
- 锁粒度:
Hashtable对整个哈希表进行同步,而ConcurrentHashMap使用更细粒度的锁(分段锁或桶锁),从而允许更高的并发访问。 - 性能优化:
ConcurrentHashMap在 JDK 1.8 中使用了 CAS 操作和更细粒度的锁,进一步提高了并发性能。 - 代码简化:
ConcurrentHashMap在 JDK 1.8 中使用synchronized和 CAS 操作,简化了代码结构,并利用 JVM 的优化机制提高性能。
因此,ConcurrentHashMap比 Hashtable 在高并发环境下具有更高的效率和更好的性能表现。
JVM
1.什么是JVM?
JVM,也就是 Java 虚拟机,它是 Java 实现跨平台的基石。
Java 程序运行的时候,编译器会将 Java 源代码(.java)编译成平台无关的 Java 字节码文件(.class),接下来对应平台的 JVM 会对字节码文件进行解释,翻译成对应平台的机器指令并运行。
任何可以通过 Java 编译的语言,比如说 Groovy、Kotlin、Scala 等,都可以在 JVM 上运行。
2.JVM的组织架构?
JVM(Java 虚拟机)的组织架构可以分为以下几个主要部分:
- 类加载器子系统(Class Loader Subsystem)
- 运行时数据区(Runtime Data Area)
- 执行引擎(Execution Engine)
- 本地方法接口(JNI - Java Native Interface)
1. 类加载器子系统(Class Loader Subsystem)
类加载器子系统负责加载 .class 文件,并将其转换为 JVM 可以执行的字节码。类加载器子系统包括以下几个部分:
- Bootstrap ClassLoader:引导类加载器,负责加载核心 Java 类库(如
rt.jar)。 - Extension ClassLoader:扩展类加载器,负责加载扩展类库(如
ext目录下的类库)。 - Application ClassLoader:应用类加载器,负责加载应用程序的类路径(classpath)下的类。
2. 运行时数据区(Runtime Data Area)
运行时数据区是 JVM 在执行 Java 程序时使用的内存区域,包括以下几个部分:
- 方法区(Method Area):存储类信息、常量、静态变量和即时编译器编译后的代码。
- 堆(Heap):存储所有对象实例和数组。堆是垃圾回收的主要区域。
- Java 栈(Java Stack):存储每个线程的局部变量、操作数栈和帧数据。每个线程都有自己的 Java 栈。
- 本地方法栈(Native Method Stack):存储本地方法调用的信息。
- 程序计数器(Program Counter Register):存储当前线程执行的字节码指令的地址。
3. 执行引擎(Execution Engine)
执行引擎负责解释和执行字节码指令。现代 JVM 通常包含即时编译器(JIT),将热点代码编译为本地机器码,以提高执行效率。执行引擎包括以下几个部分:
- 解释器(Interpreter):逐条解释执行字节码指令。
- 即时编译器(JIT Compiler):将热点代码编译为本地机器码,提高执行效率。
- 垃圾回收器(Garbage Collector):自动管理内存,通过垃圾回收机制回收不再使用的对象,防止内存泄漏。
4. 本地方法接口(JNI - Java Native Interface)
本地方法接口允许 Java 程序调用本地(非 Java)代码,如 C 或 C++ 编写的库。JNI 提供了一组 API,用于在 Java 和本地代码之间进行交互。
3.JVM内存结构
JVM 内存结构定义了 Java 程序在运行时使用的内存区域。主要包括以下几个部分:
- 方法区(Method Area)
- 堆(Heap)
- Java 栈(Java Stack)
- 本地方法栈(Native Method Stack)
- 程序计数器(Program Counter Register)
1. 方法区(Method Area)
- 存储内容:方法区存储类信息、常量、静态变量和即时编译器编译后的代码。
- 特点:方法区是线程共享的区域,所有线程都可以访问其中的数据。
- 用途:主要用于存储类的结构信息(如字段、方法、接口等)、常量池、方法数据和方法代码。
2. 堆(Heap)
- 存储内容:堆存储所有对象实例和数组。
- 特点:堆是线程共享的区域,所有线程都可以访问其中的数据。
- 用途:堆是垃圾回收的主要区域,JVM 使用垃圾回收机制来管理堆内存,回收不再使用的对象。
3. Java 栈(Java Stack)
- 存储内容:Java 栈存储每个线程的局部变量、操作数栈和帧数据。
- 特点:每个线程都有自己的 Java 栈,栈中的数据对其他线程不可见。
- 用途:每次方法调用都会创建一个新的栈帧,栈帧中包含了方法的局部变量表、操作数栈、动态链接和方法返回地址。
4. 本地方法栈(Native Method Stack)
- 存储内容:本地方法栈存储本地方法调用的信息。
- 特点:每个线程都有自己的本地方法栈,栈中的数据对其他线程不可见。
- 用途:用于支持本地方法的执行,存储本地方法调用的状态。
5. 程序计数器(Program Counter Register)
- 存储内容:程序计数器存储当前线程执行的字节码指令的地址。
- 特点:每个线程都有自己的程序计数器,计数器中的数据对其他线程不可见。
- 用途:用于记录当前线程执行的字节码指令地址,当线程切换时,可以通过程序计数器恢复到正确的执行位置。
6.内存结构图示
+------------------+
| 方法区 |
| (Method Area) |
+------------------+
| 堆 |
| (Heap) |
+------------------+
| Java 栈 |
| (Java Stack) |
+------------------+
| 本地方法栈 |
| (Native Method |
| Stack) |
+------------------+
| 程序计数器 |
| (Program Counter |
| Register) |
+------------------+
6.总结-3
- 方法区:存储类信息、常量、静态变量和即时编译器编译后的代码,是线程共享的区域。
- 堆:存储所有对象实例和数组,是线程共享的区域,垃圾回收的主要区域。
- Java 栈:存储每个线程的局部变量、操作数栈和帧数据,每个线程都有自己的 Java 栈。
- 本地方法栈:存储本地方法调用的信息,每个线程都有自己的本地方法栈。
- 程序计数器:存储当前线程执行的字节码指令的地址,每个线程都有自己的程序计数器。
JVM 内存结构确保了 Java 程序的高效执行和内存管理,通过垃圾回收机制自动管理内存,防止内存泄漏。
4.说一下 JDK1.6、1.7、1.8 内存区域的变化?
在不同版本的 JDK 中,JVM 内存区域的实现和管理方式有所变化,特别是在方法区和永久代(PermGen)方面。
JDK 1.6
- 方法区(Method Area):方法区在 JDK 1.6 中被实现为永久代(PermGen)。
- 永久代(PermGen):永久代用于存储类信息、常量、静态变量和即时编译器编译后的代码。永久代的大小是固定的,可以通过
-XX:PermSize和-XX:MaxPermSize参数进行配置。 - 堆(Heap):堆用于存储所有对象实例和数组,是垃圾回收的主要区域。
- Java 栈(Java Stack):每个线程都有自己的 Java 栈,存储局部变量、操作数栈和帧数据。
- 本地方法栈(Native Method Stack):存储本地方法调用的信息。
- 程序计数器(Program Counter Register):存储当前线程执行的字节码指令的地址。
JDK 1.7
- 方法区(Method Area):方法区仍然被实现为永久代(PermGen),但 JDK 1.7 开始逐步移除永久代中的一些内容。
- 永久代(PermGen):JDK 1.7 中,字符串常量池从永久代移到了堆中。这是为了减少永久代的内存压力,因为永久代的大小是固定的。
- 堆(Heap):堆用于存储所有对象实例和数组,是垃圾回收的主要区域。
- Java 栈(Java Stack):每个线程都有自己的 Java 栈,存储局部变量、操作数栈和帧数据。
- 本地方法栈(Native Method Stack):存储本地方法调用的信息。
- 程序计数器(Program Counter Register):存储当前线程执行的字节码指令的地址。
JDK 1.8
- 方法区(Method Area):方法区在 JDK 1.8 中被实现为元空间(Metaspace)。
- 元空间(Metaspace):元空间取代了永久代,用于存储类信息、常量、静态变量和即时编译器编译后的代码。元空间使用本地内存(Native Memory),其大小可以通过
-XX:MetaspaceSize和-XX:MaxMetaspaceSize参数进行配置。 - 堆(Heap):堆用于存储所有对象实例和数组,是垃圾回收的主要区域。
- Java 栈(Java Stack):每个线程都有自己的 Java 栈,存储局部变量、操作数栈和帧数据。
- 本地方法栈(Native Method Stack):存储本地方法调用的信息。
- 程序计数器(Program Counter Register):存储当前线程执行的字节码指令的地址。
主要变化
- 永久代(PermGen)到元空间(Metaspace):
- JDK 1.6 和 JDK 1.7:方法区被实现为永久代(PermGen),用于存储类信息、常量、静态变量和即时编译器编译后的代码。JDK 1.7 中,字符串常量池从永久代移到了堆中。
- JDK 1.8:永久代被移除,取而代之的是元空间(Metaspace)。元空间使用本地内存(Native Memory),其大小可以动态调整,减少了内存溢出的风险。
- 字符串常量池:
- JDK 1.6:字符串常量池位于永久代中。
- JDK 1.7 和 JDK 1.8:字符串常量池被移到了堆中。
配置参数变化
- JDK 1.6 和 JDK 1.7:
-XX:PermSize:设置永久代的初始大小。-XX:MaxPermSize:设置永久代的最大大小。
- JDK 1.8:
-XX:MetaspaceSize:设置元空间的初始大小。-XX:MaxMetaspaceSize:设置元空间的最大大小。
总结-4
- JDK 1.6:方法区被实现为永久代,字符串常量池位于永久代中。
- JDK 1.7:开始逐步移除永久代中的一些内容,字符串常量池被移到了堆中。
- JDK 1.8:永久代被移除,取而代之的是元空间,元空间使用本地内存,字符串常量池位于堆中。
这些变化主要是为了改进内存管理,减少内存溢出的风险,并提高 JVM 的性能和稳定性。
5.JDK 1.8 中的元空间(Metaspace)相对于永久代(PermGen)的优势?
在 JDK 1.8 中,元空间(Metaspace)取代了永久代(PermGen),用于存储类信息、常量、静态变量和即时编译器编译后的代码。元空间相对于永久代有以下几个主要优势:
1. 使用本地内存
- 永久代(PermGen):使用的是 JVM 堆内存,大小是固定的,可以通过
-XX:PermSize和-XX:MaxPermSize参数进行配置。 - 元空间(Metaspace):使用的是本地内存(Native Memory),其大小可以动态调整。默认情况下,元空间的大小是无限制的,可以通过
-XX:MetaspaceSize和-XX:MaxMetaspaceSize参数进行配置。
优势:使用本地内存可以避免永久代内存不足的问题,减少了 OutOfMemoryError: PermGen space 错误的发生。
2. 动态调整大小
- 永久代(PermGen):大小是固定的,必须在启动时配置,运行时无法调整。
- 元空间(Metaspace):大小可以动态调整,JVM 会根据需要自动扩展或收缩元空间的大小。
优势:动态调整大小使得内存管理更加灵活,能够更好地适应不同应用的需求,减少内存浪费。
3. 更好的垃圾回收性能
- 永久代(PermGen):由于永久代是堆的一部分,垃圾回收器在进行垃圾回收时需要扫描永久代,增加了垃圾回收的开销。
- 元空间(Metaspace):元空间使用本地内存,垃圾回收器不需要扫描元空间,从而减少了垃圾回收的开销,提高了垃圾回收的性能。
优势:减少了垃圾回收的开销,提高了垃圾回收的效率,从而提高了应用程序的性能。
4. 减少内存泄漏风险
- 永久代(PermGen):由于永久代的大小是固定的,如果应用程序加载了大量的类或生成了大量的字符串常量,可能会导致永久代内存不足,从而引发内存泄漏。
- 元空间(Metaspace):由于元空间的大小可以动态调整,能够更好地适应不同应用的需求,减少了内存泄漏的风险。
优势:减少了内存泄漏的风险,提高了应用程序的稳定性。
5.总结-5
- 使用本地内存:元空间使用本地内存,避免了永久代内存不足的问题。
- 动态调整大小:元空间的大小可以动态调整,内存管理更加灵活。
- 更好的垃圾回收性能:元空间减少了垃圾回收的开销,提高了垃圾回收的效率。
- 减少内存泄漏风险:元空间减少了内存泄漏的风险,提高了应用程序的稳定性。
元空间相对于永久代具有显著的优势,使得 JVM 的内存管理更加高效和灵活,提高了应用程序的性能和稳定性。
6.对象的创建销毁的过程?
对象创建
类加载检查:
JVM 首先检查类是否已经加载、链接和初始化。如果类没有加载,JVM 会通过类加载器加载类文件,并进行链接和初始化。
分配内存:
JVM 在堆中为新对象分配内存。分配内存的方式有两种:指针碰撞(Bump-the-pointer)和空闲列表(Free-list)。具体使用哪种方式取决于堆是否规整。
①、指针碰撞(Bump the Pointer)
假设堆内存是一个连续的空间,分为两个部分,一部分是已经被使用的内存,另一部分是未被使用的内存。
在分配内存时,Java 虚拟机维护一个指针,指向下一个可用的内存地址,每次分配内存时,只需要将指针向后移动(碰撞)一段距离,然后将这段内存分配给对象实例即可。
②、空闲列表(Free List)
JVM 维护一个列表,记录堆中所有未占用的内存块,每个空间块都记录了大小和地址信息。
当有新的对象请求内存时,JVM 会遍历空闲列表,寻找足够大的空间来存放新对象。
分配后,如果选中的空闲块未被完全利用,剩余的部分会作为一个新的空闲块加入到空闲列表中。
指针碰撞适用于管理简单、碎片化较少的内存区域(如年轻代),而空闲列表适用于内存碎片化较严重或对象大小差异较大的场景(如老年代)。
初始化默认值:
JVM 将分配的内存区域初始化为默认值(零值),确保对象的实例字段在初始状态下是确定的。
设置对象头:
JVM 设置对象头,包括对象的元数据(如类信息)和哈希码等。
执行构造方法:
JVM 调用对象的构造方法(<init> 方法),执行对象的初始化代码。
对象销毁
对象变为不可达:
当对象不再被任何活动线程引用时,对象变为不可达。不可达的对象会被标记为垃圾回收的候选对象。
垃圾回收(Garbage Collection):
JVM 的垃圾回收器会定期扫描堆,标记和回收不可达的对象。垃圾回收的具体算法有多种,如标记-清除(Mark-Sweep)、标记-整理(Mark-Compact)和复制算法(Copying)。
调用 finalize 方法(已废弃):
在 JDK 9 之前,JVM 会在对象被回收前调用其 finalize 方法。finalize 方法允许对象在被回收前执行一些清理操作。然而,finalize 方法存在很多问题,如不确定性和性能开销,因此在 JDK 9 之后被废弃。
释放内存:
垃圾回收器回收对象的内存,将其返回给堆,以便分配给新的对象。
7.JVM 里 new 对象时,堆会发生抢占吗?JVM 是怎么设计来保证线程安全的?
会,假设 JVM 虚拟机上,每一次 new 对象时,指针就会向右移动一个对象 size 的距离,一个线程正在给 A 对象分配内存,指针还没有来的及修改,另一个为 B 对象分配内存的线程,又引用了这个指针来分配内存,这就发生了抢占。
对象创建的线程安全机制
线程本地分配缓冲区(TLAB - Thread Local Allocation Buffer):
JVM 为每个线程分配一个私有的内存区域,称为线程本地分配缓冲区(TLAB)。当一个线程需要分配内存时,首先尝试在自己的 TLAB 中分配。如果 TLAB 中有足够的空间,内存分配可以在没有锁竞争的情况下完成。
当 TLAB 中的空间不足时,线程会请求 JVM 在堆中分配新的 TLAB。如果堆中没有足够的空间,JVM 会进行垃圾回收以释放内存。
同步机制:
当多个线程需要在堆中分配内存时,JVM 使用同步机制来确保线程安全。具体来说,JVM 使用 CAS(Compare-And-Swap)操作和锁来保证内存分配的原子性。
CAS 操作是一种无锁的并发编程技术,通过比较和交换操作来保证数据的一致性。在大多数情况下,CAS 操作比锁机制更高效,因为它避免了线程的阻塞和上下文切换。
8.对象的内存布局,对象的底层数据结构?
在 JVM 中,Java 对象的底层数据结构主要包括以下几个部分:
- 对象头(Header)
- 实例数据(Instance Data)
- 对齐填充(Padding)
1. 对象头(Header)
对象头是每个对象在内存中的开销部分,包含了对象的元数据。对象头通常包括以下两个部分:
- 标记字(Mark Word):
- 存储对象的运行时数据,如哈希码(HashCode)、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID 等。
- Mark Word 的长度在 32 位和 64 位 JVM 中是不同的。在 32 位 JVM 中,Mark Word 通常是 32 位;在 64 位 JVM 中,Mark Word 通常是 64 位。在 64 位操作系统下占 8 个字节,32 位操作系统下占 4 个字节。
- 类型指针(Class Pointer):
- 指向对象的类元数据(Class Metadata),JVM 通过这个指针找到对象的类信息。
- 在 32 位和 64 位 JVM 中,Class Pointer 的长度分别是 32 位和 64 位。
- 在开启了压缩指针的情况下,这个指针可以被压缩。在开启指针压缩的情况下占 4 个字节,否则占 8 个字节。
- 数组长度(ArrayLength) :
- 如果对象是数组类型,还会有一个额外的数组长度字段。占 4 个字节。
2. 实例数据(Instance Data)
实例数据部分存储对象的实际字段值,包括所有的实例变量(包括从父类继承的变量)。实例数据的布局和顺序通常由编译器决定,具体顺序可能会根据字段的类型和访问权限进行优化。
- 基本类型字段:如
int、long、char等。 - 引用类型字段:如对象引用、数组引用等。
3. 对齐填充(Padding)
为了提高内存访问的效率,JVM 要求对象的大小是某个特定字节数的倍数(通常是 8 字节)。如果对象的实例数据部分没有对齐,JVM 会在对象的末尾添加填充字节(Padding),以确保对象的大小满足对齐要求。
以下是一个简单的 Java 类,展示了对象的内存布局:
public class MyObject {
int a; // 4 bytes
long b; // 8 bytes
char c; // 2 bytes
Object ref; // 4 bytes (32-bit JVM) or 8 bytes (64-bit JVM)
}
内存布局示意图
假设在 32 位 JVM 中,MyObject 的内存布局如下:
+-----------------+-----------------+
| 对象头 | Mark Word | 4 bytes
+-----------------+-----------------+
| Class Pointer | | 4 bytes
+-----------------+-----------------+
| a | | 4 bytes
+-----------------+-----------------+
| b | | 8 bytes
+-----------------+-----------------+
| c | | 2 bytes
+-----------------+-----------------+
| ref | | 4 bytes
+-----------------+-----------------+
| Padding | | 2 bytes (to align to 8 bytes)
+-----------------+-----------------+
总结-8
- 对象头(Header):包含 Mark Word 和 Class Pointer,用于存储对象的元数据和类信息。
- 实例数据(Instance Data):存储对象的实际字段值,包括基本类型字段和引用类型字段。
- 对齐填充(Padding):用于确保对象的大小满足对齐要求,提高内存访问的效率。
对象的内存布局是 JVM 内存管理的重要组成部分,通过合理的内存布局和对齐策略,JVM 能够提高内存访问的效率和程序的性能。
9.对象如何访问定位?
在 JVM 中,对象的访问定位主要依赖于对象引用和对象在内存中的布局。JVM 使用两种主要的方式来访问和定位对象:
- 句柄访问(Handle Access)
- 直接指针访问(Direct Pointer Access)
1. 句柄访问(Handle Access)
在句柄访问方式中,JVM 会为每个对象分配一个句柄。句柄是一个固定大小的内存块,包含了对象实例数据和对象类型数据的指针。对象引用指向句柄,而不是直接指向对象实例数据。
- 句柄结构:
- 句柄指针:对象引用指向句柄。
- 句柄内容:句柄包含两个指针,一个指向对象实例数据,一个指向对象类型数据(类元数据)。
- 优点:
- 对象在内存中的移动不会影响对象引用,因为引用指向的是句柄,句柄中的指针可以更新。
- 适用于需要频繁移动对象的垃圾回收算法。
- 缺点:
- 访问对象时需要两次内存间接访问(一次访问句柄,一次访问对象实例数据),性能略低。
2. 直接指针访问(Direct Pointer Access)
在直接指针访问方式中,对象引用直接指向对象实例数据。对象实例数据包含对象头和实例字段。
- 直接指针结构:
- 对象引用:直接指向对象实例数据。
- 对象实例数据:包含对象头和实例字段。
- 优点:
- 访问对象时只需要一次内存间接访问,性能较高。
- 适用于对象较少移动的垃圾回收算法。
- 缺点:
- 对象在内存中的移动需要更新所有引用该对象的指针,增加了垃圾回收的复杂性。
HotSpot 虚拟机主要使用直接指针来进行对象访问。
10.说说内存溢出(OOM)和内存泄漏(Leak Memory)的原因?
内存溢出是什么
在 Java 中,OOM(OutOfMemoryError)错误表示 JVM 无法再为应用程序分配所需的内存。OOM 错误可能发生在以下几个内存区域:
- 堆内存(Heap Memory)
- 方法区(Method Area)/元空间(Metaspace)
- 栈内存(Stack Memory)
- 直接内存(Direct Memory)
1. 堆内存(Heap Memory)
描述:
- 堆内存用于存储所有对象实例和数组,是垃圾回收的主要区域。
OOM 发生原因:
- 对象过多:应用程序创建了过多的对象,导致堆内存耗尽。
- 内存泄漏:对象不再被使用,但仍然被引用,导致垃圾回收器无法回收这些对象。
- 大对象分配:尝试分配一个非常大的对象,超过了堆内存的最大限制。
示例:
public class HeapOOM {
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
while (true) {
list.add(new Object());
}
}
}
2. 方法区(Method Area)/元空间(Metaspace)
描述:
- 方法区在 JDK 1.8 之前被实现为永久代(PermGen),在 JDK 1.8 之后被实现为元空间(Metaspace)。方法区用于存储类信息、常量、静态变量和即时编译器编译后的代码。
OOM 发生原因:
- 类加载过多:动态生成大量类,导致方法区或元空间耗尽。
- 常量池过大:大量字符串常量或其他常量,导致常量池耗尽。
示例:
public class MetaspaceOOM {
public static void main(String[] args) {
while (true) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(OOMObject.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
return proxy.invokeSuper(obj, args);
}
});
enhancer.create();
}
}
}
3. 栈内存(Stack Memory)
描述:
- 栈内存用于存储每个线程的局部变量、操作数栈和帧数据。每个线程都有自己的栈内存。
OOM 发生原因:
- 栈帧过多:递归调用过深或方法调用层次过多,导致栈内存耗尽。
- 线程过多:创建了过多的线程,每个线程都需要分配栈内存,导致栈内存耗尽。
示例:
public class StackOverflow {
public static void main(String[] args) {
recursiveCall();
}
public static void recursiveCall() {
recursiveCall();
}
}
4. 直接内存(Direct Memory)
描述:
- 直接内存是 JVM 之外的内存区域,通过
java.nio包中的ByteBuffer类进行分配和管理。
OOM 发生原因:
- 直接内存分配过多:分配了过多的直接内存,超过了系统的限制。
示例:
public class DirectMemoryOOM {
private static final int _1MB = 1024 * 1024;
public static void main(String[] args) throws Exception {
List<ByteBuffer> buffers = new ArrayList<>();
while (true) {
buffers.add(ByteBuffer.allocateDirect(_1MB));
}
}
}
总结-10-1
- 堆内存(Heap Memory):对象过多、内存泄漏、大对象分配。
- 方法区(Method Area)/元空间(Metaspace):类加载过多、常量池过大。
- 栈内存(Stack Memory):栈帧过多、线程过多。
- 直接内存(Direct Memory):直接内存分配过多。
OOM 错误通常是由于内存分配超过了 JVM 或系统的限制,了解这些内存区域及其可能的 OOM 原因,有助于在开发和调试过程中更好地管理和优化内存使用。
内存泄漏可能由哪些原因导致呢?
内存泄漏可能的原因有很多种,比如说静态集合类引起内存泄漏、单例模式、数据连接、IO、Socket 等连接、变量不合理的作用域、hash 值发生变化、ThreadLocal 使用不当等。
①、静态集合类引起内存泄漏:
静态集合的生命周期和 JVM 一致,所以静态集合引用的对象不能被释放。
public class OOM {
static List list = new ArrayList();
public void oomTests(){
Object obj = new Object();
list.add(obj);
}
}
②、单例模式:
和上面的例子原理类似,单例对象在初始化后会以静态变量的方式在 JVM 的整个生命周期中存在。如果单例对象持有外部的引用,那么这个外部对象将不能被 GC 回收,导致内存泄漏。
③、数据连接、IO、Socket 等连接:
创建的连接不再使用时,需要调用 close 方法关闭连接,只有连接被关闭后,GC 才会回收对应的对象(Connection,Statement,ResultSet,Session)。忘记关闭这些资源会导致持续占有内存,无法被 GC 回收。
try {
Connection conn = null;
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("url", "", "");
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("....");
} catch (Exception e) {
}finally {
//不关闭连接
}
④、变量不合理的作用域:
一个变量的定义作用域大于其使用范围,很可能存在内存泄漏;或不再使用对象没有及时将对象设置为 null,很可能导致内存泄漏的发生。
public class Simple {
Object object;
public void method1(){
object = new Object();
//...其他代码
//由于作用域原因,method1执行完成之后,object 对象所分配的内存不会马上释放
object = null;
}
}
⑤、hash 值发生变化:
对象 Hash 值改变,使用 HashMap、HashSet 等容器中时候,由于对象修改之后的 Hah 值和存储进容器时的 Hash 值不同,所以无法找到存入的对象,自然也无法单独删除了,这也会造成内存泄漏。说句题外话,这也是为什么 String 类型被设置成了不可变类型。
⑥、ThreadLocal 使用不当:
ThreadLocal 的弱引用导致内存泄漏也是个老生常谈的话题了(键是弱引用会回收,但是值是强引用),使用完 ThreadLocal 一定要记得使用 remove 方法来进行清除。
11.Java 堆的内存分区了解吗?
Java 堆是 JVM 内存管理的重要组成部分,用于存储所有对象实例和数组。为了提高垃圾回收的效率,Java 堆通常被划分为几个不同的区域,每个区域有不同的用途和垃圾回收策略。主要的内存分区包括:
- 新生代(Young Generation)
- 老年代(Old Generation)
- 永久代(PermGen)/元空间(Metaspace)
1. 新生代(Young Generation)
新生代用于存储新创建的对象。新生代进一步划分为三个区域:
- Eden 区:大部分新对象在 Eden 区分配。当 Eden 区满时,会触发一次 Minor GC,将存活的对象移动到 Survivor 区。
- Survivor 区:新生代包含两个 Survivor 区,分别称为 S0(From)和 S1(To)。每次 Minor GC 后,存活的对象会在两个 Survivor 区之间复制和交换。一个 Survivor 区是空的,另一个 Survivor 区存储存活的对象。
垃圾回收:
- Minor GC:新生代的垃圾回收称为 Minor GC,频率较高,但速度较快。Minor GC 主要回收 Eden 区和一个 Survivor 区的对象。
2. 老年代(Old Generation)
老年代用于存储生命周期较长的对象。经过多次 Minor GC 仍然存活的对象会被移动到老年代。老年代的空间通常比新生代大,垃圾回收的频率较低,但回收时间较长。
垃圾回收:
- Major GC / Full GC:老年代的垃圾回收称为 Major GC 或 Full GC,频率较低,但速度较慢。Full GC 会回收整个堆,包括新生代和老年代。
3. 永久代(PermGen)/元空间(Metaspace)
永久代和元空间用于存储类信息、常量、静态变量和即时编译器编译后的代码。
- 永久代(PermGen):在 JDK 1.8 之前,永久代用于存储类元数据。永久代的大小是固定的,可以通过
-XX:PermSize和-XX:MaxPermSize参数进行配置。 - 元空间(Metaspace):在 JDK 1.8 之后,永久代被移除,取而代之的是元空间。元空间使用本地内存(Native Memory),其大小可以动态调整,可以通过
-XX:MetaspaceSize和-XX:MaxMetaspaceSize参数进行配置。
内存分区示意图
+------------------+
| 堆 |
| +--------------+ |
| | 新生代 | |
| | +----------+ | |
| | | Eden | | |
| | +----------+ | |
| | | Survivor | | |
| | | S0 | | |
| | +----------+ | |
| | | Survivor | | |
| | | S1 | | |
| | +----------+ | |
| +--------------+ |
| +--------------+ |
| | 老年代 | |
| +--------------+ |
+------------------+
+------------------+
| 永久代/元空间 |
+------------------+
总结-11
- 新生代(Young Generation):用于存储新创建的对象,进一步划分为 Eden 区和两个 Survivor 区。主要通过 Minor GC 进行垃圾回收。
- 老年代(Old Generation):用于存储生命周期较长的对象。主要通过 Major GC 或 Full GC 进行垃圾回收。
- 永久代(PermGen)/元空间(Metaspace):用于存储类信息、常量、静态变量和即时编译器编译后的代码。在 JDK 1.8 之前为永久代,之后为元空间。
通过合理的内存分区和垃圾回收策略,JVM 能够高效地管理内存,确保应用程序的性能和稳定性。
12.对象什么时候会进入老年代?
在 Java 的垃圾回收机制中,对象从新生代(Young Generation)移动到老年代(Old Generation)的过程称为对象晋升(Promotion)。对象进入老年代的主要情况如下:
1. 对象年龄达到阈值
- 对象年龄:每个对象在新生代中存活的时间被称为对象年龄。每次 Minor GC 后,存活的对象会在 Eden 区和 Survivor 区之间复制和交换,对象的年龄会增加。
- 年龄阈值:当对象的年龄达到某个阈值(默认是 15,可以通过
-XX:MaxTenuringThreshold参数配置)时,对象会被晋升到老年代。
2. Survivor 区空间不足
- Survivor 区空间不足:如果在进行 Minor GC 时,Survivor 区没有足够的空间来存放存活的对象,这些对象会直接晋升到老年代。
- 动态年龄判定:JVM 可能会根据 Survivor 区的使用情况动态调整对象晋升的年龄阈值,以优化内存使用。
3. 大对象直接进入老年代
- 大对象:一些大对象(如大数组、大字符串等)可能会直接分配到老年代,以避免在新生代中频繁复制和移动。
- 大对象阈值:可以通过
-XX:PretenureSizeThreshold参数配置大对象的阈值,超过该阈值的对象会直接分配到老年代。
4. 新生代空间不足
- 新生代空间不足:如果新生代的空间不足以容纳新创建的对象,JVM 会触发 Minor GC。如果在 Minor GC 后,新生代仍然没有足够的空间,部分存活的对象会被晋升到老年代。
以下是一个简单的 Java 示例,展示了对象晋升到老年代的过程:
public class ObjectPromotionExample {
private static final int _1MB = 1024 * 1024;
public static void main(String[] args) {
byte[] allocation1, allocation2, allocation3;
allocation1 = new byte[2 * _1MB];
allocation2 = new byte[2 * _1MB];
allocation3 = new byte[4 * _1MB]; // 触发 Minor GC
}
}
在上述代码中,allocation3 的分配会触发一次 Minor GC,如果 allocation1 和 allocation2 存活且 Survivor 区空间不足,它们可能会被晋升到老年代。
总结-12
- 对象年龄达到阈值:对象在新生代中存活的时间达到某个阈值时,会被晋升到老年代。
- Survivor 区空间不足:在进行 Minor GC 时,如果 Survivor 区没有足够的空间存放存活的对象,这些对象会被晋升到老年代。
- 大对象直接进入老年代:一些大对象可能会直接分配到老年代,以避免在新生代中频繁复制和移动。
- 新生代空间不足:如果新生代空间不足以容纳新创建的对象,部分存活的对象会被晋升到老年代。
通过合理的内存管理和垃圾回收策略,JVM 能够高效地管理对象的生命周期,确保应用程序的性能和稳定性。
13.什么是 Stop The World ? 什么是 OopMap ?什么是安全点?
Stop The World (STW)
Stop The World (STW) 是指在垃圾回收过程中,JVM 会暂停所有应用程序线程的执行,以便进行垃圾回收操作。这种暂停是全局性的,所有的应用程序线程都会被挂起,直到垃圾回收完成。
特点:
- 全局暂停:所有应用程序线程都会被暂停,只有垃圾回收线程在运行。
- 暂停时间:暂停时间取决于垃圾回收算法和堆的大小。对于一些垃圾回收算法(如 Full GC),暂停时间可能会较长。
- 影响:STW 会影响应用程序的响应时间和性能,特别是在大堆内存和长时间暂停的情况下。
OopMap
OopMap 是 JVM 中的一种数据结构,用于记录对象引用的位置。OopMap 在垃圾回收过程中起到了关键作用,帮助垃圾回收器快速找到对象引用,以便进行标记和回收。
特点:
- 记录引用位置:OopMap 记录了每个栈帧和寄存器中对象引用的位置。
- 生成时机:JVM 在编译字节码时生成 OopMap,并在方法调用和返回、异常处理等关键点更新 OopMap。
- 作用:在垃圾回收过程中,OopMap 帮助垃圾回收器快速找到对象引用,避免全堆扫描,提高垃圾回收效率。
安全点(Safepoint)
安全点(Safepoint) 是指 JVM 在执行过程中,能够安全地暂停所有应用程序线程的特定位置。垃圾回收器需要在安全点暂停线程,以确保线程在一致的状态下进行垃圾回收。
特点:
- 特定位置:安全点通常设置在方法调用、循环回边和异常处理等位置。
- 线程一致性:在安全点暂停线程,确保线程在一致的状态下进行垃圾回收。
- 触发机制:当垃圾回收器需要进行 STW 操作时,会触发安全点,暂停所有应用程序线程。
以下是一个简单的 Java 示例,展示了垃圾回收过程中可能涉及的 STW、OopMap 和安全点:
public class StopTheWorldExample {
public static void main(String[] args) {
for (int i = 0; i < 100000; i++) {
allocateMemory();
}
}
private static void allocateMemory() {
byte[] array = new byte[1024 * 1024]; // 分配 1MB 内存
}
}
在上述代码中,allocateMemory 方法会频繁分配内存,可能会触发垃圾回收。在垃圾回收过程中,JVM 会暂停所有应用程序线程(STW),使用 OopMap 记录对象引用的位置,并在安全点暂停线程。
总结-13
- Stop The World (STW):在垃圾回收过程中,JVM 会暂停所有应用程序线程的执行,以便进行垃圾回收操作。
- OopMap:一种数据结构,用于记录对象引用的位置,帮助垃圾回收器快速找到对象引用,提高垃圾回收效率。
- 安全点(Safepoint):JVM 在执行过程中能够安全地暂停所有应用程序线程的特定位置,确保线程在一致的状态下进行垃圾回收。
通过合理的垃圾回收策略和机制,JVM 能够高效地管理内存,确保应用程序的性能和稳定性。
14.对象一定分配在堆中吗?有没有了解逃逸分析技术?
对象一定分配在堆中吗?
在 Java 中,通常情况下,对象是分配在堆内存中的。然而,通过一些优化技术,特别是逃逸分析(Escape Analysis),对象也可以在栈上分配,从而减少堆内存的使用和垃圾回收的开销。
逃逸分析(Escape Analysis)
逃逸分析是一种编译时优化技术,用于确定对象的动态作用域。通过逃逸分析,JVM 可以判断对象是否会逃逸出方法或线程的作用域,从而决定对象的分配位置。
逃逸分析的类型
- 方法逃逸(Method Escape):
- 如果对象在方法外部被引用,则认为对象发生了方法逃逸。
- 例如,将对象作为参数传递给其他方法,或者将对象赋值给类的成员变量。
- 线程逃逸(Thread Escape):
- 如果对象在方法外部被其他线程引用,则认为对象发生了线程逃逸。
- 例如,将对象作为参数传递给其他线程,或者将对象存储在共享数据结构中。
逃逸分析的优化
- 栈上分配(Stack Allocation):
- 如果对象没有发生逃逸,JVM 可以将对象分配在栈上,而不是堆中。这样,当方法执行完毕时,对象会自动销毁,无需垃圾回收。
- 优点:减少堆内存的使用,降低垃圾回收的频率和开销。
- 标量替换(Scalar Replacement):
- 如果对象没有发生逃逸,且对象的字段可以被拆分为标量变量,JVM 可以将对象的字段直接分配在栈上,而不是创建对象。
- 优点:进一步减少内存分配和垃圾回收的开销。
- 同步消除(Synchronization Elimination):
- 如果对象没有发生线程逃逸,JVM 可以消除对象上的同步操作,从而提高并发性能。
- 优点:减少不必要的同步开销,提高程序的并发性能。
以下是一个简单的 Java 示例,展示了逃逸分析的应用:
public class EscapeAnalysisExample {
public static void main(String[] args) {
for (int i = 0; i < 1000000; i++) {
allocateMemory();
}
}
private static void allocateMemory() {
Point p = new Point(1, 2); // 可能在栈上分配
System.out.println(p);
}
}
class Point {
int x, y;
Point(int x, int y) {
this.x = x;
this.y = y;
}
@Override
public String toString() {
return "Point{" + "x=" + x + ", y=" + y + '}';
}
}
在上述代码中,Point 对象在 allocateMemory方法中创建。如果 JVM 通过逃逸分析确定 Point 对象没有发生逃逸,则可以将其分配在栈上,而不是堆中。
总结-14
- 对象分配位置:通常情况下,对象分配在堆中。然而,通过逃逸分析,JVM 可以将未逃逸的对象分配在栈上,从而减少堆内存的使用和垃圾回收的开销。
- 逃逸分析:一种编译时优化技术,用于确定对象的动态作用域,判断对象是否会逃逸出方法或线程的作用域。
- 优化技术:
- 栈上分配:将未逃逸的对象分配在栈上。
- 标量替换:将未逃逸对象的字段拆分为标量变量,直接分配在栈上。
- 同步消除:消除未发生线程逃逸对象上的同步操作。
通过逃逸分析和相关优化技术,JVM 能够提高内存管理的效率,减少垃圾回收的开销,从而提高应用程序的性能。
15.JVM垃圾回收机制?
垃圾回收(Garbage Collection, GC)是 JVM 自动管理内存的一种机制,用于回收不再使用的对象所占用的内存空间。GC 的主要目标是释放无用对象的内存,防止内存泄漏和内存溢出,从而提高应用程序的性能和稳定性。
对象回收判定
在 JVM 中,判断对象是否存活是垃圾回收的核心任务。主要有两种方法来判断对象是否存活:
- 引用计数法(Reference Counting)
- 可达性分析法(Reachability Analysis)
1. 引用计数法(Reference Counting)
描述:
- 每个对象维护一个引用计数器,记录有多少引用指向该对象。
- 当一个新的引用指向该对象时,引用计数器加一;当一个引用不再指向该对象时,引用计数器减一。
- 当引用计数器为零时,表示该对象不再被引用,可以被回收。
优点:
- 实现简单,判断对象是否存活的时间复杂度为 O(1)。
缺点:
- 无法处理循环引用的问题。例如,两个对象互相引用,但它们不再被其他对象引用,引用计数器永远不会为零,导致内存泄漏。
2. 可达性分析法(Reachability Analysis)
描述:
- 从根对象(GC Roots)开始,沿着引用链遍历对象,标记所有可达的对象。
- 未被标记的对象即为不可达,可以被回收。
GC Roots:
- 栈中的引用(如局部变量、方法参数等)
- 静态字段引用
- 常量池中的引用
- JNI(Java Native Interface)引用
优点:
- 能够正确处理循环引用的问题。
缺点:
- 实现复杂,遍历对象图的时间复杂度较高。
以下是一个简单的 Java 示例,展示了对象的可达性分析:
public class GCRootsExample {
private static GCRootsExample staticField;
private GCRootsExample instanceField;
public static void main(String[] args) {
GCRootsExample obj1 = new GCRootsExample();
staticField = obj1; // 静态字段作为 GC Roots
GCRootsExample obj2 = new GCRootsExample();
obj1.instanceField = obj2; // 实例字段引用
obj2 = null; // obj2 不再引用 GCRootsExample 对象
System.gc(); // 触发垃圾回收
}
}
在上述代码中,staticField 和 instanceField 作为 GC Roots,obj1 和 obj2 的可达性由 GC Roots 判断。
总结-15-1
- 引用计数法(Reference Counting):每个对象维护一个引用计数器,记录有多少引用指向该对象。当引用计数器为零时,表示对象不再被引用,可以被回收。缺点是无法处理循环引用的问题。
- 可达性分析法(Reachability Analysis):从根对象(GC Roots)开始,沿着引用链遍历对象,标记所有可达的对象。未被标记的对象即为不可达,可以被回收。优点是能够正确处理循环引用的问题。
垃圾回收算法
垃圾收集算法是 JVM 内存管理的重要组成部分,用于自动回收不再使用的对象所占用的内存空间。常见的垃圾收集算法包括:
- 标记-清除算法(Mark-Sweep)
- 复制算法(Copying)
- 标记-整理算法(Mark-Compact)
- 分代收集算法(Generational Collection)
1. 标记-清除算法(Mark-Sweep)
描述:
- 标记阶段:从根对象(GC Roots)开始,标记所有可达的对象。
- 清除阶段:遍历堆,回收未被标记的对象。
优点:
- 实现简单,能够处理大多数场景。
缺点:
- 清除阶段会产生内存碎片,影响内存分配效率。
2. 复制算法(Copying)
描述:
- 将内存划分为两个相等的区域(From 和 To)。
- 每次垃圾回收时,将存活的对象从 From 区复制到 To 区,未被复制的对象即为垃圾。
- 复制完成后,交换 From 和 To 的角色。
优点:
- 没有内存碎片,内存分配效率高。
缺点:
- 需要两倍的内存空间,内存利用率较低。
3. 标记-整理算法(Mark-Compact)
描述:
- 标记阶段:从根对象(GC Roots)开始,标记所有可达的对象。
- 整理阶段:将所有存活的对象压缩到堆的一端,清理掉边界以外的内存。
优点:
- 没有内存碎片,内存利用率高。
缺点:
- 整理阶段需要移动对象,开销较大。
4. 分代收集算法(Generational Collection)
描述:
- 将堆内存划分为新生代(Young Generation)和老年代(Old Generation)。
- 新生代使用复制算法,老年代使用标记-整理算法。
优点:
- 结合了复制算法和标记-整理算法的优点,能够高效地管理内存。
缺点:
- 实现复杂,需要调优。
总结-15-2
- 标记-清除算法(Mark-Sweep):标记所有可达的对象,清除未被标记的对象。缺点是会产生内存碎片。
- 复制算法(Copying):将存活的对象从一个区域复制到另一个区域,没有内存碎片,但内存利用率较低。
- 标记-整理算法(Mark-Compact):标记所有可达的对象,将存活的对象压缩到堆的一端,没有内存碎片,但需要移动对象。
- 分代收集算法(Generational Collection):将堆内存划分为新生代和老年代,结合了复制算法和标记-整理算法的优点,能够高效地管理内存。
垃圾回收类型
在 JVM 中,垃圾回收(GC)可以根据回收的内存区域和回收策略分为不同的类型。主要的垃圾回收类型包括:
- Minor GC / Young GC
- Major GC / Old GC
- Mixed GC
- Full GC
1. Minor GC / Young GC
描述:
- Minor GC 也称为 Young GC,主要针对新生代(Young Generation)进行垃圾回收。
- 新生代通常使用复制算法(Copying),将存活的对象从 Eden 区和一个 Survivor 区复制到另一个 Survivor 区。
触发条件:
- 当 Eden 区满时,会触发 Minor GC。
特点:
- 频率较高,但回收速度较快。
- 只回收新生代,不涉及老年代。
2. Major GC / Old GC
描述:
- Major GC 也称为 Old GC,主要针对老年代(Old Generation)进行垃圾回收。
- 老年代通常使用标记-整理算法(Mark-Compact),标记所有可达的对象,并将存活的对象压缩到堆的一端。
触发条件:
- 当老年代满时,会触发 Major GC。
特点:
- 频率较低,但回收速度较慢。
- 只回收老年代,不涉及新生代。
3. Mixed GC
描述:
- Mixed GC 是 G1 垃圾回收器的一种回收策略,回收新生代和部分老年代。
- G1 垃圾回收器将堆划分为多个区域(Region),Mixed GC 会同时回收新生代和一些老年代的区域。
触发条件:
- 当新生代满时,或者根据 G1 的回收策略触发。
特点:
- 结合了 Minor GC 和 Major GC 的优点,能够高效地管理内存。
- 回收范围更广,能够减少 Full GC 的频率。
4. Full GC
描述:
- Full GC 是一次全堆的垃圾回收,回收新生代、老年代和元空间(Metaspace)。
- Full GC 通常使用标记-整理算法(Mark-Compact)或标记-清除算法(Mark-Sweep)。
触发条件:
- 当堆内存不足,或者显式调用
System.gc()时,会触发 Full GC。
特点:
- 频率最低,但回收速度最慢。
- 暂停时间最长,对应用程序的性能影响最大。
总结-15-3
- Minor GC / Young GC:主要针对新生代进行垃圾回收,频率较高,但回收速度较快。
- Major GC / Old GC:主要针对老年代进行垃圾回收,频率较低,但回收速度较慢。
- Mixed GC:G1 垃圾回收器的一种回收策略,回收新生代和部分老年代,结合了 Minor GC 和 Major GC 的优点。
- Full GC:一次全堆的垃圾回收,回收新生代、老年代和元空间,频率最低,但回收速度最慢,对应用程序的性能影响最大。
垃圾收集器
JVM 提供了多种垃圾收集器,每种垃圾收集器都有其独特的特点和适用场景。以下是一些常见的垃圾收集器:
1. Serial 收集器
描述:
- Serial 收集器是最基本的垃圾收集器,使用单线程进行垃圾回收。
- 适用于单线程环境或小型应用。
特点:
- 简单高效,适用于单核 CPU。
- 在进行垃圾回收时,会暂停所有应用程序线程(Stop The World)。
适用场景:
- 单线程环境或小型应用。
2. ParNew 收集器
描述:
- ParNew 收集器是 Serial 收集器的多线程版本,使用多线程进行垃圾回收。
- 主要用于新生代的垃圾回收。
特点:
- 多线程并行回收,适用于多核 CPU。
- 与 CMS 收集器配合使用。
适用场景:
- 多线程环境,适用于新生代的垃圾回收。
3. Parallel 收集器
描述:
- Parallel 收集器也称为吞吐量收集器,使用多线程进行垃圾回收,主要关注吞吐量。
- 适用于新生代和老年代的垃圾回收。
-
吞吐量 = 运行用户代码的时间/(运行垃圾收集的时间+运行用户代码的时间) 特点:
- 多线程并行回收,适用于多核 CPU。
- 关注吞吐量,适用于后台计算等对响应时间要求不高的场景。
适用场景:
- 需要高吞吐量的应用,如后台计算、批处理等。
4. CMS 收集器
描述:
- CMS(Concurrent Mark-Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。
- 主要用于老年代的垃圾回收。
特点:
- 并发回收,减少停顿时间。
- 适用于对响应时间要求高的应用,如 Web 服务器。
- CMS(Concurrent Mark Sweep)主要使用了标记-清除算法进行垃圾收集,分 4 大步:
- 初始标记(Initial Mark):标记所有从 GC Roots 直接可达的对象,这个阶段需要 STW,但速度很快。
- 并发标记(Concurrent Mark):从初始标记的对象出发,遍历所有对象,标记所有可达的对象。这个阶段是并发进行的,STW。
- 重新标记(Remark):完成剩余的标记工作,包括处理并发阶段遗留下来的少量变动,这个阶段通常需要短暂的 STW 停顿。
- 并发清除(Concurrent Sweep):清除未被标记的对象,回收它们占用的内存空间。
remark的过程:
remark 阶段通常会结合三色标记法来执行,确保在并发标记期间所有存活对象都被正确标记。目的是修正并发标记阶段中可能遗漏的对象引用变化。
在 remark 阶段,垃圾收集器会停止应用线程(STW),以确保在这个阶段不会有引用关系的进一步变化。这种暂停通常很短暂。remark 阶段主要包括以下操作:
- 1.处理写屏障记录的引用变化:在并发标记阶段,应用程序可能会更新对象的引用(比如一个黑色对象新增了对一个白色对象的引用),这些变化通过写屏障记录下来。在 remark 阶段,GC 会处理这些记录,确保所有可达对象都正确地标记为灰色或黑色。
- 2.扫描灰色对象:再次遍历灰色对象,处理它们的所有引用,确保引用的对象正确标记为灰色或黑色。
- 3.清理:确保所有引用关系正确处理后,灰色对象标记为黑色,白色对象保持不变。这一步完成后,所有存活对象都应当是黑色的。
三色标记法:
白色(White):尚未访问的对象。垃圾回收结束后,仍然为白色的对象会被认为是不可达的对象,可以回收。
灰色(Gray):已经访问到但未标记完其引用的对象。灰色对象是需要进一步处理的。
黑色(Black):已经访问到并且其所有引用对象都已经标记过。黑色对象是完全处理过的,不需要再处理。 三色标记法的工作流程:
①、初始标记(Initial Marking):从 GC Roots 开始,标记所有直接可达的对象为灰色。
②、并发标记(Concurrent Marking):在此阶段,标记所有灰色对象引用的对象为灰色,然后将灰色对象自身标记为黑色。这个过程是并发的,和应用线程同时进行。
此阶段的一个问题是,应用线程可能在并发标记期间修改对象的引用关系,导致一些对象的标记状态不准确。
③、重新标记(Remarking):重新标记阶段的目标是处理并发标记阶段遗漏的引用变化。为了确保所有存活对象都被正确标记,remark 需要在 STW 暂停期间执行。
④、使用写屏障(Write Barrier)来捕捉并发标记阶段应用线程对对象引用的更新。通过遍历这些更新的引用来修正标记状态,确保遗漏的对象不会被错误地回收。
适用场景:
- 对响应时间要求高的应用,如 Web 服务器。
5. G1 收集器
描述:
- G1(Garbage First)收集器是一种面向服务端应用的垃圾收集器,适用于多核 CPU 和大内存环境。
- 将堆划分为多个区域(Region),使用并行和并发的方式进行垃圾回收。这种区域化管理使得 G1 可以更灵活地进行垃圾收集,只回收部分区域而不是整个新生代或老年代。
- G1(Garbage-First Garbage Collector)在 JDK 1.7 时引入,在 JDK 9 时取代 CMS 成为了默认的垃圾收集器。
运行过程:
①、并发标记,G1 通过并发标记的方式找出堆中的垃圾对象。并发标记阶段与应用线程同时执行,不会导致应用线程暂停。
②、混合收集,在并发标记完成后,G1 会计算出哪些区域的回收价值最高(也就是包含最多垃圾的区域),然后优先回收这些区域。这种回收方式包括了部分新生代区域和老年代区域。
选择回收成本低而收益高的区域进行回收,可以提高回收效率和减少停顿时间。
③、可预测的停顿,G1 在垃圾回收期间仍然需要「Stop the World」。不过,G1 在停顿时间上添加了预测机制,用户可以 JVM 启动时指定期望停顿时间,G1 会尽可能地在这个时间内完成垃圾回收。
特点:
- 并行和并发回收,减少停顿时间。
- 适用于大内存和多核 CPU 环境。
- 支持预测停顿时间。
适用场景:
- 大内存和多核 CPU 环境,适用于对响应时间和吞吐量都有要求的应用。
6. ZGC 收集器
描述:
- ZGC(Z Garbage Collector)是一种低延迟垃圾收集器,适用于大内存和低延迟要求的应用。
- 使用并发标记和并发压缩技术,减少停顿时间。
特点:
- 低延迟,停顿时间通常在 10 毫秒以内。
- 适用于大内存和低延迟要求的应用。
适用场景:
- 大内存和低延迟要求的应用,如金融交易系统。
7. Shenandoah 收集器
描述:
- Shenandoah 收集器是一种低延迟垃圾收集器,适用于大内存和低延迟要求的应用。
- 使用并发标记和并发压缩技术,减少停顿时间。
特点:
- 低延迟,停顿时间通常在 10 毫秒以内。
- 适用于大内存和低延迟要求的应用。
适用场景:
- 大内存和低延迟要求的应用,如金融交易系统。
总结-15-4
- Serial 收集器:单线程垃圾收集器,适用于单线程环境或小型应用。
- ParNew 收集器:多线程版本的 Serial 收集器,适用于多线程环境,主要用于新生代的垃圾回收。
- Parallel 收集器:关注吞吐量的多线程垃圾收集器,适用于需要高吞吐量的应用。
- CMS 收集器:并发标记-清除垃圾收集器,适用于对响应时间要求高的应用。
- G1 收集器:面向服务端应用的垃圾收集器,适用于大内存和多核 CPU 环境。
- ZGC 收集器:低延迟垃圾收集器,适用于大内存和低延迟要求的应用。
- Shenandoah 收集器:低延迟垃圾收集器,适用于大内存和低延迟要求的应用。
16.有了 CMS,为什么还要引入 G1?
| 特性 | CMS | G1 |
|---|---|---|
| 设计目标 | 低停顿时间 | 可预测的停顿时间 |
| 并发性 | 是 | 是 |
| 内存碎片 | 是,容易产生碎片 | 否,通过区域划分和压缩减少碎片 |
| 收集代数 | 年轻代和老年代 | 整个堆,但区分年轻代和老年代 |
| 并发阶段 | 并发标记、并发清理 | 并发标记、并发清理、并发回收 |
| 停顿时间预测 | 较难预测 | 可配置停顿时间目标 |
| 容易出现的问题 | 内存碎片、Concurrent Mode Failure | 较少出现长时间停顿 |
CMS 适用于对延迟敏感的应用场景,主要目标是减少停顿时间,但容易产生内存碎片。G1 则提供了更好的停顿时间预测和内存压缩能力,适用于大内存和多核处理器环境。
16.有哪些常用的命令行性能监控和故障处理工具?
操作系统工具:
- top:显示系统整体资源使用情况
- vmstat:监控内存和 CPU
- iostat:监控 IO 使用
- netstat:监控网络使用
JDK 性能监控工具:
- jps:虚拟机进程查看
- jstat:虚拟机运行时信息查看
- jinfo:虚拟机配置查看
- jmap:内存映像(导出)
- jhat:堆转储快照分析
- jstack:Java 堆栈跟踪
- jcmd:实现上面除了 jstat 外所有命令的功能
17.了解哪些可视化的性能监控和故障处理工具?
除了命令行工具,Java 生态系统中还有许多强大的可视化工具,用于性能监控和故障处理。这些工具提供了图形化界面,使得监控和诊断更加直观和便捷。以下是一些常用的可视化工具:
1. VisualVM
描述:
- VisualVM 是一个集成的性能监控和故障处理工具,提供了对 Java 应用程序的实时监控和分析功能。
- 它可以监控 CPU、内存、线程、垃圾回收等信息,并支持生成和分析堆转储、线程转储等。
特点:
- 实时监控和分析 Java 应用程序。
- 支持生成和分析堆转储、线程转储。
- 提供插件扩展功能。
使用方法:
- VisualVM 通常随 JDK 一起提供,可以在 JDK 的
bin目录下找到jvisualvm可执行文件。
2. JConsole
描述:
- JConsole 是 JDK 提供的一个基于 JMX(Java Management Extensions)的监控工具,用于监控和管理 Java 应用程序。
- 它可以监控内存使用、线程活动、类加载、垃圾回收等信息。
特点:
- 基于 JMX,支持远程监控。
- 提供实时监控和管理功能。
- 界面简单直观。
使用方法:
- JConsole 通常随 JDK 一起提供,可以在 JDK 的
bin目录下找到jconsole可执行文件。
3. Java Mission Control (JMC)
描述:
- Java Mission Control 是 Oracle 提供的一个高级监控和分析工具,集成了 JFR(Java Flight Recorder)功能。
- 它可以对 Java 应用程序进行低开销的监控和分析,适用于生产环境。
特点:
- 集成 JFR,提供低开销的监控和分析。
- 支持生成和分析飞行记录(Flight Recording)。
- 提供详细的性能分析和故障诊断功能。
使用方法:
- Java Mission Control 通常随 JDK 一起提供,可以在 JDK 的
bin目录下找到jmc可执行文件。
4. Eclipse Memory Analyzer (MAT)
描述:
- Eclipse Memory Analyzer 是一个强大的堆转储分析工具,用于查找内存泄漏和分析内存使用情况。
- 它可以生成详细的内存报告,帮助开发人员定位内存问题。
特点:
- 强大的堆转储分析功能。
- 支持生成详细的内存报告。
- 提供内存泄漏检测和分析功能。
使用方法:
- Eclipse Memory Analyzer 可以从 Eclipse 官方网站下载,并作为独立应用程序运行。
5. Grafana + Prometheus
描述:
- Grafana 和 Prometheus 是开源的监控和告警工具,常用于监控分布式系统和微服务架构。
- Prometheus 负责数据采集和存储,Grafana 负责数据可视化。
特点:
- 强大的数据采集和存储功能。
- 灵活的可视化和告警配置。
- 支持多种数据源和插件扩展。
使用方法:
- 需要安装和配置 Prometheus 和 Grafana,可以从各自的官方网站下载并按照文档进行配置。
总结-17
- VisualVM:集成的性能监控和故障处理工具,提供实时监控和分析功能。
- JConsole:基于 JMX 的监控工具,支持远程监控和管理。
- Java Mission Control (JMC):高级监控和分析工具,集成 JFR 功能,适用于生产环境。
- Eclipse Memory Analyzer (MAT):强大的堆转储分析工具,用于查找内存泄漏和分析内存使用情况。
- Grafana + Prometheus:开源的监控和告警工具,常用于监控分布式系统和微服务架构。
通过这些可视化工具,开发人员和运维人员可以更加直观和便捷地监控和诊断 Java 应用程序的性能和故障,确保应用程序的稳定运行。
18.JVM 的常见参数配置知道哪些?
JVM 提供了许多参数配置选项,用于调整内存管理、垃圾回收、性能优化等方面。以下是一些常见的 JVM 参数配置:
1. 内存设置参数
-
-Xms:设置 JVM 初始堆内存大小。-Xms512m -
-Xmx:设置 JVM 最大堆内存大小。-Xmx1024m -
-Xmn:设置新生代内存大小。-Xmn256m -
-XX:PermSize:设置永久代初始大小(适用于 JDK 1.8 之前)。-XX:PermSize=128m -
-XX:MaxPermSize:设置永久代最大大小(适用于 JDK 1.8 之前)。-XX:MaxPermSize=256m -
-XX:MetaspaceSize:设置元空间初始大小(适用于 JDK 1.8 及之后)。-XX:MetaspaceSize=128m -
-XX:MaxMetaspaceSize:设置元空间最大大小(适用于 JDK 1.8 及之后)。-XX:MaxMetaspaceSize=256m
2. 垃圾回收参数
-
-XX:+UseSerialGC:使用 Serial 垃圾收集器。-XX:+UseSerialGC -
-XX:+UseParallelGC:使用 Parallel 垃圾收集器(新生代)。-XX:+UseParallelGC -
-XX:+UseParallelOldGC:使用 Parallel Old 垃圾收集器(老年代)。-XX:+UseParallelOldGC -
-XX:+UseConcMarkSweepGC:使用 CMS 垃圾收集器。-XX:+UseConcMarkSweepGC -
-XX:+UseG1GC:使用 G1 垃圾收集器。-XX:+UseG1GC -
-XX:+UseZGC:使用 ZGC 垃圾收集器(适用于 JDK 11 及之后)。-XX:+UseZGC -
-XX:+UseShenandoahGC:使用 Shenandoah 垃圾收集器(适用于 JDK 12 及之后)。-XX:+UseShenandoahGC
3. 性能调优参数
-
-XX:+AggressiveOpts:启用 JVM 的性能优化选项。-XX:+AggressiveOpts -
-XX:+UseCompressedOops:启用指针压缩(适用于 64 位 JVM)。-XX:+UseCompressedOops -
-XX:ParallelGCThreads:设置并行垃圾收集器的线程数。-XX:ParallelGCThreads=4 -
-XX:ConcGCThreads:设置 CMS 垃圾收集器的并发线程数。-XX:ConcGCThreads=4 -
-XX:InitiatingHeapOccupancyPercent:设置 G1 垃圾收集器的堆占用触发百分比。-XX:InitiatingHeapOccupancyPercent=45
4. 调试和诊断参数
-
-XX:+PrintGC:打印垃圾回收日志。-XX:+PrintGC -
-XX:+PrintGCDetails:打印详细的垃圾回收日志。-XX:+PrintGCDetails -
-XX:+PrintGCTimeStamps:打印垃圾回收时间戳。-XX:+PrintGCTimeStamps -
-XX:+PrintHeapAtGC:在每次垃圾回收前后打印堆信息。-XX:+PrintHeapAtGC -
-Xloggc:将垃圾回收日志输出到指定文件。-Xloggc:gc.log -
-XX:+HeapDumpOnOutOfMemoryError:在发生OutOfMemoryError时生成堆转储文件。-XX:+HeapDumpOnOutOfMemoryError -
-XX:HeapDumpPath:指定堆转储文件的路径。-XX:HeapDumpPath=/path/to/dump
以下是一个示例,展示了如何配置 JVM 参数来优化性能和调试垃圾回收:
java -Xms512m -Xmx1024m -XX:+UseG1GC -XX:InitiatingHeapOccupancyPercent=45 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/dump MyApplication
总结-18
- 内存设置参数:用于配置堆内存、新生代、永久代/元空间的大小。
- 垃圾回收参数:用于选择和配置不同的垃圾收集器。
- 性能调优参数:用于启用性能优化选项和配置垃圾收集器的线程数。
- 调试和诊断参数:用于打印垃圾回收日志、生成堆转储文件等。
通过合理配置 JVM 参数,可以优化 Java 应用程序的性能和稳定性,并在出现问题时进行有效的诊断和调试。
19.线上服务 CPU 占用过高怎么排查?
当线上服务出现 CPU 占用过高的问题时,可能会影响系统的性能和响应时间。以下是一些常见的排查步骤和方法:
1. 使用操作系统工具查看 CPU 使用情况
首先,可以使用操作系统提供的工具查看系统的整体 CPU 使用情况和各个进程的 CPU 使用情况。
- Linux:
top:实时显示系统的 CPU 使用情况和各个进程的资源使用情况。htop:top的增强版,提供更友好的界面和更多功能。pidstat:显示指定进程的 CPU 使用情况。mpstat:显示每个 CPU 的使用情况。
top htop pidstat -p <pid> 1 mpstat -P ALL 1 - Windows:
- 任务管理器:按
Ctrl + Shift + Esc打开任务管理器,查看 CPU 使用情况。 - 资源监视器:在任务管理器中选择“性能”选项卡,然后点击“打开资源监视器”。
- 任务管理器:按
2. 使用 jps 和 jstack 查看 Java 线程的 CPU 使用情况
使用 jps 工具查看正在运行的 Java 进程的 PID,然后使用 jstack 工具生成线程堆栈信息。
jps
jstack <pid> > thread_dump.txt
生成的线程堆栈信息可以帮助确定哪些线程占用了大量的 CPU 资源。
3. 使用 top 和 jstack 结合分析
在 Linux 系统中,可以使用 top 命令查看哪个线程占用了大量的 CPU 资源,然后将线程 ID 转换为十六进制格式,并在 jstack 输出中查找对应的线程堆栈信息。
top -H -p <pid> # 查看指定 Java 进程的线程 CPU 使用情况
找到占用 CPU 资源较高的线程 ID(tid),将其转换为十六进制格式(printf "%x\n" <tid>),然后在 jstack 输出中查找对应的线程堆栈信息。
4. 使用 jstat 查看垃圾回收情况
使用 jstat 工具查看 JVM 的垃圾回收情况,判断是否是频繁的垃圾回收导致了 CPU 占用过高。
jstat -gc <pid> 1000 10 # 每秒显示一次垃圾回收信息,共显示10次
5. 使用 jmap 查看内存使用情况
使用 jmap 工具查看 JVM 的内存使用情况,判断是否是内存问题导致了 CPU 占用过高。
jmap -heap <pid>
6. 使用 Java Mission Control 和 VisualVM 进行深入分析
使用 Java Mission Control(JMC)和 VisualVM 等可视化工具进行深入分析,查看 CPU 使用情况、线程活动、垃圾回收等信息。
- Java Mission Control:
- 启动 JMC,连接到目标 JVM,查看 CPU 使用情况、线程活动、垃圾回收等信息。
- VisualVM:
- 启动 VisualVM,连接到目标 JVM,查看 CPU 使用情况、线程活动、垃圾回收等信息。
以下是一个示例,展示了如何使用 top 和 jstack 结合分析 Java 线程的 CPU 使用情况:
-
使用
top查看指定 Java 进程的线程 CPU 使用情况:top -H -p <pid> -
找到占用 CPU 资源较高的线程 ID(
tid),将其转换为十六进制格式:printf "%x\n" <tid> -
使用
jstack生成线程堆栈信息,并在输出中查找对应的线程堆栈信息:jstack <pid> > thread_dump.txt
总结-19
- 使用操作系统工具查看 CPU 使用情况:如
top、htop、pidstat、任务管理器等。 - 使用
jps和jstack查看 Java 线程的 CPU 使用情况:生成线程堆栈信息,确定占用 CPU 资源的线程。 - 使用
top和jstack结合分析:查看线程 CPU 使用情况,并在堆栈信息中查找对应的线程。 - 使用
jstat查看垃圾回收情况:判断是否是频繁的垃圾回收导致了 CPU 占用过高。 - 使用
jmap查看内存使用情况:判断是否是内存问题导致了 CPU 占用过高。 - 使用 Java Mission Control 和 VisualVM 进行深入分析:查看 CPU 使用情况、线程活动、垃圾回收等信息。
通过这些步骤和工具,可以有效地排查和解决线上服务 CPU 占用过高的问题,确保系统的性能和稳定性。
20.内存飙高问题怎么排查?
内存飚高一般是因为创建了大量的 Java 对象所导致的,如果持续飙高则说明垃圾回收跟不上对象创建的速度,或者内存泄漏导致对象无法回收。
排查的方法主要分为以下几步:
第一,先观察垃圾回收的情况,可以通过 jstat -gc PID 1000 查看 GC 次数和时间。
| 或者 jmap -histo PID | head -20 查看堆内存占用空间最大的前 20 个对象类型。 |
第二步,通过 jmap 命令 dump 出堆内存信息。
第三步,使用可视化工具分析 dump 文件,比如说 VisualVM,找到占用内存高的对象,再找到创建该对象的业务代码位置,从代码和业务场景中定位具体问题。
21.频繁 minor gc 怎么办?
频繁的 Minor GC(也称为 Young GC)通常表示新生代中的对象频繁地被垃圾回收,可能是因为新生代空间设置过小,或者是因为程序中存在大量的短生命周期对象(如临时变量、方法调用中创建的对象等)。
可以使用 GC 日志进行分析,查看 GC 的频率和耗时,找到频繁 GC 的原因。
-XX:+PrintGCDetails -Xloggc:gc.log
或者使用监控工具(如 VisualVM、jstat、jconsole 等)查看堆内存的使用情况,特别是新生代(Eden 和 Survivor 区)的使用情况。
如果是因为新生代空间不足,可以通过 -Xmn 增加新生代的大小,减少新生代的填满速度。
java -Xmn256m your-app.jar
如果对象未能在 Survivor 区足够长时间存活,就会被晋升到老年代,可以通过 -XX:SurvivorRatio 参数调整 Eden 和 Survivor 的比例。默认比例是 8:1,表示 8 个空间用于 Eden,1 个空间用于 Survivor 区。
-XX:SurvivorRatio=6
这将减少 Eden 区的大小,增加 Survivor 区的大小,以确保对象在 Survivor 区中存活的时间足够长,避免过早晋升到老年代。
22.频繁 Full GC 怎么办?
Full GC 是指对整个堆内存(包括新生代和老年代)进行垃圾回收操作。Full GC 频繁会导致应用程序的暂停时间增加,从而影响性能。
常见的原因有:
- 大对象(如大数组、大集合)直接分配到老年代,导致老年代空间快速被占用。
- 程序中存在内存泄漏,导致老年代的内存不断增加,无法被回收。比如 IO 资源未关闭。
- 一些长生命周期的对象进入到了老年代,导致老年代空间不足。
- 不合理的 GC 参数配置也导致 GC 频率过高。比如说新生代的空间设置过小。
该怎么排查 Full GC 频繁问题?
假如是因为大对象直接分配到老年代导致的 Full GC 频繁,可以通过 -XX:PretenureSizeThreshold 参数设置大对象直接进入老年代的阈值。
或者能不能将大对象拆分成小对象,减少大对象的创建。比如说分页。
假如是因为内存泄漏导致的 Full GC 频繁,可以通过分析堆内存 dump 文件找到内存泄漏的对象,再找到内存泄漏的代码位置。
假如是因为长生命周期的对象进入到了老年代,要及时释放资源,比如说 ThreadLocal、数据库连接、IO 资源等。
假如是因为 GC 参数配置不合理导致的 Full GC 频繁,可以通过调整 GC 参数来优化 GC 行为。或者直接更换更适合的 GC 收集器,如 G1、ZGC 等。
23.有没有处理过内存泄漏问题?是如何定位的?
内存泄漏是指程序在运行过程中由于未能正确释放已分配的内存,导致内存无法被重用,从而引发内存耗尽等问题。
常用的可视化监控工具有 JConsole、VisualVM、JProfiler、Eclipse Memory Analyzer (MAT)等。
也可以使用 JDK 自带的 jmap、jstack、jstat 等命令行工具来配合内存泄露问题的排查。
严重的内存泄漏往往伴随频繁的 Full GC,所以排查内存泄漏问题时,可以从 Full GC 入手。
第一步,使用 jps -l 查看运行的 Java 进程 ID。
第二步,使用top -p [pid]查看进程使用 CPU 和内存占用情况。
第三步,使用 top -Hp [pid] 查看进程下的所有线程占用 CPU 和内存情况。
第四步,抓取线程栈:jstack -F 29452 > 29452.txt,可以多抓几次做个对比。
29452 为 pid,顺带作为文件名
看看有没有线程死锁、死循环或长时间等待这些问题。
第五步,可以使用jstat -gcutil [pid] 5000 10每隔 5 秒输出 GC 信息,输出 10 次,查看 YGC 和 Full GC 次数。
通常会出现 YGC 不增加或增加缓慢,而 Full GC 增加很快。
或使用 jstat -gccause [pid] 5000 输出 GC 摘要信息。
或使用 jmap -heap [pid] 查看堆的摘要信息,关注老年代内存使用是否达到阀值,若达到阀值就会执行 Full GC。
如果发现 Full GC 次数太多,就很大概率存在内存泄漏了。
第六步,生成 dump 文件,然后借助可视化工具分析哪个对象非常多,基本就能定位到问题根源了。
执行命令 jmap -dump:format=b,file=heap.hprof 10025 会输出进程 10025 的堆快照信息,保存到文件 heap.hprof 中。
第七步,可以使用图形化工具分析,如 JDK 自带的 VisualVM,从菜单 > 文件 > 装入 dump 文件。
然后在结果观察内存占用最多的对象,找到内存泄漏的源头。
24.有没有处理过 OOM 问题?
OOM,也就是内存溢出,Out of Memory,是指当程序请求分配内存时,由于没有足够的内存空间满足其需求,从而触发的错误。
当发生 OOM 时,可以导出堆转储(Heap Dump)文件进行分析。如果 JVM 还在运行,可以使用 jmap 命令手动生成 Heap Dump 文件:
jmap -dump:format=b,file=heap.hprof <pid>
生成 Heap Dump 文件后,可以使用 MAT、JProfiler 等工具进行分析,查看内存中的对象占用情况,找到内存泄漏的原因。
如果生产环境的内存还有很多空余,可以适当增大堆内存大小,例如 -Xmx4g 参数。
或者检查代码中是否存在内存泄漏,如未关闭的资源、长生命周期的对象等。
之后,在本地进行压力测试,模拟高负载情况下的内存表现,确保修改有效,且没有引入新的问题。
25.了解类的加载机制吗?
JVM 的操作对象是 Class 文件,JVM 把 Class 文件中描述类的数据结构加载到内存中,并对数据进行校验、解析和初始化,最终形成可以被 JVM 直接使用的类型,这个过程被称为类加载机制。
其中最重要的三个概念就是:类加载器、类加载过程和类加载器的双亲委派模型。
- 类加载器:负责加载类文件,将类文件加载到内存中,生成 Class 对象。
- 类加载过程:加载、验证、准备、解析和初始化。
- 双亲委派模型:当一个类加载器收到类加载请求时,它首先不会自己去尝试加载这个类,而是把请求委派给父类加载器去完成,依次递归,直到最顶层的类加载器,如果父类加载器无法完成加载请求,子类加载器才会尝试自己去加载。
26.类加载器有哪些?
Java 中的类加载器(ClassLoader)负责将类文件加载到 JVM 中,并生成对应的 Class 对象。类加载器主要分为以下几种:
1. 启动类加载器(Bootstrap ClassLoader)
- 描述:启动类加载器是 JVM 自带的类加载器,用于加载核心类库。
- 加载范围:负责加载
JAVA_HOME/lib目录下的核心类库,如rt.jar。 - 实现:启动类加载器是用本地代码实现的,并不是一个 Java 类。
2. 扩展类加载器(Extension ClassLoader)
- 描述:扩展类加载器是由
sun.misc.Launcher$ExtClassLoader实现的,用于加载扩展类库。 - 加载范围:负责加载
JAVA_HOME/lib/ext目录下的类库,或者通过java.ext.dirs系统属性指定的类库。 - 实现:扩展类加载器是一个 Java 类,继承自
ClassLoader。
3. 应用程序类加载器(Application ClassLoader)
- 描述:应用程序类加载器是由
sun.misc.Launcher$AppClassLoader实现的,用于加载应用程序的类路径(classpath)下的类。 - 加载范围:负责加载用户类路径(classpath)下的类库。
- 实现:应用程序类加载器是一个 Java 类,继承自
ClassLoader。
4. 自定义类加载器(Custom ClassLoader)
- 描述:用户可以通过继承
ClassLoader类来创建自定义类加载器,以实现特殊的类加载需求。 - 加载范围:由用户定义,可以加载特定路径或特定来源的类库。这种类加载器通常用于加载网络上的类、执行热部署(动态加载和替换应用程序的组件)或为了安全目的自定义类的加载方式。
- 实现:自定义类加载器需要继承
ClassLoader类,并重写findClass方法。
总结-26
- 启动类加载器(Bootstrap ClassLoader):加载核心类库,如
rt.jar。 - 扩展类加载器(Extension ClassLoader):加载扩展类库,如
JAVA_HOME/lib/ext目录下的类库。 - 应用程序类加载器(Application ClassLoader):加载用户类路径(classpath)下的类库。
- 自定义类加载器(Custom ClassLoader):用户可以通过继承
ClassLoader类来创建自定义类加载器,以实现特殊的类加载需求。
27.能说一下类的生命周期吗?
Java 类的生命周期包括以下几个阶段:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)。每个阶段都有特定的任务和作用。
1. 加载(Loading)
加载是指将类的字节码从不同的来源(如文件系统、网络等)加载到内存中,并创建一个 Class 对象来表示这个类。
- 类加载器(ClassLoader):负责加载类的字节码。Java 提供了几种默认的类加载器,如启动类加载器、扩展类加载器和应用程序类加载器。
2. 验证(Verification)
验证是指确保类的字节码符合 JVM 规范,保证代码的安全性和正确性。
- 字节码验证:检查字节码的格式和结构是否正确。
- 符号引用验证:检查符号引用是否能被正确解析。
- 数据类型验证:检查数据类型是否匹配。
3. 准备(Preparation)
准备是指为类的静态变量分配内存,并将其初始化为默认值。
- 静态变量初始化:将静态变量初始化为默认值(如
0、null等)。
4. 解析(Resolution)
解析是指将类的符号引用转换为直接引用。
- 符号引用:在类的字节码中使用的符号名称。
- 直接引用:在内存中指向实际对象的引用。
5. 初始化(Initialization)
初始化是指对类的静态变量赋予正确的初始值,并执行类的静态代码块。
- 静态变量赋值:将静态变量赋予正确的初始值。
- 静态代码块执行:执行类中的静态代码块。
6. 使用(Using)
使用是指类在程序中被实际使用的阶段。
- 实例化对象:创建类的实例对象。
- 调用方法:调用类的方法。
7. 卸载(Unloading)
卸载是指类在 JVM 中被卸载,释放其占用的内存。
- 类卸载条件:类的所有实例都被回收,且没有任何对该类的引用。
- 类卸载过程:JVM 的垃圾回收器负责类的卸载。
以下是一个简单的类生命周期示例:
public class Test {
static {
System.out.println("Static block executed");
}
public static int value = 42;
public static void main(String[] args) {
System.out.println("Value: " + Test.value);
}
}
在这个示例中,类的生命周期如下:
- 加载:ClassLoader加载
Test类的字节码,并创建一个 Class 对象。 - 验证:验证
Test类的字节码是否符合 JVM 规范。 - 准备:为
Test类的静态变量value分配内存,并将其初始化为默认值0。 - 解析:将
Test类的符号引用转换为直接引用。 - 初始化:
- 静态变量赋值:将静态变量
value赋值为42。 - 静态代码块执行:执行静态代码块,输出 “Static block executed”。
- 静态变量赋值:将静态变量
- 使用:在
main方法中使用Test类,输出 “Value: 42”。 - 卸载:当
Test类的所有实例都被回收,且没有任何对该类的引用时,JVM 的垃圾回收器会卸载Test类。
总结-27
- 加载(Loading):将类的字节码加载到内存中,并创建 Class 对象。
- 验证(Verification):确保类的字节码符合 JVM 规范,保证代码的安全性和正确性。
- 准备(Preparation):为类的静态变量分配内存,并将其初始化为默认值。
- 解析(Resolution):将类的符号引用转换为直接引用。
- 初始化(Initialization):对类的静态变量赋予正确的初始值,并执行静态代码块。
- 使用(Using):类在程序中被实际使用的阶段。
- 卸载(Unloading):类在 JVM 中被卸载,释放其占用的内存。
28.什么是双亲委派模型?
双亲委派模型(Parent Delegation Model)是 Java 类加载机制中的一个重要概念。这种模型指的是一个类加载器在尝试加载某个类时,首先会将加载任务委托给其父类加载器去完成。
只有当父类加载器无法完成这个加载请求(即它找不到指定的类)时,子类加载器才会尝试自己去加载这个类。
- 当一个类加载器需要加载某个类时,它首先会请求其父类加载器加载这个类。
- 这个过程会一直向上递归,也就是说,从子加载器到父加载器,再到更上层的加载器,一直到最顶层的启动类加载器(Bootstrap ClassLoader)。
- 启动类加载器会尝试加载这个类。如果它能够加载这个类,就直接返回;如果它不能加载这个类(因为这个类不在它的搜索范围内),就会将加载任务返回给委托它的子加载器。
- 子加载器接着尝试加载这个类。如果子加载器也无法加载这个类,它就会继续向下传递这个加载任务,依此类推。
- 这个过程会继续,直到某个加载器能够加载这个类,或者所有加载器都无法加载这个类,最终抛出 ClassNotFoundException。
29.为什么要用双亲委派模型?
可以为 Java 应用程序的运行提供一致性和安全性的保障。
①、保证 Java 核心类库的类型安全
如果自定义类加载器优先加载一个类,比如说自定义的 Object,那在 Java 运行时环境中就存在多个版本的 java.lang.Object,双亲委派模型确保了 Java 核心类库的类加载工作由启动类加载器统一完成,从而保证了 Java 应用程序都是使用的同一份核心类库。
②、避免类的重复加载
在双亲委派模型中,类加载器会先委托给父加载器尝试加载类,这样同一个类不会被加载多次。如果没有这种模型,可能会导致同一个类被不同的类加载器重复加载到内存中,造成浪费和冲突。
30.如何破坏双亲委派机制?
在某些情况下,可能需要破坏双亲委派机制来实现特定的功能,例如加载不同版本的类或实现插件系统。破坏双亲委派机制的常见方法是自定义类加载器,并重写 loadClass 方法,使其不再委托给父类加载器。
示例:自定义类加载器
以下是一个自定义类加载器的示例,通过重写 loadClass 方法来破坏双亲委派机制:
public class CustomClassLoader extends ClassLoader {
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
// 如果类名以 "java." 开头,仍然使用父类加载器加载
if (name.startsWith("java.")) {
return super.loadClass(name);
}
// 尝试查找已经加载的类
Class<?> loadedClass = findLoadedClass(name);
if (loadedClass != null) {
return loadedClass;
}
try {
// 自定义加载类的逻辑,例如从文件系统或网络加载类的字节码
byte[] classData = loadClassData(name);
if (classData != null) {
return defineClass(name, classData, 0, classData.length);
}
} catch (Exception e) {
e.printStackTrace();
}
// 如果自定义加载失败,仍然使用父类加载器加载
return super.loadClass(name);
}
private byte[] loadClassData(String name) {
// 自定义类加载逻辑,例如从文件系统或网络加载类的字节码
// 这里仅作为示例,实际实现需要根据需求编写
return null;
}
public static void main(String[] args) throws ClassNotFoundException {
CustomClassLoader customClassLoader = new CustomClassLoader();
Class<?> clazz = customClassLoader.loadClass("Test");
System.out.println("Class loaded: " + clazz.getName());
}
}
解释
- 重写
loadClass方法:在自定义类加载器中重写loadClass方法,控制类加载的逻辑。 - 条件判断:如果类名以 “java.” 开头,仍然使用父类加载器加载,以确保核心类库的安全性。
- 查找已加载的类:首先尝试查找已经加载的类,避免重复加载。
- 自定义加载逻辑:实现自定义的类加载逻辑,例如从文件系统或网络加载类的字节码。
- 定义类:使用
defineClass方法将字节码转换为 Class 对象。 - 回退机制:如果自定义加载失败,仍然使用父类加载器加载。
总结-30
通过自定义类加载器并重写 loadClass 方法,可以破坏双亲委派机制,实现特定的类加载需求。然而,破坏双亲委派机制可能会带来类型安全性和类冲突等问题,因此在实际应用中应谨慎使用。
31.Tomcat 的类加载机制了解吗?
Tomcat 是一个流行的 Java Servlet 容器,它的类加载机制在标准的 Java 类加载机制基础上进行了扩展,以支持多应用程序的隔离和热部署。Tomcat 的类加载机制主要包括以下几个类加载器:
1. 启动类加载器(Bootstrap ClassLoader)
- 描述:负责加载 JDK 核心类库(如
rt.jar)。 - 加载范围:
$JAVA_HOME/lib目录下的类库。
2. 系统类加载器(System ClassLoader)
- 描述:负责加载 Tomcat 自身的类库。
- 加载范围:
$CATALINA_HOME/lib目录下的类库。
3. 公共类加载器(Common ClassLoader)
- 描述:负责加载所有 Web 应用程序共享的类库。
- 加载范围:
$CATALINA_HOME/lib目录下的类库。
4. Web 应用程序类加载器(WebappClassLoader)
- 描述:负责加载特定 Web 应用程序的类库。
- 加载范围:
WEB-INF/classes和WEB-INF/lib目录下的类库。
5. 自定义类加载器(Custom ClassLoader)
- 描述:用户可以通过配置自定义类加载器,以实现特定的类加载需求。
类加载器的层次结构
Tomcat 的类加载器层次结构如下:
- 启动类加载器(Bootstrap ClassLoader)
- 系统类加载器(System ClassLoader)
- 公共类加载器(Common ClassLoader)
- Web 应用程序类加载器(WebappClassLoader)
类加载顺序
- 启动类加载器:首先由启动类加载器加载 JDK 核心类库。
- 系统类加载器:然后由系统类加载器加载 Tomcat 自身的类库。
- 公共类加载器:接着由公共类加载器加载所有 Web 应用程序共享的类库。
- Web 应用程序类加载器:最后由 Web 应用程序类加载器加载特定 Web 应用程序的类库。
Tomcat 实际上也是破坏了双亲委派模型的。
Tomact 是 web 容器,可能需要部署多个应用程序。不同的应用程序可能会依赖同一个第三方类库的不同版本,但是不同版本的类库中某一个类的全路径名可能是一样的。如多个应用都要依赖 hollis.jar,但是 A 应用需要依赖 1.0.0 版本,但是 B 应用需要依赖 1.0.1 版本。这两个版本中都有一个类是 com.hollis.Test.class。如果采用默认的双亲委派类加载机制,那么无法加载多个相同的类。
所以,Tomcat 破坏了双亲委派原则,提供隔离的机制,为每个 web 容器单独提供一个 WebAppClassLoader 加载器。每一个 WebAppClassLoader 负责加载本身的目录下的 class 文件,加载不到时再交 CommonClassLoader 加载,这和双亲委派刚好相反。
32.你觉得应该怎么实现一个热部署功能?
实现热部署功能通常涉及以下几个步骤:
- 监控文件变化:监控应用程序的文件系统,检测到文件变化时触发相应的操作。
- 卸载旧类:卸载旧的类和资源,释放内存。
- 加载新类:加载新的类和资源,替换旧的类。
- 重启应用:在不重启整个服务器的情况下,重启应用程序。
1. 监控文件变化
可以使用 Java 的 WatchService API 来监控文件系统的变化。
import java.nio.file.*;
public class FileWatcher implements Runnable {
private final Path path;
public FileWatcher(Path path) {
this.path = path;
}
@Override
public void run() {
try (WatchService watchService = FileSystems.getDefault().newWatchService()) {
path.register(watchService, StandardWatchEventKinds.ENTRY_MODIFY);
while (true) {
WatchKey key = watchService.take();
for (WatchEvent<?> event : key.pollEvents()) {
if (event.kind() == StandardWatchEventKinds.ENTRY_MODIFY) {
System.out.println("File modified: " + event.context());
// 触发热部署操作
reloadApplication();
}
}
key.reset();
}
} catch (Exception e) {
e.printStackTrace();
}
}
private void reloadApplication() {
// 实现热部署逻辑
}
public static void main(String[] args) {
Path path = Paths.get("/path/to/your/application");
FileWatcher fileWatcher = new FileWatcher(path);
new Thread(fileWatcher).start();
}
}
2. 卸载旧类
使用自定义类加载器来加载和卸载类。可以通过将类加载器设置为 null 并调用垃圾回收器来卸载旧的类。
public class CustomClassLoader extends ClassLoader {
// 自定义类加载逻辑
}
public class ApplicationReloader {
private CustomClassLoader classLoader;
public void reload() {
// 卸载旧类
if (classLoader != null) {
classLoader = null;
System.gc();
}
// 加载新类
classLoader = new CustomClassLoader();
// 重新初始化应用程序
initializeApplication();
}
private void initializeApplication() {
// 初始化应用程序逻辑
}
}
3. 加载新类
使用自定义类加载器加载新的类和资源。
public class CustomClassLoader extends ClassLoader {
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
// 自定义加载类的逻辑
return super.loadClass(name);
}
}
4. 重启应用
在不重启整个服务器的情况下,重启应用程序。
public class ApplicationReloader {
private CustomClassLoader classLoader;
public void reload() {
// 卸载旧类
if (classLoader != null) {
classLoader = null;
System.gc();
}
// 加载新类
classLoader = new CustomClassLoader();
// 重新初始化应用程序
initializeApplication();
}
private void initializeApplication() {
// 初始化应用程序逻辑
}
}
总结-32
- 监控文件变化:使用
WatchServiceAPI 监控文件系统的变化。 - 卸载旧类:使用自定义类加载器并通过垃圾回收器卸载旧的类。
- 加载新类:使用自定义类加载器加载新的类和资源。
- 重启应用:在不重启整个服务器的情况下,重启应用程序。
通过这些步骤,可以实现一个基本的热部署功能。需要注意的是,热部署可能会带来一些复杂性和潜在的问题,如类冲突和内存泄漏等,因此在实际应用中应谨慎使用。
33.解释执行和编译执行的区别?
解释执行和编译执行是两种不同的程序执行方式,它们在执行流程、性能和适用场景等方面存在显著差异。
解释执行
解释执行是指程序在运行时由解释器逐行读取源代码,并将其转换为机器码执行。
- 执行流程:
- 逐行读取:解释器逐行读取源代码。
- 逐行翻译:每读取一行代码,立即将其翻译为机器码并执行。
- 即时执行:翻译后的机器码立即执行,不生成独立的可执行文件。
- 优点:
- 跨平台:源代码可以在不同平台上运行,只需提供相应平台的解释器。
- 调试方便:可以逐行执行代码,便于调试和测试。
- 缺点:
- 性能较低:每次执行都需要重新翻译代码,执行速度较慢。
- 依赖解释器:需要解释器的支持,不能生成独立的可执行文件。
- 适用场景:
- 脚本语言:如 Python、JavaScript、Ruby 等。
- 开发和调试:需要频繁修改和测试代码的场景。
编译执行
编译执行是指程序在运行前由编译器将源代码一次性翻译为机器码,生成独立的可执行文件,然后由操作系统加载执行。
- 执行流程:
- 编译:编译器将源代码一次性翻译为机器码,生成可执行文件。
- 链接:将生成的机器码与库文件链接,生成最终的可执行文件。
- 执行:操作系统加载并执行生成的可执行文件。
- 优点:
- 性能较高:编译后的机器码直接执行,执行速度较快。
- 独立性强:生成独立的可执行文件,不依赖编译器或解释器。
- 缺点:
- 跨平台性差:编译后的可执行文件只能在特定平台上运行。
- 调试不便:需要重新编译整个程序,调试和测试较为繁琐。
- 适用场景:
- 系统编程:如 C、C++ 等语言,用于开发操作系统、驱动程序等。
- 性能要求高:需要高性能执行的场景,如游戏开发、科学计算等。
Java 的混合模式
Java 采用了一种混合模式,结合了解释执行和编译执行的优点。
- 解释执行:Java 源代码首先被编译为字节码(
.class文件),由 JVM 的解释器逐行解释执行。 - 即时编译(JIT):JVM 在运行时将热点代码(执行频繁的代码)编译为机器码,提高执行效率。
总结-33
- 解释执行:
- 逐行读取和翻译:逐行读取源代码并翻译为机器码执行。
- 优点:跨平台、调试方便。
- 缺点:性能较低、依赖解释器。
- 适用场景:脚本语言、开发和调试。
- 编译执行:
- 一次性翻译:将源代码一次性翻译为机器码,生成可执行文件。
- 优点:性能较高、独立性强。
- 缺点:跨平台性差、调试不便。
- 适用场景:系统编程、性能要求高的场景。
- Java 的混合模式:结合了解释执行和编译执行的优点,通过解释执行和即时编译(JIT)提高执行效率。
通过理解解释执行和编译执行的区别,可以更好地选择适合的编程语言和执行方式,优化程序性能和开发效率。
Spring
1.Spring是什么?
Spring 是一个轻量级、非入侵式的控制反转 (IoC) 和面向切面 (AOP) 的框架。
到了现在,企业级开发的标配基本就是 Spring5 + Spring Boot 2 + JDK 8
Spring的特性
IoC 和 DI 的支持 Spring 的核心就是一个大的工厂容器,可以维护所有对象的创建和依赖关系,Spring 工厂用于生成 Bean,并且管理 Bean 的生命周期,实现高内聚低耦合的设计理念。
AOP 编程的支持 Spring 提供了面向切面编程,可以方便的实现对程序进行权限拦截、运行监控等切面功能。
声明式事务的支持 支持通过配置就来完成对事务的管理,而不需要通过硬编码的方式,以前重复的一些事务提交、回滚的 JDBC 代码,都可以不用自己写了。
快捷测试的支持 Spring 对 Junit 提供支持,可以通过注解快捷地测试 Spring 程序。
快速集成功能 方便集成各种优秀框架,Spring 不排斥各种优秀的开源框架,其内部提供了对各种优秀框架(如:Struts、Hibernate、MyBatis、Quartz 等)的直接支持。
复杂 API 模板封装 Spring 对 JavaEE 开发中非常难用的一些 API(JDBC、JavaMail、远程调用等)都提供了模板化的封装,这些封装 API 的提供使得应用难度大大降低。
2.Spring的模块
Spring 框架是一个庞大的生态系统,包含多个模块,每个模块都提供了特定的功能,以满足不同的开发需求。以下是 Spring 框架的主要模块:
1. 核心容器(Core Container)
- Spring Core:提供框架的基本功能,包括依赖注入(DI)和控制反转(IoC)。
- Spring Beans:提供 Bean 的创建、配置和管理功能。
- Spring Context:提供框架的上下文信息,扩展了 BeanFactory,支持国际化、事件传播等功能。
- Spring Expression Language (SpEL):提供强大的表达式语言,用于在运行时查询和操作对象图。
2. 数据访问/集成(Data Access/Integration)
- Spring JDBC:简化了 JDBC 操作,提供了模板类来减少冗余代码。
- Spring ORM:支持集成 ORM 框架,如 Hibernate、JPA、MyBatis 等。
- Spring OXM:提供了对象/XML 映射的支持。
- Spring JMS:简化了 JMS(Java Message Service)的使用。
- Spring Transaction:提供声明式事务管理,简化了事务处理。
3. Web 模块(Web)
- Spring Web:提供了基础的 Web 开发功能,包括多部分文件上传、初始化参数等。
- Spring WebMVC:基于模型-视图-控制器(MVC)设计模式的 Web 框架,用于构建 Web 应用程序。
- Spring WebSocket:提供了 WebSocket 的支持,用于构建实时通信应用。
- Spring WebFlux:提供了响应式编程模型,用于构建非阻塞的 Web 应用程序。
4. 面向切面编程(Aspect-Oriented Programming, AOP)
- Spring AOP:提供了面向切面编程的支持,可以实现横切关注点(如日志记录、事务管理等)的分离。
- Spring Aspects:提供了与 AspectJ 的集成,增强了 AOP 的功能。
5. 消息(Messaging)
- Spring Messaging:提供了消息传递的支持,简化了消息驱动的应用程序开发。
6. 测试(Test)
- Spring Test:提供了对 JUnit 和 TestNG 的支持,简化了 Spring 应用程序的测试。
7. 安全(Security)
- Spring Security:提供了强大的认证和授权功能,保护应用程序的安全。
8. 云(Cloud)
- Spring Cloud:提供了构建分布式系统的工具和服务,如配置管理、服务发现、断路器等。
9. 批处理(Batch)
- Spring Batch:提供了批处理应用程序的支持,简化了大规模数据处理任务的开发。
10. 数据流(Data Flow)
- Spring Data Flow:提供了数据流处理的支持,简化了数据流应用程序的开发和管理。
总结-1
Spring 框架包含多个模块,每个模块都提供了特定的功能,以满足不同的开发需求。以下是主要模块:
- 核心容器(Core Container):Spring Core、Spring Beans、Spring Context、SpEL。
- 数据访问/集成(Data Access/Integration):Spring JDBC、Spring ORM、Spring OXM、Spring JMS、Spring Transaction。
- Web 模块(Web):Spring Web、Spring WebMVC、Spring WebSocket、Spring WebFlux。
- 面向切面编程(AOP):Spring AOP、Spring Aspects。
- 消息(Messaging):Spring Messaging。
- 测试(Test):Spring Test。
- 安全(Security):Spring Security。
- 云(Cloud):Spring Cloud。
- 批处理(Batch):Spring Batch。
- 数据流(Data Flow):Spring Data Flow。
通过理解 Spring 框架的各个模块,可以更好地利用其提供的功能,构建高效、可扩展的企业级应用程序。
3.Spring有哪些常用注解?
Web 开发方面有哪些注解呢?
①、@Controller:用于标注控制层组件。
②、@RestController:是@Controller 和 @ResponseBody 的结合体,返回 JSON 数据时使用。
③、@RequestMapping:用于映射请求 URL 到具体的方法上,还可以细分为:
- @GetMapping:只能用于处理 GET 请求
- @PostMapping:只能用于处理 POST 请求
- @DeleteMapping:只能用于处理 DELETE 请求
④、@ResponseBody:直接将返回的数据放入 HTTP 响应正文中,一般用于返回 JSON 数据。
⑤、@RequestBody:表示一个方法参数应该绑定到 Web 请求体。
⑥、@PathVariable:用于接收路径参数,比如 @RequestMapping(“/hello/{name}”),这里的 name 就是路径参数。
⑦、@RequestParam:用于接收请求参数。比如 @RequestParam(name = “key”) String key,这里的 key 就是请求参数。
容器类注解有哪些呢?
@Component:标识一个类为 Spring 组件,使其能够被 Spring 容器自动扫描和管理。
@Service:标识一个业务逻辑组件(服务层)。比如@Service(“userService”),这里的 userService 就是 Bean 的名称。
@Repository:标识一个数据访问组件(持久层)。
@Autowired:按类型自动注入依赖。
@Configuration:用于定义配置类,可替换 XML 配置文件。
@Value:用于将 Spring Boot 中 application.properties 配置的属性值赋值给变量。
AOP 方面有哪些注解呢?
@Aspect 用于声明一个切面,可以配合其他注解一起使用,比如:
@After:在方法执行之后执行。
@Before:在方法执行之前执行。
@Around:方法前后均执行。
@PointCut:定义切点,指定需要拦截的方法。
事务注解有哪些?
主要就是 @Transactional,用于声明一个方法需要事务支持。
4.Spring 中应用了哪些设计模式呢?
①、工厂模式:IoC 容器本身可以看作是一个巨大的工厂,负责创建和管理 Bean 的生命周期和依赖关系。
像 BeanFactory 和 ApplicationContext 接口都提供了工厂模式的实现,负责实例化、配置和组装 Bean。
②、代理模式:AOP 的实现就是基于代理模式的,如果配置了事务管理,Spring 会使用代理模式创建一个连接数据库的代理对象,来进行事务管理。
③、单例模式:Spring 容器中的 Bean 默认都是单例的,这样可以保证 Bean 的唯一性,减少系统开销。
④、模板模式:Spring 中的 JdbcTemplate,HibernateTemplate 等以 Template 结尾的类,都使用了模板方法模式。
比如,我们使用 JdbcTemplate,只需要提供 SQL 语句和需要的参数就可以了,至于如何创建连接、执行 SQL、处理结果集等都由 JdbcTemplate 这个模板方法来完成。
④、观察者模式:Spring 事件驱动模型就是观察者模式很经典的一个应用,Spring 中的 ApplicationListener 就是观察者,当有事件(ApplicationEvent)被发布,ApplicationListener 就能接收到信息。
⑤、适配器模式:Spring MVC 中的 HandlerAdapter 就用了适配器模式。它允许 DispatcherServlet 通过统一的适配器接口与多种类型的请求处理器进行交互。
⑥、策略模式:Spring 中有一个 Resource 接口,它的不同实现类,会根据不同的策略去访问资源。
5.spring的容器、web容器、springmvc的容器之间的区别?
Spring 容器、Web 容器和 Spring MVC 容器是 Java 开发中常见的三种容器,它们在功能和用途上有所不同。以下是它们的区别和各自的特点:
1. Spring 容器
描述:Spring 容器是 Spring 框架的核心部分,负责管理应用程序中的 Bean 的生命周期和依赖关系。
主要功能:
- 依赖注入(DI):通过配置文件或注解,将对象的依赖关系注入到对象中。
- Bean 生命周期管理:管理 Bean 的创建、初始化、销毁等生命周期。
- AOP 支持:提供面向切面编程的支持,允许在运行时动态地为对象添加行为。
常见实现:
- BeanFactory:最基本的容器,提供基本的 DI 功能。
- ApplicationContext:扩展了 BeanFactory,提供更多的企业级功能,如事件传播、国际化、应用上下文等。
示例:
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
MyBean myBean = context.getBean(MyBean.class);
2. Web 容器
描述:Web 容器(也称为 Servlet 容器)是用于管理和执行 Java Web 应用程序的容器,负责处理 HTTP 请求和响应。
主要功能:
- Servlet 管理:加载、初始化、执行和销毁 Servlet。
- 会话管理:管理用户会话,跟踪用户状态。
- 安全管理:提供认证和授权机制,保护 Web 应用程序的安全。
- 请求调度:将 HTTP 请求分发到相应的 Servlet 进行处理。
常见实现:
- Apache Tomcat:一个流行的开源 Web 容器。
- Jetty:一个轻量级的 Web 容器,适用于嵌入式应用。
- WildFly(原 JBoss):一个功能强大的企业级应用服务器。
示例:
<servlet>
<servlet-name>example</servlet-name>
<servlet-class>com.example.ExampleServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>example</servlet-name>
<url-pattern>/example</url-pattern>
</servlet-mapping>
3. Spring MVC 容器
描述:Spring MVC 容器是 Spring 框架的一部分,专门用于处理 Web 请求和响应,基于模型-视图-控制器(MVC)设计模式。
主要功能:
- 请求映射:将 HTTP 请求映射到控制器方法。
- 数据绑定:将请求参数绑定到方法参数或模型对象。
- 视图解析:将控制器返回的模型数据渲染到视图(如 JSP、Thymeleaf)。
- 表单处理:处理表单提交和验证。
常见组件:
- DispatcherServlet:前端控制器,负责将请求分发到相应的处理器。
- Controller:处理请求并返回模型数据和视图名称。
- ViewResolver:解析视图名称并渲染视图。
示例:
@Controller
@RequestMapping("/users")
public class UserController {
@GetMapping("/{id}")
public String getUser(@PathVariable Long id, Model model) {
User user = userService.findById(id);
model.addAttribute("user", user);
return "user";
}
}
总结-5
- Spring 容器:
- 功能:管理 Bean 的生命周期和依赖关系,提供 AOP 支持。
- 实现:BeanFactory、ApplicationContext。
- 用途:用于管理应用程序中的对象和依赖关系。
- Web 容器:
- 功能:管理和执行 Java Web 应用程序,处理 HTTP 请求和响应。
- 实现:Apache Tomcat、Jetty、WildFly。
- 用途:用于部署和运行 Web 应用程序。
- Spring MVC 容器:
- 功能:处理 Web 请求和响应,基于 MVC 设计模式。
- 组件:DispatcherServlet、Controller、ViewResolver。
- 用途:用于构建基于 Spring 框架的 Web 应用程序。
通过理解这三种容器的区别和各自的功能,可以更好地利用它们来构建高效、可扩展的 Java 应用程序。
6.说一说什么是 IoC?什么是 DI?
控制反转(Inversion of Control, IoC)
描述:控制反转是一种设计原则,用于将对象的创建和依赖关系的管理从应用程序代码中分离出来,交给外部容器(如 Spring 容器)来处理。通过 IoC,应用程序不再负责创建和管理对象,而是由容器来控制对象的生命周期和依赖关系。
主要思想:
- 反转控制:传统的程序设计中,对象是由应用程序代码主动创建和管理的,而在 IoC 中,这种控制权被反转,交给了容器。
- 松耦合:通过 IoC,可以实现对象之间的松耦合,增强代码的可维护性和可测试性。
实现方式:
- 依赖注入(DI):IoC 的一种具体实现方式,通过注入依赖对象来实现控制反转。
- 依赖查找(DL):另一种实现方式,通过容器提供的查找方法获取依赖对象。
依赖注入(Dependency Injection, DI)
描述:依赖注入是实现 IoC 的一种方式,通过将对象的依赖关系注入到对象中,而不是在对象内部创建依赖对象。DI 可以通过构造器注入、Setter 注入和字段注入等方式实现。
主要方式:
- 构造器注入:通过构造器参数注入依赖对象。
- Setter 注入:通过 Setter 方法注入依赖对象。
- 字段注入:通过注解直接注入依赖对象。
示例:
1. 构造器注入:
public class Service {
private final Repository repository;
@Autowired
public Service(Repository repository) {
this.repository = repository;
}
}
2. Setter 注入:
public class Service {
private Repository repository;
@Autowired
public void setRepository(Repository repository) {
this.repository = repository;
}
}
3. 字段注入:
public class Service {
@Autowired
private Repository repository;
}
IoC 和 DI 的关系
- IoC 是一种设计原则:控制反转是一种设计原则,用于将对象的创建和管理交给外部容器。
- DI 是 IoC 的一种实现方式:依赖注入是实现控制反转的一种具体方式,通过注入依赖对象来实现对象之间的松耦合。
Spring 中的 IoC 和 DI
Spring 框架广泛应用了 IoC 和 DI 原则,通过 Spring 容器来管理对象的创建和依赖关系,实现对象之间的松耦合。
Spring 容器:
- BeanFactory:最基本的 IoC 容器,提供基本的 DI 功能。
- ApplicationContext:扩展了 BeanFactory,提供更多的企业级功能,如事件传播、国际化、应用上下文等。
Spring 中的 DI:
- 注解:如
@Autowired、@Qualifier、@Resource等。 - XML 配置:通过 XML 文件配置依赖关系。
- Java 配置:通过 Java 配置类和
@Bean注解配置依赖关系。
示例:
@Configuration
public class AppConfig {
@Bean
public Repository repository() {
return new Repository();
}
@Bean
public Service service() {
return new Service(repository());
}
}
总结-6
- 控制反转(IoC):一种设计原则,将对象的创建和管理交给外部容器,实现对象之间的松耦合。
- 依赖注入(DI):实现 IoC 的一种方式,通过注入依赖对象来实现控制反转。
- 构造器注入:通过构造器参数注入依赖对象。
- Setter 注入:通过 Setter 方法注入依赖对象。
- 字段注入:通过注解直接注入依赖对象。
通过理解 IoC 和 DI 的概念及其在 Spring 中的应用,可以更好地利用 Spring 框架提供的功能,编写高质量的代码。
7.能简单说一下 Spring IoC 的实现机制吗?
Spring 的 IoC 容器通过依赖注入(DI)来管理对象的创建和依赖关系,实现对象之间的松耦合。以下是 Spring IoC 的实现机制的关键步骤:
1. 配置元数据
Spring IoC 容器需要配置元数据来定义 Bean 及其依赖关系。配置元数据可以通过以下几种方式提供:
- XML 配置:在 XML 文件中定义 Bean 和依赖关系。
- 注解:使用注解(如
@Component、@Autowired等)来标记和注入 Bean。 - Java 配置:使用 Java 配置类和
@Bean注解来定义 Bean。
2. 解析配置元数据
Spring IoC 容器在启动时会解析配置元数据,构建内部的数据结构来表示 Bean 及其依赖关系。
- XML 配置解析:解析 XML 文件中的
<bean>元素。 - 注解解析:扫描类路径中的注解(如
@Component、@Service等)。 - Java 配置解析:解析配置类中的
@Bean方法。
3. 创建 Bean 实例
Spring IoC 容器根据解析后的配置元数据创建 Bean 实例。创建 Bean 实例的过程包括以下几个步骤:
- 实例化:使用反射机制调用构造器创建 Bean 实例。
- 依赖注入:注入 Bean 的依赖对象,可以通过构造器注入、Setter 注入或字段注入实现。
- 初始化:调用 Bean 的初始化方法(如
@PostConstruct注解的方法或实现InitializingBean接口的afterPropertiesSet方法)。
4. 管理 Bean 生命周期
Spring IoC 容器管理 Bean 的整个生命周期,包括创建、初始化、销毁等阶段。
- 单例 Bean:默认情况下,Spring 容器中的 Bean 是单例的,即每个 Bean 只有一个实例。
- 原型 Bean:每次请求都会创建一个新的 Bean 实例。
- 自定义 Bean 生命周期:可以通过实现
BeanPostProcessor接口来自定义 Bean 的初始化和销毁逻辑。
5. 提供 Bean
Spring IoC 容器通过 BeanFactory 或 ApplicationContext 提供对 Bean 的访问。应用程序可以通过这些接口获取和使用 Bean。
- BeanFactory:最基本的 IoC 容器,提供基本的 DI 功能。
- ApplicationContext:扩展了 BeanFactory,提供更多的企业级功能,如事件传播、国际化、应用上下文等。
XML 配置
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="repository" class="com.example.Repository"/>
<bean id="service" class="com.example.Service">
<constructor-arg ref="repository"/>
</bean>
</beans>
注解配置
@Component
public class Repository {
// Repository implementation
}
@Service
public class Service {
private final Repository repository;
@Autowired
public Service(Repository repository) {
this.repository = repository;
}
}
Java 配置
@Configuration
public class AppConfig {
@Bean
public Repository repository() {
return new Repository();
}
@Bean
public Service service() {
return new Service(repository());
}
}
总结-7
- 配置元数据:通过 XML 配置、注解或 Java 配置定义 Bean 和依赖关系。
- 解析配置元数据:Spring IoC 容器解析配置元数据,构建内部数据结构。
- 创建 Bean 实例:使用反射机制创建 Bean 实例,并注入依赖对象。
- 管理 Bean 生命周期:管理 Bean 的创建、初始化和销毁等生命周期阶段。
- 提供 Bean:通过
BeanFactory或ApplicationContext提供对 Bean 的访问。
8.说说 BeanFactory 和 ApplicantContext?
BeanFactory 和 ApplicationContext 是 Spring 框架中用于管理 Bean 的两种主要容器接口。它们在功能和使用场景上有所不同。
1. BeanFactory
描述:BeanFactory 是 Spring 的基础 IoC 容器,提供了基本的依赖注入功能。它是 Spring 容器的核心接口,定义了 Bean 的创建、配置和管理方式。
主要特点:
- 延迟加载:
BeanFactory采用延迟加载(Lazy Loading)策略,只有在第一次访问 Bean 时才会创建该 Bean 实例。 - 轻量级:
BeanFactory是一个轻量级容器,适用于资源受限的环境。
常见实现:
- XmlBeanFactory:从 XML 配置文件中读取 Bean 定义并创建 Bean 实例(已废弃,推荐使用
ClassPathXmlApplicationContext或FileSystemXmlApplicationContext)。
示例:
BeanFactory factory = new ClassPathXmlApplicationContext("applicationContext.xml");
MyBean myBean = factory.getBean(MyBean.class);
2. ApplicationContext
描述:ApplicationContext 是 BeanFactory 的子接口,扩展了 BeanFactory 的功能,提供了更多的企业级特性。它是 Spring 框架中最常用的容器接口。
主要特点:
- 立即加载:
ApplicationContext采用立即加载(Eager Loading)策略,在容器启动时就会创建所有单例 Bean 实例。 - 国际化支持:提供了国际化(i18n)支持,可以方便地处理多语言应用。
- 事件机制:支持事件发布和监听机制,可以在应用程序中发布和监听事件。
- AOP 支持:集成了 Spring AOP,提供了面向切面编程的支持。
- 注解支持:支持基于注解的配置和依赖注入。
常见实现:
- ClassPathXmlApplicationContext:从类路径下的 XML 配置文件中读取 Bean 定义并创建 Bean 实例。
- FileSystemXmlApplicationContext:从文件系统中的 XML 配置文件中读取 Bean 定义并创建 Bean 实例。
- AnnotationConfigApplicationContext:从 Java 配置类中读取 Bean 定义并创建 Bean 实例。
示例:
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
MyBean myBean = context.getBean(MyBean.class);
主要区别
| 特性 | BeanFactory | ApplicationContext |
|---|---|---|
| 加载策略 | 延迟加载(Lazy Loading) | 立即加载(Eager Loading) |
| 国际化支持 | 不支持 | 支持 |
| 事件机制 | 不支持 | 支持 |
| AOP 支持 | 基本支持 | 完整支持 |
| 注解支持 | 基本支持 | 完整支持 |
| 使用场景 | 资源受限的环境 | 企业级应用程序 |
总结- 8
- BeanFactory:
- 描述:Spring 的基础 IoC 容器,提供基本的依赖注入功能。
- 特点:延迟加载、轻量级。
- 使用场景:资源受限的环境。
-
示例:
BeanFactory factory = new ClassPathXmlApplicationContext("applicationContext.xml"); MyBean myBean = factory.getBean(MyBean.class);
- ApplicationContext:
- 描述:
BeanFactory的子接口,扩展了更多企业级特性。 - 特点:立即加载、国际化支持、事件机制、AOP 支持、注解支持。
- 使用场景:企业级应用程序。
-
示例:
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml"); MyBean myBean = context.getBean(MyBean.class);
- 描述:
通过理解 BeanFactory 和 ApplicationContext 的区别和各自的特点,可以更好地选择和使用 Spring 容器来管理应用程序中的 Bean。
9.Spring 的 Bean 实例化方式?
Spring 框架提供了多种方式来实例化 Bean,主要包括以下几种:
1. 构造器实例化
描述:通过调用类的构造器来创建 Bean 实例。这是最常见的实例化方式。
配置方式:
- XML 配置:使用
<constructor-arg>元素指定构造器参数。 - 注解配置:使用
@Autowired注解在构造器上进行自动注入。 - Java 配置:在
@Bean方法中直接调用构造器。
示例:
- XML 配置:
<bean id="myBean" class="com.example.MyBean">
<constructor-arg value="constructorArgValue"/>
</bean>
- 注解配置:
@Component
public class MyBean {
private final String value;
@Autowired
public MyBean(@Value("constructorArgValue") String value) {
this.value = value;
}
}
- Java 配置:
@Configuration
public class AppConfig {
@Bean
public MyBean myBean() {
return new MyBean("constructorArgValue");
}
}
2. 静态工厂方法实例化
描述:通过调用静态工厂方法来创建 Bean 实例。静态工厂方法是一个静态方法,它返回一个 Bean 实例。
配置方式:
- XML 配置:使用
factory-method属性指定静态工厂方法。 - Java 配置:在
@Bean方法中调用静态工厂方法。
示例:
- XML 配置:
<bean id="myBean" class="com.example.MyBeanFactory" factory-method="createInstance"/>
- Java 配置:
@Configuration
public class AppConfig {
@Bean
public MyBean myBean() {
return MyBeanFactory.createInstance();
}
}
3. 实例工厂方法实例化
描述:通过调用实例工厂方法来创建 Bean 实例。实例工厂方法是一个实例方法,它返回一个 Bean 实例。
配置方式:
- XML 配置:使用
factory-bean和factory-method属性指定实例工厂和工厂方法。 - Java 配置:在
@Bean方法中调用实例工厂方法。
示例:
- XML 配置:
<bean id="myBeanFactory" class="com.example.MyBeanFactory"/>
<bean id="myBean" factory-bean="myBeanFactory" factory-method="createInstance"/>
- Java 配置:
@Configuration
public class AppConfig {
@Bean
public MyBeanFactory myBeanFactory() {
return new MyBeanFactory();
}
@Bean
public MyBean myBean() {
return myBeanFactory().createInstance();
}
}
总结-9
Spring 提供了多种方式来实例化 Bean,主要包括:
- 构造器实例化:通过调用类的构造器来创建 Bean 实例。
- XML 配置:使用
<constructor-arg>元素。 - 注解配置:使用
@Autowired注解在构造器上。 - Java 配置:在
@Bean方法中直接调用构造器。
- XML 配置:使用
- 静态工厂方法实例化:通过调用静态工厂方法来创建 Bean 实例。
- XML 配置:使用
factory-method属性。 - Java 配置:在
@Bean方法中调用静态工厂方法。
- XML 配置:使用
- 实例工厂方法实例化:通过调用实例工厂方法来创建 Bean 实例。
- XML 配置:使用
factory-bean和factory-method属性。 - Java 配置:在
@Bean方法中调用实例工厂方法。
- XML 配置:使用
10.能说一下 Spring Bean 生命周期吗?
Spring 中 Bean 的生命周期大致分为四个阶段:实例化(Instantiation)、属性赋值(Populate)、初始化(Initialization)、销毁(Destruction)。
实例化:Spring 容器根据 Bean 的定义创建 Bean 的实例,相当于执行构造方法,也就是 new 一个对象。
属性赋值:相当于执行 setter 方法为字段赋值。
初始化:初始化阶段允许执行自定义的逻辑,比如设置某些必要的属性值、开启资源、执行预加载操作等,以确保 Bean 在使用之前是完全配置好的。
销毁:相当于执行 = null,释放资源。
11.Bean 定义和依赖定义有哪些方式?
有三种方式:直接编码方式、配置文件方式、注解方式。
- 直接编码方式:我们一般接触不到直接编码的方式,但其实其它的方式最终都要通过直接编码来实现。
- 配置文件方式:通过 xml、propreties 类型的配置文件,配置相应的依赖关系,Spring 读取配置文件,完成依赖关系的注入。
- 注解方式:注解方式应该是我们用的最多的一种方式了,在相应的地方使用注解修饰,Spring 会扫描注解,完成依赖关系的注入。
12.Spring 有哪些自动装配的方式?
Spring IoC 容器知道所有 Bean 的配置信息,此外,通过 Java 反射机制还可以获知实现类的结构信息,如构造方法的结构、属性等信息。掌握所有 Bean 的这些信息后,Spring IoC 容器就可以按照某种规则对容器中的 Bean 进行自动装配,而无须通过显式的方式进行依赖配置。
Spring 提供的这种方式,可以按照某些规则进行 Bean 的自动装配,<bean>元素提供了一个指定自动装配类型的属性:autowire="<自动装配类型>"
- byName:根据名称进行自动匹配,假设 Boss 又一个名为 car 的属性,如果容器中刚好有一个名为 car 的 bean,Spring 就会自动将其装配给 Boss 的 car 属性
- byType:根据类型进行自动匹配,假设 Boss 有一个 Car 类型的属性,如果容器中刚好有一个 Car 类型的 Bean,Spring 就会自动将其装配给 Boss 这个属性
- constructor:与 byType 类似, 只不过它是针对构造函数注入而言的。如果 Boss 有一个构造函数,构造函数包含一个 Car 类型的入参,如果容器中有一个 Car 类型的 Bean,则 Spring 将自动把这个 Bean 作为 Boss 构造函数的入参;如果容器中没有找到和构造函数入参匹配类型的 Bean,则 Spring 将抛出异常。
- autodetect:根据 Bean 的自省机制决定采用 byType 还是 constructor 进行自动装配,如果 Bean 提供了默认的构造函数,则采用 byType,否则采用 constructor。
13.Spring 中的 Bean 的作用域有哪些?
Spring 的 Bean 主要支持五种作用域:
- singleton : 在 Spring 容器仅存在一个 Bean 实例,Bean 以单实例的方式存在,是 Bean 默认的作用域。
- prototype : 每次从容器重调用 Bean 时,都会返回一个新的实例。
以下三个作用域于只在 Web 应用中适用:
- request : 每一次 HTTP 请求都会产生一个新的 Bean,该 Bean 仅在当前 HTTP Request 内有效。
- session : 同一个 HTTP Session 共享一个 Bean,不同的 HTTP Session 使用不同的 Bean。
- globalSession:同一个全局 Session 共享一个 Bean,只用于基于 Protlet 的 Web 应用,Spring5 中已经不存在了。
14.Spring 中的单例 Bean 会存在线程安全问题吗?
是的,Spring 中的单例(Singleton)Bean 可能会存在线程安全问题。
单例 Bean 的线程安全问题
描述:在 Spring 中,单例作用域(Singleton Scope)意味着在整个 Spring 容器中只有一个 Bean 实例。这个实例会被多个线程共享使用。如果这个单例 Bean 中包含了可变状态(即成员变量可以被修改),并且这些状态在多个线程之间共享,那么就可能会出现线程安全问题。
线程安全问题的示例
假设有一个单例 Bean Counter,它包含一个可变的计数器变量:
@Component
public class Counter {
private int count = 0;
public void increment() {
count++;
}
public int getCount() {
return count;
}
}
在多线程环境中,如果多个线程同时调用 increment 方法,由于 count 变量的读写操作不是原子的,可能会导致计数器的值不正确。
解决线程安全问题的方法
1. 无状态 Bean:尽量设计无状态的 Bean,即不包含可变的成员变量。无状态的 Bean 是线程安全的,因为它们不在多个线程之间共享状态。
2. 局部变量:将可变状态限制在方法内部,使用局部变量而不是成员变量。局部变量是线程安全的,因为它们是线程私有的。
3. 同步:对共享的可变状态进行同步,确保同一时刻只有一个线程可以访问该状态。
@Component
public class Counter {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
return count;
}
}
4. 使用线程安全的数据结构:使用 Java 提供的线程安全的数据结构,如 AtomicInteger、ConcurrentHashMap 等。
@Component
public class Counter {
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet();
}
public int getCount() {
return count.get();
}
}
5. 作用域调整:如果 Bean 的状态必须是可变的,并且需要在不同线程之间共享,可以考虑将 Bean 的作用域调整为 prototype,这样每次请求都会创建一个新的 Bean 实例。
@Component
@Scope("prototype")
public class Counter {
private int count = 0;
public void increment() {
count++;
}
public int getCount() {
return count;
}
}
6.将 Bean 中的成员变量保存到 ThreadLocal 中:ThreadLocal 可以保证多线程环境下变量的隔离。
public class MyService {
private ThreadLocal<Integer> localVar = ThreadLocal.withInitial(() -> 0);
public void process() {
localVar.set(localVar.get() + 1);
}
}
总结- 14
Spring 中的单例(Singleton)Bean 可能会存在线程安全问题,特别是当 Bean 包含可变状态时。在多线程环境中,多个线程共享同一个单例 Bean 实例,可能会导致数据不一致或其他并发问题。
解决线程安全问题的方法包括:
- 设计无状态的 Bean。
- 使用局部变量而不是成员变量。
- 对共享的可变状态进行同步。
- 使用线程安全的数据结构。
- 将 Bean 的作用域调整为
prototype。 - 将 Bean 中的成员变量保存到 ThreadLocal 中
通过理解和应用这些方法,可以有效地避免单例 Bean 的线程安全问题,确保应用程序的正确性和稳定性。
15.循环依赖问题
循环依赖(Circular Dependency)是指两个或多个 Bean 互相依赖,形成一个闭环。例如,Bean A 依赖于 Bean B,而 Bean B 又依赖于 Bean A。这种依赖关系会导致在创建 Bean 实例时出现问题,因为 Spring 容器无法确定哪个 Bean 应该先创建。
循环依赖只发生在 Singleton 作用域的 Bean 之间,因为如果是 Prototype 作用域的 Bean,Spring 会直接抛出异常。
原因很简单,AB 循环依赖,A 实例化的时候,发现依赖 B,创建 B 实例,创建 B 的时候发现需要 A,创建 A1 实例……无限套娃。
Spring 可以解决哪些情况的循环依赖?
- AB 均采用构造器注入,不支持
- AB 均采用 setter 注入,支持
- AB 均采用属性自动注入,支持
- A 中注入的 B 为 setter 注入,B 中注入的 A 为构造器注入,支持
- B 中注入的 A 为 setter 注入,A 中注入的 B 为构造器注入,不支持
第四种可以,第五种不可以的原因是 Spring 在创建 Bean 时默认会根据自然排序进行创建,所以 A 会先于 B 进行创建。
当循环依赖的实例都采用 setter 方法注入时,Spring 支持,都采用构造器注入的时候,不支持。
Spring 怎么解决循环依赖的呢?
Spring 通过三级缓存(Three-Level Cache)机制来解决循环依赖。
- 一级缓存:用于存放完全初始化好的单例 Bean。
- 二级缓存:用于存放正在创建但未完全初始化的 Bean 实例。
- 三级缓存:用于存放 Bean 工厂对象,用于提前暴露 Bean。
三级缓存解决循环依赖的过程是什么样的?
A 实例的初始化过程:
①、创建 A 实例,实例化的时候把 A 的对象⼯⼚放⼊三级缓存,表示 A 开始实例化了,虽然这个对象还不完整,但是先曝光出来让大家知道。
②、A 注⼊属性时,发现依赖 B,此时 B 还没有被创建出来,所以去实例化 B。
③、同样,B 注⼊属性时发现依赖 A,它就从缓存里找 A 对象。依次从⼀级到三级缓存查询 A。
发现可以从三级缓存中通过对象⼯⼚拿到 A,虽然 A 不太完善,但是存在,就把 A 放⼊⼆级缓存,同时删除三级缓存中的 A,此时,B 已经实例化并且初始化完成了,把 B 放入⼀级缓存。
④、接着 A 继续属性赋值,顺利从⼀级缓存拿到实例化且初始化完成的 B 对象,A 对象创建也完成,删除⼆级缓存中的 A,同时把 A 放⼊⼀级缓存
⑤、最后,⼀级缓存中保存着实例化、初始化都完成的 A、B 对象。
为什么要三级缓存?二级不行吗?
代理对象的提前暴露
在某些情况下,Spring 需要为 Bean 创建代理对象(例如,AOP 切面)。如果仅使用二级缓存,Spring 无法在 Bean 实例化的早期阶段创建代理对象并将其暴露出来。而三级缓存允许 Spring 在 Bean 实例化的早期阶段通过 Bean 工厂对象创建代理对象,并将其暴露出来,从而解决代理对象的提前暴露问题。
三级缓存中放的是⽣成具体对象的匿名内部类,获取 Object 的时候,它可以⽣成代理对象,也可以返回普通对象。使⽤三级缓存主要是为了保证不管什么时候使⽤的都是⼀个对象。
假设只有二级缓存的情况,往二级缓存中放的显示⼀个普通的 Bean 对象,Bean 初始化过程中,通过 BeanPostProcessor 去⽣成代理对象之后,覆盖掉二级缓存中的普通 Bean 对象,那么可能就导致取到的 Bean 对象不一致了。
16.@Autowired 的实现原理?
实现@Autowired 的关键是:AutowiredAnnotationBeanPostProcessor
在 Bean 的初始化阶段,会通过 Bean 后置处理器来进行一些前置和后置的处理。
实现@Autowired 的功能,也是通过后置处理器来完成的。这个后置处理器就是 AutowiredAnnotationBeanPostProcessor。
Spring 在创建 bean 的过程中,最终会调用到 doCreateBean()方法,在 doCreateBean()方法中会调用 populateBean()方法,来为 bean 进行属性填充,完成自动装配等工作。
在 populateBean()方法中一共调用了两次后置处理器,第一次是为了判断是否需要属性填充,如果不需要进行属性填充,那么就会直接进行 return,如果需要进行属性填充,那么方法就会继续向下执行,后面会进行第二次后置处理器的调用,这个时候,就会调用到 AutowiredAnnotationBeanPostProcessor 的 postProcessPropertyValues()方法,在该方法中就会进行@Autowired 注解的解析,然后实现自动装配。
/**
* 属性赋值
**/
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
//…………
if (hasInstAwareBpps) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
PropertyValues pvsToUse;
for(Iterator var9 = this.getBeanPostProcessorCache().instantiationAware.iterator(); var9.hasNext(); pvs = pvsToUse) {
InstantiationAwareBeanPostProcessor bp = (InstantiationAwareBeanPostProcessor)var9.next();
pvsToUse = bp.postProcessProperties((PropertyValues)pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
if (filteredPds == null) {
filteredPds = this.filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
//执行后处理器,填充属性,完成自动装配
//调用InstantiationAwareBeanPostProcessor的postProcessPropertyValues()方法
pvsToUse = bp.postProcessPropertyValues((PropertyValues)pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
return;
}
}
}
}
//…………
}
postProcessorPropertyValues()方法的源码如下,在该方法中,会先调用 findAutowiringMetadata()方法解析出 bean 中带有@Autowired 注解、@Inject 和@Value 注解的属性和方法。然后调用 metadata.inject()方法,进行属性填充。
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
//@Autowired注解、@Inject和@Value注解的属性和方法
InjectionMetadata metadata = this.findAutowiringMetadata(beanName, bean.getClass(), pvs);
try {
//属性填充
metadata.inject(bean, beanName, pvs);
return pvs;
} catch (BeanCreationException var6) {
throw var6;
} catch (Throwable var7) {
throw new BeanCreationException(beanName, "Injection of autowired dependencies failed", var7);
}
}
17.说说什么是 AOP?
AOP(Aspect-Oriented Programming,面向切面编程)是一种编程范式,旨在通过分离横切关注点(cross-cutting concerns)来提高代码的模块化。横切关注点是指那些在多个模块中都会涉及的功能,例如日志记录、安全检查、事务管理等。AOP 通过将这些横切关注点从业务逻辑中分离出来,使代码更加清晰、可维护。
AOP 的核心概念
- 切面(Aspect):
- 切面是横切关注点的模块化实现。它可以包含多个通知(advice)和切点(pointcut)。
- 例如,一个日志切面可以包含记录方法调用的通知。
- 通知(Advice):
- 通知是切面中的具体动作,它定义了在切点处执行的代码。
- 通知类型包括前置通知(Before)、后置通知(After)、返回通知(AfterReturning)、异常通知(AfterThrowing)和环绕通知(Around)。
- 切点(Pointcut):
- 切点定义了在哪些连接点(Join Point)上执行通知。它通过表达式来匹配连接点。
- 例如,可以定义一个切点匹配所有以
get开头的方法。
- 连接点(Join Point):
- 连接点是程序执行中的一个特定点,例如方法调用或异常抛出。
- 在 Spring AOP 中,连接点主要是方法调用。
- 目标对象(Target Object):
- 目标对象是被一个或多个切面增强的对象。也称为被代理对象(proxied object)。
- 代理(Proxy):
- 代理是 AOP 框架创建的对象,用于实现切面功能。代理对象包含目标对象的所有方法,并在适当的时候调用通知。
- Spring AOP 使用 JDK 动态代理或 CGLIB 代理来创建代理对象。
- 织入(Weaving):
- 织入是将切面应用到目标对象并创建代理对象的过程。织入可以在编译时、类加载时或运行时进行。
- Spring AOP 主要在运行时进行织入。
织入有哪几种方式?
①、编译期织入:切面在目标类编译时被织入。
②、类加载期织入:切面在目标类加载到 JVM 时被织入。需要特殊的类加载器,它可以在目标类被引入应用之前增强该目标类的字节码。
③、运行期织入:切面在应用运行的某个时刻被织入。一般情况下,在织入切面时,AOP 容器会为目标对象动态地创建一个代理对象。
Spring AOP 采用运行期织入,而 AspectJ 可以在编译期织入和类加载时织入。
AspectJ是什么?
AspectJ 是一个 AOP 框架,它可以做很多 Spring AOP 干不了的事情,比如说支持编译时、编译后和类加载时织入切面。并且提供更复杂的切点表达式和通知类型。
AOP有几种环绕方式?
AOP 一般有 5 种环绕方式:
前置环绕(Before):
在目标方法执行之前执行自定义逻辑。
后置环绕(After):
在目标方法执行之后执行自定义逻辑。
返回环绕(AfterReturning):
在目标方法成功返回之后执行自定义逻辑,可以修改返回值。
异常环绕(AfterThrowing):
在目标方法抛出异常之后执行自定义逻辑,可以处理或修改异常。
完整环绕(Around):
在目标方法执行之前和之后都执行自定义逻辑,可以完全控制目标方法的执行。
Spring AOP 示例
以下是一个简单的 Spring AOP 示例,展示了如何使用 AOP 来记录方法调用的日志。
定义切面:
@Aspect
@Component
public class LoggingAspect {
@Before("execution(* com.example.service.*.*(..))")
public void logBeforeMethod(JoinPoint joinPoint) {
System.out.println("Before method: " + joinPoint.getSignature().getName());
}
@After("execution(* com.example.service.*.*(..))")
public void logAfterMethod(JoinPoint joinPoint) {
System.out.println("After method: " + joinPoint.getSignature().getName());
}
}
配置 AOP:
@Configuration
@EnableAspectJAutoProxy
public class AppConfig {
// 配置类,启用 AOP 支持
}
目标对象:
@Service
public class MyService {
public void performTask() {
System.out.println("Performing task");
}
}
使用目标对象:
public class Main {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
MyService myService = context.getBean(MyService.class);
myService.performTask();
}
}
总结- 17
AOP,也就是面向切面编程,是一种编程范式,旨在提高代码的模块化。比如说可以将日志记录、事务管理等分离出来,来提高代码的可重用性。
AOP 的核心概念包括切面(Aspect)、连接点(Join Point)、通知(Advice)、切点(Pointcut)和织入(Weaving)等。
① 像日志打印、事务管理等都可以抽离为切面,可以声明在类的方法上。像 @Transactional 注解,就是一个典型的 AOP 应用,它就是通过 AOP 来实现事务管理的。我们只需要在方法上添加 @Transactional 注解,Spring 就会在方法执行前后添加事务管理的逻辑。
② Spring AOP 是基于代理的,它默认使用 JDK 动态代理和 CGLIB 代理来实现 AOP。
③ Spring AOP 的织入方式是运行时织入,而 AspectJ 支持编译时织入、类加载时织入。
18.说说 JDK 动态代理和 CGLIB 代理?
在 Spring AOP 中,代理是实现切面功能的核心机制。Spring AOP 主要使用两种代理方式:JDK 动态代理和 CGLIB 代理。以下是这两种代理方式的详细介绍:
JDK 动态代理
描述:JDK 动态代理是基于 Java 反射机制的一种代理方式,它只能代理实现了接口的类。
特点:
- 接口代理:JDK 动态代理只能代理实现了接口的类。
- 运行时生成:代理类在运行时动态生成,而不是在编译时生成。
- 性能:由于使用了反射机制,性能相对较低,但在大多数情况下是可以接受的。
示例:
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class JdkDynamicProxyExample {
public static void main(String[] args) {
// 创建目标对象
MyService target = new MyServiceImpl();
// 创建代理对象
MyService proxy = (MyService) Proxy.newProxyInstance(
target.getClass().getClassLoader(),
target.getClass().getInterfaces(),
new MyInvocationHandler(target)
);
// 调用代理对象的方法
proxy.performTask();
}
}
interface MyService {
void performTask();
}
class MyServiceImpl implements MyService {
@Override
public void performTask() {
System.out.println("Performing task");
}
}
class MyInvocationHandler implements InvocationHandler {
private final Object target;
public MyInvocationHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("Before method: " + method.getName());
Object result = method.invoke(target, args);
System.out.println("After method: " + method.getName());
return result;
}
}
CGLIB 代理
描述:CGLIB(Code Generation Library)代理是基于字节码生成的一种代理方式,它可以代理没有实现接口的类。
特点:
- 子类代理:CGLIB 代理通过生成目标类的子类来实现代理,因此可以代理没有实现接口的类。
- 运行时生成:代理类在运行时动态生成,而不是在编译时生成。
- 性能:由于直接操作字节码,性能比 JDK 动态代理高。
示例:
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
public class CglibProxyExample {
public static void main(String[] args) {
// 创建目标对象
MyService target = new MyService();
// 创建代理对象
MyService proxy = (MyService) Enhancer.create(
target.getClass(),
new MyMethodInterceptor(target)
);
// 调用代理对象的方法
proxy.performTask();
}
}
class MyService {
public void performTask() {
System.out.println("Performing task");
}
}
class MyMethodInterceptor implements MethodInterceptor {
private final Object target;
public MyMethodInterceptor(Object target) {
this.target = target;
}
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("Before method: " + method.getName());
Object result = proxy.invoke(target, args);
System.out.println("After method: " + method.getName());
return result;
}
}
Spring AOP 中的代理选择
Spring AOP 默认会根据目标类是否实现了接口来选择代理方式:
- JDK 动态代理:如果目标类实现了接口,Spring AOP 会使用 JDK 动态代理。
- CGLIB 代理:如果目标类没有实现接口,Spring AOP 会使用 CGLIB 代理。
你也可以通过配置强制使用 CGLIB 代理:
@Configuration
@EnableAspectJAutoProxy(proxyTargetClass = true)
public class AppConfig {
// 配置类,启用 AOP 支持,并强制使用 CGLIB 代理
}
总结- 18
在 Spring AOP 中,代理是实现切面功能的核心机制。Spring AOP 主要使用两种代理方式:
- JDK 动态代理:
- 基于 Java 反射机制。
- 只能代理实现了接口的类。
- 代理类在运行时动态生成。
- 性能相对较低,但在大多数情况下是可以接受的。
- CGLIB 代理:
- 基于字节码生成。
- 可以代理没有实现接口的类。
- 代理类在运行时动态生成。
- 性能比 JDK 动态代理高。
通过理解这两种代理方式的特点和使用场景,可以更好地选择和使用 Spring AOP 提供的代理机制,提高代码的模块化和可维护性。
19.说说 Spring AOP 和 AspectJ AOP 区别?
Spring AOP
Spring AOP 属于运行时增强,主要具有如下特点:
基于动态代理来实现,默认如果使用接口的,用 JDK 提供的动态代理实现,如果是方法则使用 CGLIB 实现
Spring AOP 需要依赖 IoC 容器来管理,并且只能作用于 Spring 容器,使用纯 Java 代码实现
在性能上,由于 Spring AOP 是基于动态代理来实现的,在容器启动时需要生成代理实例,在方法调用上也会增加栈的深度,使得 Spring AOP 的性能不如 AspectJ 的那么好。
Spring AOP 致力于解决企业级开发中最普遍的 AOP(方法织入)。
AspectJ
AspectJ 是一个易用的功能强大的 AOP 框架,属于编译时增强, 可以单独使用,也可以整合到其它框架中,是 AOP 编程的完全解决方案。AspectJ 需要用到单独的编译器 ajc。
AspectJ 属于静态织入,通过修改代码来实现,在实际运行之前就完成了织入,所以说它生成的类是没有额外运行时开销的,一般有如下几个织入的时机:
编译期织入(Compile-time weaving):如类 A 使用 AspectJ 添加了一个属性,类 B 引用了它,这个场景就需要编译期的时候就进行织入,否则没法编译类 B。
编译后织入(Post-compile weaving):也就是已经生成了 .class 文件,或已经打成 jar 包了,这种情况我们需要增强处理的话,就要用到编译后织入。
类加载后织入(Load-time weaving):指的是在加载类的时候进行织入,要实现这个时期的织入,有几种常见的方法
20.Spring 事务的种类?
在 Spring 中,事务管理可以分为两大类:声明式事务管理和编程式事务管理。
编程式事务可以使用 TransactionTemplate 和 PlatformTransactionManager 来实现,需要显式执行事务。允许我们在代码中直接控制事务的边界,通过编程方式明确指定事务的开始、提交和回滚。
public class AccountService {
private TransactionTemplate transactionTemplate;
public void setTransactionTemplate(TransactionTemplate transactionTemplate) {
this.transactionTemplate = transactionTemplate;
}
public void transfer(final String out, final String in, final Double money) {
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
@Override
protected void doInTransactionWithoutResult(TransactionStatus status) {
// 转出
accountDao.outMoney(out, money);
// 转入
accountDao.inMoney(in, money);
}
});
}
}
在上面的代码中,我们使用了 TransactionTemplate 来实现编程式事务,通过 execute 方法来执行事务,这样就可以在方法内部实现事务的控制。
声明式事务是建立在 AOP 之上的。其本质是通过 AOP 功能,对方法前后进行拦截,将事务处理的功能编织到拦截的方法中,也就是在目标方法开始之前启动一个事务,在目标方法执行完之后根据执行情况提交或者回滚事务。
相比较编程式事务,优点是不需要在业务逻辑代码中掺杂事务管理的代码, Spring 推荐通过 @Transactional 注解的方式来实现声明式事务管理,也是日常开发中最常用的。
不足的地方是,声明式事务管理最细粒度只能作用到方法级别,无法像编程式事务那样可以作用到代码块级别。
@Service
public class AccountService {
@Autowired
private AccountDao accountDao;
@Transactional
public void transfer(String out, String in, Double money) {
// 转出
accountDao.outMoney(out, money);
// 转入
accountDao.inMoney(in, money);
}
}
- 编程式事务管理:需要在代码中显式调用事务管理的 API 来控制事务的边界,比较灵活,但是代码侵入性较强,不够优雅。
- 声明式事务管理:这种方式使用 Spring 的 AOP 来声明事务,将事务管理代码从业务代码中分离出来。优点是代码简洁,易于维护。但缺点是不够灵活,只能在预定义的方法上使用事务。
21.Spring的事务隔离级别?
在 Spring 中,事务隔离级别(Transaction Isolation Level)定义了一个事务与其他事务之间的隔离程度。不同的隔离级别可以防止不同类型的并发问题,如脏读(Dirty Read)、不可重复读(Non-repeatable Read)和幻读(Phantom Read)。Spring 事务管理支持以下几种隔离级别:
1. ISOLATION_DEFAULT
描述:这是 Spring 的默认隔离级别,使用底层数据库的默认隔离级别。对于大多数数据库来说,默认隔离级别通常是 READ_COMMITTED。MySQL 默认的是可重复读,Oracle 默认的读已提交。
2. ISOLATION_READ_UNCOMMITTED
描述:允许一个事务读取另一个事务未提交的数据。这种隔离级别可能会导致脏读、不可重复读和幻读。
并发问题:
- 脏读(Dirty Read):一个事务读取了另一个事务未提交的数据。
- 不可重复读(Non-repeatable Read):一个事务在两次读取之间,另一个事务修改了数据。
- 幻读(Phantom Read):一个事务在两次读取之间,另一个事务插入了新的数据。
3. ISOLATION_READ_COMMITTED
描述:一个事务只能读取另一个事务已提交的数据。这种隔离级别可以防止脏读,但仍然可能会出现不可重复读和幻读。
并发问题:
- 不可重复读(Non-repeatable Read):一个事务在两次读取之间,另一个事务修改了数据。
- 幻读(Phantom Read):一个事务在两次读取之间,另一个事务插入了新的数据。
4. ISOLATION_REPEATABLE_READ
描述:确保在同一个事务中多次读取数据时,数据是一致的。这种隔离级别可以防止脏读和不可重复读,但仍然可能会出现幻读。
并发问题:
- 幻读(Phantom Read):一个事务在两次读取之间,另一个事务插入了新的数据。
5. ISOLATION_SERIALIZABLE
描述:这是最高的隔离级别,确保事务完全隔离。这种隔离级别可以防止脏读、不可重复读和幻读,但代价是性能较低,因为它通常通过锁定表或行来实现, 但性能影响也最大。
并发问题:
- 无并发问题。
示例
以下是如何在 Spring 中设置事务隔离级别的示例:
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Isolation;
import org.springframework.transaction.annotation.Transactional;
@Service
public class AccountService {
@Transactional(isolation = Isolation.READ_COMMITTED)
public void transfer(String out, String in, Double money) {
// 转出
accountDao.outMoney(out, money);
// 转入
accountDao.inMoney(in, money);
}
}
在上面的示例中,@Transactional 注解的 isolation 属性用于设置事务的隔离级别。在这个例子中,事务的隔离级别被设置为 READ_COMMITTED。
总结- 21
Spring 支持以下几种事务隔离级别:
- ISOLATION_DEFAULT:使用底层数据库的默认隔离级别。
- ISOLATION_READ_UNCOMMITTED:允许读取未提交的数据,可能会导致脏读、不可重复读和幻读。
- ISOLATION_READ_COMMITTED:只能读取已提交的数据,防止脏读,但可能会出现不可重复读和幻读。
- ISOLATION_REPEATABLE_READ:确保多次读取数据时数据一致,防止脏读和不可重复读,但可能会出现幻读。
- ISOLATION_SERIALIZABLE:最高的隔离级别,确保事务完全隔离,防止所有并发问题,但性能较低。
通过理解和选择合适的事务隔离级别,可以在保证数据一致性的同时,提高应用程序的性能。
22.Spring 的事务传播机制?
Spring 的事务传播机制定义了事务在不同方法调用之间的传播方式。通过设置事务传播属性,可以控制事务在方法调用过程中如何传播和管理。Spring 提供了多种事务传播行为,主要包括以下几种:
1. PROPAGATION_REQUIRED
描述:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
应用场景:这是最常用的传播行为,适用于大多数业务场景。
2. PROPAGATION_REQUIRES_NEW
描述:创建一个新的事务,如果当前存在事务,则挂起当前事务。
应用场景:适用于需要在一个新的事务中执行操作,并且不受当前事务影响的场景。
3. PROPAGATION_SUPPORTS
描述:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务方式执行。
应用场景:适用于既可以在事务中执行,也可以在非事务中执行的场景。
4. PROPAGATION_NOT_SUPPORTED
描述:以非事务方式执行操作,如果当前存在事务,则挂起当前事务。
应用场景:适用于不需要事务支持的操作,并且需要确保当前没有事务的场景。
5. PROPAGATION_NEVER
描述:以非事务方式执行,如果当前存在事务,则抛出异常。
应用场景:适用于必须确保当前没有事务的场景。
6. PROPAGATION_MANDATORY
描述:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
应用场景:适用于必须在现有事务中执行的操作。
7. PROPAGATION_NESTED
描述:如果当前存在事务,则创建一个事务嵌套(Savepoint);如果当前没有事务,则创建一个新的事务。
应用场景:适用于需要在一个事务中执行多个子事务,并且子事务可以独立回滚的场景。
事务传播的机制实现
事务传播机制是使用 ThreadLocal 实现的,所以,如果调用的方法是在新线程中,事务传播会失效。
@Transactional
public void parentMethod() {
new Thread(() -> childMethod()).start();
}
public void childMethod() {
// 这里的操作将不会在 parentMethod 的事务范围内执行
}
Spring 默认的事务传播行为是 PROPAFATION_REQUIRED,即如果多个 ServiceX#methodX() 都工作在事务环境下,且程序中存在这样的调用链 Service1#method1()->Service2#method2()->Service3#method3(),那么这 3 个服务类的 3 个方法都通过 Spring 的事务传播机制工作在同一个事务中。
总结- 22
Spring 提供了多种事务传播行为,用于控制事务在不同方法调用之间的传播方式:
- PROPAGATION_REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
- PROPAGATION_REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则挂起当前事务。
- PROPAGATION_SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务方式执行。
- PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,则挂起当前事务。
- PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
- PROPAGATION_MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
- PROPAGATION_NESTED:如果当前存在事务,则创建一个事务嵌套;如果当前没有事务,则创建一个新的事务。
通过理解和选择合适的事务传播行为,可以更灵活地控制事务的传播和管理,确保数据的一致性和完整性。
23.protected 和 private 加事务会生效吗
在 Spring 中,只有通过 Spring 容器的 AOP 代理调用的公开方法(public method)上的@Transactional注解才会生效。
如果在 protected、private 方法上使用@Transactional,这些事务注解将不会生效,原因:Spring 默认使用基于 JDK 的动态代理(当接口存在时)或基于 CGLIB 的代理(当只有类时)来实现事务。这两种代理机制都只能代理公开的方法。
23.声明式事务实现原理了解吗?
Spring 的声明式事务管理是通过 AOP(面向切面编程)和代理机制实现的。
第一步,在 Bean 初始化阶段创建代理对象:
Spring 容器在初始化单例 Bean 的时候,会遍历所有的 BeanPostProcessor 实现类,并执行其 postProcessAfterInitialization 方法。
在执行 postProcessAfterInitialization 方法时会遍历容器中所有的切面,查找与当前 Bean 匹配的切面,这里会获取事务的属性切面,也就是 @Transactional 注解及其属性值。
然后根据得到的切面创建一个代理对象,默认使用 JDK 动态代理创建代理,如果目标类是接口,则使用 JDK 动态代理,否则使用 Cglib。
第二步,在执行目标方法时进行事务增强操作:
当通过代理对象调用 Bean 方法的时候,会触发对应的 AOP 增强拦截器,声明式事务是一种环绕增强,对应接口为MethodInterceptor,事务增强对该接口的实现为TransactionInterceptor
事务拦截器TransactionInterceptor在invoke方法中,通过调用父类TransactionAspectSupport的invokeWithinTransaction方法进行事务处理,包括开启事务、事务提交、异常回滚等。
24.声明式事务在哪些情况下会失效?
@Transactional 应用在非 public 修饰的方法上
如果 Transactional 注解应用在非 public 修饰的方法上,Transactional 将会失效。
是因为在 Spring AOP 代理时,TransactionInterceptor (事务拦截器)在目标方法执行前后进行拦截,DynamicAdvisedInterceptor(CglibAopProxy 的内部类)的 intercept 方法或 JdkDynamicAopProxy 的 invoke 方法会间接调用 AbstractFallbackTransactionAttributeSource 的 computeTransactionAttribute方法,获取 Transactional 注解的事务配置信息。
protected TransactionAttribute computeTransactionAttribute(Method method,
Class<?> targetClass) {
// Don't allow no-public methods as required.
if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) {
return null;
}
}
此方法会检查目标方法的修饰符是否为 public,不是 public 则不会获取 @Transactional 的属性配置信息。
@Transactional 注解属性 propagation 设置错误
- TransactionDefinition.PROPAGATION_SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务方式执行;错误使用场景:在业务逻辑必须运行在事务环境下以确保数据一致性的情况下使用 SUPPORTS。
- TransactionDefinition.PROPAGATION_NOT_SUPPORTED:总是以非事务方式执行,如果当前存在事务,则挂起该事务。错误使用场景:在需要事务支持的操作中使用 NOT_SUPPORTED。
- TransactionDefinition.PROPAGATION_NEVER:总是以非事务方式执行,如果当前存在事务,则抛出异常。错误使用场景:在应该在事务环境下执行的操作中使用 NEVER。
@Transactional 注解属性 rollbackFor 设置错误
rollbackFor 用来指定能够触发事务回滚的异常类型。Spring 默认抛出未检查 unchecked 异常(继承自 RuntimeException 的异常)或者 Error 才回滚事务,其他异常不会触发回滚事务。
// 希望自定义的异常可以进行回滚
@Transactional(propagation= Propagation.REQUIRED,rollbackFor= MyException.class)
若在目标方法中抛出的异常是 rollbackFor 指定的异常的子类,事务同样会回滚。
同一个类中方法调用,导致@Transactional 失效
开发中避免不了会对同一个类里面的方法调用,比如有一个类 Test,它的一个方法 A,A 调用本类的方法 B(不论方法 B 是用 public 还是 private 修饰),但方法 A 没有声明注解事务,而 B 方法有。
则外部调用方法 A 之后,方法 B 的事务是不会起作用的。这也是经常犯错误的一个地方。
那为啥会出现这种情况呢?其实还是由 Spring AOP 代理造成的,因为只有事务方法被当前类以外的代码调用时,才会由 Spring 生成的代理对象来管理。
//@Transactional
@GetMapping("/test")
private Integer A() throws Exception {
CityInfoDict cityInfoDict = new CityInfoDict();
cityInfoDict.setCityName("2");
/**
* B 插入字段为 3的数据
*/
this.insertB();
/**
* A 插入字段为 2的数据
*/
int insert = cityInfoDictMapper.insert(cityInfoDict);
return insert;
}
@Transactional()
public Integer insertB() throws Exception {
CityInfoDict cityInfoDict = new CityInfoDict();
cityInfoDict.setCityName("3");
cityInfoDict.setParentCityId(3);
return cityInfoDictMapper.insert(cityInfoDict);
}
这种情况是最常见的一种@Transactional 注解失效场景。
@Transactional
private Integer A() throws Exception {
int insert = 0;
try {
CityInfoDict cityInfoDict = new CityInfoDict();
cityInfoDict.setCityName("2");
cityInfoDict.setParentCityId(2);
/**
* A 插入字段为 2的数据
*/
insert = cityInfoDictMapper.insert(cityInfoDict);
/**
* B 插入字段为 3的数据
*/
b.insertB();
} catch (Exception e) {
e.printStackTrace();
}
}
如果 B 方法内部抛了异常,而 A 方法此时 try catch 了 B 方法的异常,那这个事务就不能正常回滚了,会抛出异常:
25.Spring MVC 的核心组件?
- DispatcherServlet:前置控制器,是整个流程控制的核心,控制其他组件的执行,进行统一调度,降低组件之间的耦合性,相当于总指挥。
- Handler:处理器,完成具体的业务逻辑,相当于 Servlet 或 Action。
- HandlerMapping:DispatcherServlet 接收到请求之后,通过 - - HandlerMapping 将不同的请求映射到不同的 Handler。
- HandlerInterceptor:处理器拦截器,是一个接口,如果需要完成一些拦截处理,可以实现该接口。
- HandlerExecutionChain:处理器执行链,包括两部分内容:Handler 和 HandlerInterceptor(系统会有一个默认的 HandlerInterceptor,如果需要额外设置拦截,可以添加拦截器)。
- HandlerAdapter:处理器适配器,Handler 执行业务方法之前,需要进行一系列的操作,包括表单数据的验证、数据类型的转换、将表单数据封装到 JavaBean 等,这些操作都是由 HandlerApater 来完成,开发者只需将注意力集中业务逻辑的处理上,DispatcherServlet 通过 HandlerAdapter 执行不同的 Handler。
- ModelAndView:装载了模型数据和视图信息,作为 Handler 的处理结果,返回给 DispatcherServlet。
- ViewResolver:视图解析器,DispatcheServlet 通过它将逻辑视图解析为物理视图,最终将渲染结果响应给客户端。
26.Spring MVC 的工作流程?
Spring MVC 是基于模型-视图-控制器的 Web 框架,它的工作流程也主要是围绕着 Model、View、Controller 这三个组件展开的。
①、发起请求:客户端通过 HTTP 协议向服务器发起请求。
②、前端控制器:这个请求会先到前端控制器 DispatcherServlet,它是整个流程的入口点,负责接收请求并将其分发给相应的处理器。
③、处理器映射:DispatcherServlet 调用 HandlerMapping 来确定哪个 Controller 应该处理这个请求。通常会根据请求的 URL 来确定。
④、处理器适配器:一旦找到目标 Controller,DispatcherServlet 会使用 HandlerAdapter 来调用 Controller 的处理方法。
⑤、执行处理器:Controller 处理请求,处理完后返回一个 ModelAndView 对象,其中包含模型数据和逻辑视图名。
⑥、视图解析器:DispatcherServlet 接收到 ModelAndView 后,会使用 ViewResolver 来解析视图名称,找到具体的视图页面。
⑦、渲染视图:视图使用模型数据渲染页面,生成最终的页面内容。
⑧、响应结果:DispatcherServlet 将视图结果返回给客户端。
Spring MVC 虽然整体流程复杂,但是实际开发中很简单,大部分的组件不需要我们开发人员创建和管理,真正需要处理的只有 Controller 、View 、Model。
在前后端分离的情况下,步骤 ⑥、⑦、⑧ 会略有不同,后端通常只需要处理数据,并将 JSON 格式的数据返回给前端就可以了,而不是返回完整的视图页面。
Handler 一般就是指 Controller,Controller 是 Spring MVC 的核心组件,负责处理请求,返回响应。
Spring MVC 允许使用多种类型的处理器。不仅仅是标准的@Controller注解的类,还可以是实现了特定接口的其他类(如 HttpRequestHandler 或 SimpleControllerHandlerAdapter 等)。这些处理器可能有不同的方法签名和交互方式。
HandlerAdapter 的主要职责就是调用 Handler 的方法来处理请求,并且适配不同类型的处理器。HandlerAdapter 确保 DispatcherServlet 可以以统一的方式调用不同类型的处理器,无需关心具体的执行细节。
27.SpringMVC Restful 风格的接口的流程是什么样的呢?
我们都知道 Restful 接口,响应格式是 json,这就用到了一个常用注解:@ResponseBody
@GetMapping("/user")
@ResponseBody
public User user(){
return new User(1,"张三");
}
加入了这个注解后,整体的流程上和使用 ModelAndView 大体上相同,但是细节上有一些不同:
客户端向服务端发送一次请求,这个请求会先到前端控制器 DispatcherServlet
DispatcherServlet 接收到请求后会调用 HandlerMapping 处理器映射器。由此得知,该请求该由哪个 Controller 来处理
DispatcherServlet 调用 HandlerAdapter 处理器适配器,告诉处理器适配器应该要去执行哪个 Controller
Controller 被封装成了 ServletInvocableHandlerMethod,HandlerAdapter 处理器适配器去执行 invokeAndHandle 方法,完成对 Controller 的请求处理
HandlerAdapter 执行完对 Controller 的请求,会调用 HandlerMethodReturnValueHandler 去处理返回值,主要的过程:
-
调用 RequestResponseBodyMethodProcessor,创建 ServletServerHttpResponse(Spring 对原生 ServerHttpResponse 的封装)实例
-
使用 HttpMessageConverter 的 write 方法,将返回值写入 ServletServerHttpResponse 的 OutputStream 输出流中
-
在写入的过程中,会使用 JsonGenerator(默认使用 Jackson 框架)对返回值进行 Json 序列化
执行完请求后,返回的 ModealAndView 为 null,ServletServerHttpResponse 里也已经写入了响应,所以不用关心 View 的处理
28.介绍一下 SpringBoot,有哪些优点?
Spring Boot 是由 Pivotal 团队提供的一个框架,用于简化 Spring 应用的创建、配置和部署。它基于 Spring 框架,提供了一种快速构建生产级 Spring 应用的方式。Spring Boot 通过约定优于配置(Convention over Configuration)的理念,减少了开发人员的工作量,使得开发过程更加高效。
Spring Boot 的优点
- 快速入门:
- Spring Boot 提供了大量的开箱即用的功能,通过简化配置和自动化配置,使得开发人员可以快速启动一个新的 Spring 项目。
- 提供了 Spring Initializr 工具,可以通过 Web 界面或命令行快速生成项目骨架。
- 自动配置:
- Spring Boot 提供了自动配置功能,可以根据项目中的依赖和配置自动配置 Spring 应用,无需手动编写大量的配置文件。
- 自动配置可以通过注解
@EnableAutoConfiguration或@SpringBootApplication启用。
- 内嵌服务器:
- Spring Boot 支持内嵌的 Web 服务器,如 Tomcat、Jetty 和 Undertow,使得应用可以打包成一个可执行的 JAR 文件,直接运行,无需外部服务器。
- 这简化了部署过程,特别适合微服务架构。
- 简化的依赖管理:
- Spring Boot 提供了依赖管理的起步依赖(Starters),这些起步依赖是预先定义的一组依赖,可以简化 Maven 或 Gradle 配置。
- 例如,
spring-boot-starter-web包含了构建 Web 应用所需的所有依赖。
- 生产级特性:
- Spring Boot 提供了许多生产级特性,如监控、度量、健康检查和外部化配置。
- 通过
spring-boot-starter-actuator起步依赖,可以轻松添加这些特性。
- 外部化配置:
- Spring Boot 支持通过外部配置文件(如
application.properties或application.yml)来配置应用。 - 支持多种配置源,如环境变量、命令行参数、配置服务器等。
- Spring Boot 支持通过外部配置文件(如
- 开发者友好:
- Spring Boot 提供了开发者工具(DevTools),可以实现热部署、自动重启和调试功能,提高开发效率。
- 提供了丰富的日志和错误信息,帮助开发者快速定位和解决问题。
- 社区支持:
- Spring Boot 拥有庞大的社区支持和丰富的文档资源,开发者可以轻松找到所需的帮助和示例。
- 定期发布新版本,持续改进和更新。
示例代码
以下是一个简单的 Spring Boot 应用示例,展示了如何快速创建一个 RESTful Web 服务:
1. 创建 Spring Boot 项目
可以通过 Spring Initializr 工具生成项目骨架,选择需要的依赖,如 Spring Web。
2. 主应用类
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class MySpringBootApplication {
public static void main(String[] args) {
SpringApplication.run(MySpringBootApplication.class, args);
}
}
3. 控制器类
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class MyController {
@GetMapping("/hello")
public String hello() {
return "Hello, Spring Boot!";
}
}
4. 配置文件(application.properties)
server.port=8080
总结- 29
Spring Boot 是一个强大的框架,提供了快速构建、配置和部署 Spring 应用的能力。其主要优点包括:
- 快速入门:简化配置和自动化配置,快速启动新项目。
- 自动配置:根据依赖和配置自动配置应用。
- 内嵌服务器:支持内嵌 Web 服务器,简化部署。
- 简化的依赖管理:提供起步依赖,简化依赖管理。
- 生产级特性:提供监控、度量、健康检查等生产级特性。
- 外部化配置:支持通过外部配置文件配置应用。
- 开发者友好:提供开发者工具,提高开发效率。
- 社区支持:拥有庞大的社区支持和丰富的文档资源。
通过理解和利用这些优点,开发者可以更高效地构建和部署 Spring 应用。
30.SpringBoot 自动配置原理了解吗?
在 Spring 中,自动装配是指容器利用反射技术,根据 Bean 的类型、名称等自动注入所需的依赖。
在 Spring Boot 中,开启自动装配的注解是@EnableAutoConfiguration。
Spring Boot 为了进一步简化,直接通过 @SpringBootApplication 注解一步搞定,这个注解包含了 @EnableAutoConfiguration 注解。
①、@EnableAutoConfiguration 只是一个简单的注解,但是它的背后却是一个非常复杂的自动装配机制,核心是AutoConfigurationImportSelector 类。
@AutoConfigurationPackage //将main同级的包下的所有组件注册到容器中
@Import({AutoConfigurationImportSelector.class}) //加载自动装配类 xxxAutoconfiguration
public @interface EnableAutoConfiguration {
String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
Class<?>[] exclude() default {};
String[] excludeName() default {};
}
②、AutoConfigurationImportSelector实现了ImportSelector接口,这个接口的作用就是收集需要导入的配置类,配合@Import()就将相应的类导入到 Spring 容器中。
③、获取注入类的方法是 selectImports(),它实际调用的是getAutoConfigurationEntry(),这个方法是获取自动装配类的关键。
protected AutoConfigurationEntry getAutoConfigurationEntry(AnnotationMetadata annotationMetadata) {
// 检查自动配置是否启用。如果@ConditionalOnClass等条件注解使得自动配置不适用于当前环境,则返回一个空的配置条目。
if (!isEnabled(annotationMetadata)) {
return EMPTY_ENTRY;
}
// 获取启动类上的@EnableAutoConfiguration注解的属性,这可能包括对特定自动配置类的排除。
AnnotationAttributes attributes = getAttributes(annotationMetadata);
// 从spring.factories中获取所有候选的自动配置类。这是通过加载META-INF/spring.factories文件中对应的条目来实现的。
List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes);
// 移除配置列表中的重复项,确保每个自动配置类只被考虑一次。
configurations = removeDuplicates(configurations);
// 根据注解属性解析出需要排除的自动配置类。
Set<String> exclusions = getExclusions(annotationMetadata, attributes);
// 检查排除的类是否存在于候选配置中,如果存在,则抛出异常。
checkExcludedClasses(configurations, exclusions);
// 从候选配置中移除排除的类。
configurations.removeAll(exclusions);
// 应用过滤器进一步筛选自动配置类。过滤器可能基于条件注解如@ConditionalOnBean等来排除特定的配置类。
configurations = getConfigurationClassFilter().filter(configurations);
// 触发自动配置导入事件,允许监听器对自动配置过程进行干预。
fireAutoConfigurationImportEvents(configurations, exclusions);
// 创建并返回一个包含最终确定的自动配置类和排除的配置类的AutoConfigurationEntry对象。
return new AutoConfigurationEntry(configurations, exclusions);
}
Spring Boot 的自动装配原理依赖于 Spring 框架的依赖注入和条件注册,通过这种方式,Spring Boot 能够智能地配置 bean,并且只有当这些 bean 实际需要时才会被创建和配置。
31.如何自定义一个 SpringBoot Srarter?
创建一个自定义的 Spring Boot Starter,需要这几步:
第一步,创建一个新的 Maven 项目,例如命名为 my-spring-boot-starter。在 pom.xml 文件中添加必要的依赖和配置:
<properties>
<spring.boot.version>2.3.1.RELEASE</spring.boot.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
<version>${spring.boot.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<version>${spring.boot.version}</version>
</dependency>
</dependencies>
第二步,在 src/main/java 下创建一个自动配置类,比如 MyServiceAutoConfiguration.java:(通常是 autoconfigure 包下)。
@Configuration
@EnableConfigurationProperties(MyStarterProperties.class)
public class MyServiceAutoConfiguration {
@Bean
@ConditionalOnMissingBean
public MyService myService(MyStarterProperties properties) {
return new MyService(properties.getMessage());
}
}
第三步,创建一个配置属性类 MyStarterProperties.java:
@ConfigurationProperties(prefix = "mystarter")
public class MyStarterProperties {
private String message = "Hello Java !";
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
}
第四步,创建一个简单的服务类 MyService.java:
public class MyService {
private final String message;
public MyService(String message) {
this.message = message;
}
public String getMessage() {
return message;
}
}
第五步,配置 spring.factories,在 src/main/resources/META-INF 目录下创建 spring.factories 文件,并添加:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.itwanger.mystarter.autoconfigure.MyServiceAutoConfiguration
第六步,使用 Maven 打包这个项目:
mvn clean install
第七步,在其他的 Spring Boot 项目中,通过 Maven 来添加这个自定义的 Starter 依赖,并通过 application.properties 配置欢迎消息:
mystarter.message=javabetter.cn
然后就可以在 Spring Boot 项目中注入 MyStarterProperties 来使用它
32.Spring Boot Starter 的原理了解吗?
Spring Boot Starter 主要通过起步依赖和自动配置机制来简化项目的构建和配置过程。
起步依赖是 Spring Boot 提供的一组预定义依赖项,它们将一组相关的库和模块打包在一起。比如 spring-boot-starter-web 就包含了 Spring MVC、Tomcat 和 Jackson 等依赖。
自动配置机制是 Spring Boot 的核心特性,通过自动扫描类路径下的类、资源文件和配置文件,自动创建和配置应用程序所需的 Bean 和组件。
比如有了 spring-boot-starter-web,我们开发者就不需要再手动配置 Tomcat、Spring MVC 等,Spring Boot 会自动帮我们完成这些工作。
33.Spring Boot 启动原理了解吗?
Spring Boot 应用通常有一个带有 main 方法的主类,这个类上标注了 @SpringBootApplication 注解,它是整个应用启动的入口。这个注解组合了 @SpringBootConfiguration、@EnableAutoConfiguration 和 @ComponentScan,这些注解共同支持配置和类路径扫描。
当执行 main 方法时,首先创建一个 SpringApplication 的实例。这个实例负责管理 Spring 应用的启动和初始化。
SpringApplication.run() 方法负责准备和启动 Spring 应用上下文(ApplicationContext)环境,包括:
- 扫描配置文件,添加依赖项
- 初始化和加载 Bean 定义
- 启动内嵌的 Web 服务器
了解@SpringBootApplication 注解吗?
@SpringBootApplication是 Spring Boot 的核心注解,经常用于主类上,作为项目启动入口的标识。它是一个组合注解:
- @SpringBootConfiguration:继承自 @Configuration,标注该类是一个配置类,相当于一个 Spring 配置文件。
- @EnableAutoConfiguration:告诉 Spring Boot 根据 pom.xml 中添加的依赖自动配置项目。例如,如果 spring-boot-starter-web 依赖被添加到项目中,Spring Boot 会自动配置 Tomcat 和 Spring MVC。
- @ComponentScan:扫描当前包及其子包下被@Component、@Service、@Controller、@Repository 注解标记的类,并注册为 Spring Bean。
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
为什么 Spring Boot 在启动的时候能够找到 main 方法上的@SpringBootApplication 注解?
Spring Boot 在启动时能够找到主类上的@SpringBootApplication注解,是因为它利用了 Java 的反射机制和类加载机制,结合 Spring 框架内部的一系列处理流程。
当运行一个 Spring Boot 程序时,通常会调用主类中的main方法,这个方法会执行SpringApplication.run(),比如:
@SpringBootApplication
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}
SpringApplication.run(Class<?> primarySource, String… args)方法接收两个参数:第一个是主应用类(即包含main方法的类),第二个是命令行参数。primarySource参数提供了一个起点,Spring Boot 通过它来加载应用上下文。
Spring Boot 利用 Java 反射机制来读取传递给run方法的类(MyApplication.class)。它会检查这个类上的注解,包括@SpringBootApplication。
Spring Boot 默认的包扫描路径是什么?
Spring Boot 的默认包扫描路径是以启动类 @SpringBootApplication 注解所在的包为根目录的,即默认情况下,Spring Boot 会扫描启动类所在包及其子包下的所有组件。
@SpringBootApplication 是一个组合注解,它里面的@ComponentScan注解可以指定要扫描的包路径,默认扫描启动类所在包及其子包下的所有组件。
@ComponentScan(excludeFilters = { @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
}
比如说带有 @Component、@Service、@Controller、@Repository 等注解的类都会被 Spring Boot 扫描到,并注册到 Spring 容器中。
如果需要自定义包扫描路径,可以在@SpringBootApplication注解上添加@ComponentScan注解,指定要扫描的包路径。
@SpringBootApplication
@ComponentScan(basePackages = {"com.github.paicoding.forum"})
public class QuickForumApplication {
public static void main(String[] args) {
SpringApplication.run(QuickForumApplication.class, args);
}
}
这种方式会覆盖默认的包扫描路径,只扫描com.github.paicoding.forum包及其子包下的所有组件。
34.SpringBoot 和 SpringMVC 的区别?
Spring MVC 是基于 Spring 框架的一个模块,提供了一种 Model-View-Controller(模型-视图-控制器)的开发模式。
Spring Boot 旨在简化 Spring 应用的配置和部署过程,提供了大量的自动配置选项,以及运行时环境的内嵌 Web 服务器,这样就可以更快速地开发一个 SpringMVC 的 Web 项目。
35.Spring Boot 和 Spring 有什么区别?
Spring Boot 是 Spring Framework 的一个扩展,提供了一套快速配置和开发的框架,可以帮助我们快速搭建 Spring 项目骨架,极大地提高了我们的生产效率。
| 特性 | Spring Framework | Spring Boot |
|---|---|---|
| 目的 | 提供全面的企业级开发工具和库 | 简化 Spring 应用的开发、配置和部署 |
| 配置方式 | 主要通过 XML 和注解配置 | 主要通过注解和外部配置文件 |
| 启动和运行 | 需要手动配置和部署到服务器 | 支持嵌入式服务器,打包成 JAR 文件直接运行 |
| 自动配置 | 手动配置各种组件和依赖 | 提供开箱即用的自动配置 |
| 依赖管理 | 手动添加和管理依赖 | 使用 spring-boot-starter 简化依赖管理 |
| 模块化 | 高度模块化,可以选择使用不同的模块 | 集成多个常用模块,提供统一的启动入口 |
| 生产准备功能 | 需要手动集成和配置 | 内置监控、健康检查等生产准备功能 |
36.对 SpringCloud 了解多少?
Spring Cloud 是一个基于 Spring Boot,提供构建分布式系统和微服务架构的工具集。用于解决分布式系统中的一些常见问题,如配置管理、服务发现、负载均衡等等。
Spring Cloud 的核心组件
- Spring Cloud Config:
- 提供集中化的配置管理,支持从 Git、SVN 等版本控制系统中读取配置。
- 支持动态刷新配置,方便在运行时更新配置而无需重启服务。
- Spring Cloud Netflix:
- 集成了 Netflix 的开源项目,如 Eureka、Ribbon、Hystrix、Zuul 等。
- Eureka:服务注册与发现。
- Ribbon:客户端负载均衡。
- Hystrix:断路器,提供容错机制。
- Zuul:API 网关,提供路由和过滤功能。
- Spring Cloud Gateway:
- 作为 Zuul 的替代品,提供更强大的路由和过滤功能。
- 支持动态路由、断路器、限流等功能。
- Spring Cloud OpenFeign:
- 声明式的 HTTP 客户端,简化了服务之间的通信。
- 集成了 Ribbon 和 Hystrix,提供负载均衡和容错机制。
- Spring Cloud Sleuth:
- 提供分布式追踪功能,帮助开发者跟踪请求在微服务中的流转路径。
- 集成了 Zipkin 和 ELK(Elasticsearch、Logstash、Kibana)等工具。
- Spring Cloud Stream:
- 提供消息驱动的微服务框架,支持与 Kafka、RabbitMQ 等消息中间件集成。
- 简化了消息的生产和消费,提供了统一的编程模型。
- Spring Cloud Bus:
- 用于传播集群中的配置变更事件,通常与 Spring Cloud Config 一起使用。
- 支持广播和点对点消息传递。
- Spring Cloud Security:
- 提供安全管理功能,支持 OAuth2 和 JWT 等认证和授权机制。
- 集成了 Spring Security,提供统一的安全解决方案。
Spring Cloud 的优点
- 简化微服务开发:
- 提供了大量开箱即用的组件,简化了微服务的开发和配置。
- 与 Spring Boot 无缝集成,利用 Spring Boot 的自动配置和依赖管理功能。
- 集中化配置管理:
- 通过 Spring Cloud Config 实现集中化配置管理,支持动态刷新配置。
- 提高了配置管理的效率和一致性。
- 服务注册与发现:
- 通过 Eureka 实现服务注册与发现,简化了服务之间的通信。
- 支持客户端负载均衡,提高了系统的可用性和扩展性。
- 容错机制:
- 通过 Hystrix 实现断路器和降级处理,提高了系统的容错能力。
- 提供了监控和报警功能,帮助开发者及时发现和处理问题。
- API 网关:
- 通过 Zuul 或 Spring Cloud Gateway 实现 API 网关,提供路由、过滤、限流等功能。
- 提高了系统的安全性和可维护性。
- 分布式追踪:
- 通过 Spring Cloud Sleuth 实现分布式追踪,帮助开发者跟踪请求在微服务中的流转路径。
- 提供了丰富的监控和分析工具,帮助开发者优化系统性能。
以下是一个简单的 Spring Cloud 示例,展示了如何使用 Spring Cloud Netflix Eureka 实现服务注册与发现:
1. 创建 Eureka 服务器
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
2. 创建服务提供者
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@SpringBootApplication
@EnableEurekaClient
public class ServiceProviderApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceProviderApplication.class, args);
}
}
@RestController
class HelloController {
@GetMapping("/hello")
public String hello() {
return "Hello from Service Provider!";
}
}
3. 创建服务消费者
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.DiscoveryClient;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@SpringBootApplication
@EnableEurekaClient
public class ServiceConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceConsumerApplication.class, args);
}
}
@RestController
class HelloController {
@Autowired
private DiscoveryClient discoveryClient;
@GetMapping("/hello")
public String hello() {
RestTemplate restTemplate = new RestTemplate();
String serviceUrl = discoveryClient.getInstances("service-provider")
.get(0)
.getUri()
.toString();
return restTemplate.getForObject(serviceUrl + "/hello", String.class);
}
}
总结- 36
Spring Cloud 是一个强大的框架,提供了丰富的工具和服务,用于构建和管理微服务架构。其核心组件包括 Spring Cloud Config、Spring Cloud Netflix、Spring Cloud Gateway、Spring Cloud OpenFeign、Spring Cloud Sleuth、Spring Cloud Stream、Spring Cloud Bus 和 Spring Cloud Security。通过理解和使用这些组件,开发者可以更高效地构建和管理分布式系统,提高系统的可用性、扩展性和可维护性。
37.SpringTask 了解吗?
SpringTask 是 Spring 框架提供的一个轻量级的任务调度框架,它允许我们开发者通过简单的注解来配置和管理定时任务。
①、@Scheduled:最常用的注解,用于标记方法为计划任务的执行点。
@Scheduled(cron = "0 15 5 * * ?")
public void autoRefreshCache() {
log.info("开始刷新sitemap.xml的url地址,避免出现数据不一致问题!");
refreshSitemap();
log.info("刷新完成!");
}
@Scheduled 注解支持多种调度选项,如 fixedRate、fixedDelay 和 cron 表达式。
②、@EnableScheduling:用于开启定时任务的支持。
订单超时,用springtask资源占用太高,有什么其他的方式解决?
第一,使用消息队列,如 RabbitMQ、Kafka、RocketMQ 等,将任务放到消息队列中,然后由消费者异步处理这些任务。
①、在订单创建时,将订单超时检查任务放入消息队列,并设置延迟时间(即订单超时时间)。
@Service
public class OrderService {
@Autowired
private RabbitTemplate rabbitTemplate;
public void createOrder(Order order) {
// 创建订单逻辑
// ...
// 发送延迟消息
rabbitTemplate.convertAndSend("orderExchange", "orderTimeoutQueue", order, message -> {
message.getMessageProperties().setExpiration("600000"); // 设置延迟时间(10分钟)
return message;
});
}
}
②、使用消费者从队列中消费消息,当消费到超时任务时,执行订单超时处理逻辑。
@Service
public class OrderTimeoutConsumer {
@RabbitListener(queues = "orderTimeoutQueue")
public void handleOrderTimeout(Order order) {
// 处理订单超时逻辑
// ...
}
}
第二,使用数据库调度器(如 Quartz)。
①、创建一个 Quartz 任务类,处理订单超时逻辑。
public class OrderTimeoutJob implements Job {
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
// 获取订单信息
Order order = (Order) context.getJobDetail().getJobDataMap().get("order");
// 处理订单超时逻辑
// ...
}
}
②、在订单创建时,调度一个 Quartz 任务,设置任务的触发时间为订单超时时间。
@Service
public class OrderService {
@Autowired
private Scheduler scheduler;
public void createOrder(Order order) {
// 创建订单逻辑
// ...
// 调度 Quartz 任务
JobDetail jobDetail = JobBuilder.newJob(OrderTimeoutJob.class)
.usingJobData("order", order)
.build();
Trigger trigger = TriggerBuilder.newTrigger()
.startAt(new Date(System.currentTimeMillis() + 600000)) // 设置触发时间(10分钟后)
.build();
try {
scheduler.scheduleJob(jobDetail, trigger);
} catch (SchedulerException e) {
e.printStackTrace();
}
}
}
Redis
1.说说什么是 Redis?
Redis 是 Remote Dictionary Service 三个单词中加粗字母的组合,是一种基于键值对(key-value)的 NoSQL 数据库。
但比一般的键值对,比如 HashMap 强大的多,Redis 中的 value 支持 string(字符串)、hash(哈希)、 list(列表)、set(集合)、zset(有序集合)、Bitmaps(位图)、 HyperLogLog(基数估算)、GEO(地理信息定位)等多种数据结构。
而且因为 Redis 的所有数据都存放在内存当中,所以它的读写性能非常出色。
不仅如此,Redis 还可以将内存数据持久化到硬盘上,这样在发生类似断电或者机器故障的时候,内存中的数据并不会“丢失”。
除此之外,Redis 还提供了键过期、发布订阅、事务、流水线、Lua 脚本等附加功能,是互联网技术领域中使用最广泛的缓存中间件。
Redis 和 MySQL 的区别?
- Redis:数据存储在内存中的 NoSQL 数据库,读写性能非常好,是互联网技术领域中使用最广泛的缓存中间件。
- MySQL:数据存储在硬盘中的关系型数据库,适用于需要事务支持和复杂查询的场景。
2.Redis 可以用来干什么?
Redis 可以用来实现多种功能,以下是一些常见的使用场景:
1. 缓存
- 数据库查询缓存:将频繁访问的数据库查询结果缓存到 Redis 中,减少数据库的压力,提高查询速度。
- 页面缓存:缓存整个页面或页面片段,减少服务器渲染压力,提高页面加载速度。
- 对象缓存:缓存复杂的对象或计算结果,减少重复计算,提高系统性能。
2. 会话管理
- 分布式会话:将用户会话数据存储在 Redis 中,实现分布式会话管理,适用于多节点部署的应用。
- 购物车:将用户的购物车数据存储在 Redis 中,确保数据的快速读写和持久化。
3. 分布式锁
- 分布式锁:使用 Redis 实现分布式锁,确保在分布式系统中只有一个实例在同一时间内执行某个操作,防止数据竞争和重复操作。
4. 消息队列
- 简单消息队列:使用 Redis 的列表或发布/订阅功能实现简单的消息队列,适用于任务调度、异步处理等场景。
- 事件通知:通过发布/订阅模式实现事件通知和实时消息系统。
5. 计数器和限流
- 计数器:使用 Redis 实现计数器,统计网站访问量、点赞数、评论数等。
- 限流器:使用 Redis 实现限流器,控制接口调用频率,防止系统过载。
6. 数据分析
- 实时数据分析:使用 Redis 的位图(Bitmap)、HyperLogLog 等数据结构进行实时数据分析和统计。
- 排行榜:使用 Redis 的有序集合(Sorted Set)实现排行榜功能,适用于积分排名、热度排名等场景。
7. 地理信息
- 地理位置存储和查询:使用 Redis 的 GEO 数据结构存储和查询地理位置信息,适用于附近的人、附近的店等场景。
8. 任务调度
- 延时任务:使用 Redis 实现延时任务调度,适用于订单超时处理、定时邮件发送等场景。
- 任务队列:使用 Redis 的列表实现任务队列,适用于任务调度和异步处理。
以下是一个使用 Redis 实现简单缓存的示例:
1. 添加依赖
在 pom.xml 文件中添加 Redis 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2. 配置 Redis
在 application.properties 文件中配置 Redis 连接信息:
spring.redis.host=localhost
spring.redis.port=6379
3. 使用 Redis 缓存数据库查询结果
创建一个服务类,使用 RedisTemplate 进行 Redis 操作:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
@Service
public class UserService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private UserRepository userRepository;
public User getUserById(Long userId) {
String key = "user:" + userId;
// 尝试从缓存中获取用户信息
User user = (User) redisTemplate.opsForValue().get(key);
if (user == null) {
// 如果缓存中没有,则从数据库中查询
user = userRepository.findById(userId).orElse(null);
if (user != null) {
// 将查询结果存入缓存,并设置过期时间
redisTemplate.opsForValue().set(key, user, 10, TimeUnit.MINUTES);
}
}
return user;
}
}
总结- 2
Redis 可以用于多种场景,包括缓存、会话管理、分布式锁、消息队列、计数器和限流、数据分析、地理信息和任务调度等。通过理解和利用 Redis 的这些功能,可以显著提高系统的性能和可扩展性。
3.Redis 有哪些数据类型?
Redis 支持多种数据类型,每种数据类型都有其特定的用途和操作。以下是 Redis 支持的主要数据类型及其常见操作:
1. 字符串(String)
- 描述:最基本的数据类型,可以存储任何形式的字符串,包括二进制数据。
- 常见操作:
SET key value:设置指定 key 的值。GET key:获取指定 key 的值。INCR key:将 key 的值加1(适用于整数)。DECR key:将 key 的值减1(适用于整数)。APPEND key value:将 value 追加到 key 原来的值之后。
- 使用场景:
- 缓存功能
- 计数
- 共享 Session
- 限速
2. 哈希(Hash)
- 描述:键值对集合,适用于存储对象。
- 常见操作:
HSET key field value:设置哈希表 key 中的字段 field 的值为 value。HGET key field:获取哈希表 key 中的字段 field 的值。HGETALL key:获取哈希表 key 中的所有字段和值。HDEL key field:删除哈希表 key 中的一个或多个指定字段。
- 使用场景:
- 缓存用户信息
- 缓存对象
3. 列表(List)
- 描述:有序的字符串列表,可以从两端插入和删除元素。
- 常见操作:
LPUSH key value:将一个值插入到列表头部。RPUSH key value:将一个值插入到列表尾部。LPOP key:移除并返回列表的头元素。RPOP key:移除并返回列表的尾元素。LRANGE key start stop:获取列表指定范围内的元素。
- 使用场景:
- 消息队列
- 文章列表
4. 集合(Set)
- 描述:无序的字符串集合,集合成员是唯一的。
- 常见操作:
SADD key member:向集合添加一个或多个成员。SREM key member:移除集合中的一个或多个成员。SMEMBERS key:返回集合中的所有成员。SISMEMBER key member:判断 member 元素是否是集合 key 的成员。
- 使用场景:
- 标签
- 共同关注
5. 有序集合(Sorted Set)
- 描述:类似集合,但每个元素都会关联一个分数,Redis 会根据分数自动排序。
- 常见操作:
ZADD key score member:向有序集合添加一个成员,并设置分数。ZREM key member:移除有序集合中的一个或多个成员。ZRANGE key start stop [WITHSCORES]:返回有序集合中指定范围内的成员。ZSCORE key member:返回有序集合中,成员的分数值。
- 使用场景:
- 用户点赞统计
- 用户排序
6. 位图(Bitmap)
- 描述:位数组,可以对字符串进行位操作。
- 常见操作:
SETBIT key offset value:对 key 所储存的字符串值,设置或清除指定偏移量上的位。GETBIT key offset:对 key 所储存的字符串值,获取指定偏移量上的位。BITCOUNT key [start end]:计算字符串中被设置为 1 的位的数量。
7. HyperLogLog
- 描述:用于基数统计的概率性数据结构,可以估算集合中唯一元素的数量。
- 常见操作:
PFADD key element [element ...]:添加指定元素到 HyperLogLog 中。PFCOUNT key [key ...]:返回给定 HyperLogLog 的基数估算值。PFMERGE destkey sourcekey [sourcekey ...]:将多个 HyperLogLog 合并为一个。
8. 地理空间(GEO)
- 描述:用于存储地理位置信息并进行操作。
- 常见操作:
GEOADD key longitude latitude member:将地理空间位置(经度、纬度、名称)添加到指定 key 中。GEODIST key member1 member2 [unit]:返回两个给定位置之间的距离。GEORADIUS key longitude latitude radius m|km|ft|mi:以给定的经纬度为中心,返回指定范围内的地理位置集合。
以下是一个使用 Redis 的哈希数据类型的示例:
在 pom.xml 文件中添加 Redis 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
在 application.properties 文件中配置 Redis 连接信息:
spring.redis.host=localhost
spring.redis.port=6379
3. 使用 Redis 哈希数据类型
创建一个服务类,使用 RedisTemplate 进行 Redis 操作:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
@Service
public class UserService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public void saveUser(String userId, String name, int age) {
String key = "user:" + userId;
redisTemplate.opsForHash().put(key, "name", name);
redisTemplate.opsForHash().put(key, "age", age);
}
public Object getUser(String userId) {
String key = "user:" + userId;
return redisTemplate.opsForHash().entries(key);
}
}
总结
Redis 支持多种数据类型,包括字符串、哈希、列表、集合、有序集合、位图、HyperLogLog 和地理空间。每种数据类型都有其特定的用途和操作,通过理解和利用这些数据类型,可以更高效地使用 Redis 进行数据存储和操作。
4.Redis 为什么快呢?
Redis 的速度非常快,单机的 Redis 就可以支撑每秒十几万的并发,性能是 MySQL 的几十倍。速度快的原因主要有几点:
①、基于内存的数据存储,Redis 将数据存储在内存当中,使得数据的读写操作避开了磁盘 I/O。而内存的访问速度远超硬盘,这是 Redis 读写速度快的根本原因。
②、单线程模型,Redis 使用单线程模型来处理客户端的请求,这意味着在任何时刻只有一个命令在执行。这样就避免了线程切换和锁竞争带来的消耗。
③、IO 多路复⽤,基于 Linux 的 select/epoll 机制。该机制允许内核中同时存在多个监听套接字和已连接套接字,内核会一直监听这些套接字上的连接请求或者数据请求,一旦有请求到达,就会交给 Redis 处理,就实现了所谓的 Redis 单个线程处理多个 IO 读写的请求。
④、高效的数据结构,Redis 提供了多种高效的数据结构,如字符串(String)、列表(List)、集合(Set)、有序集合(Sorted Set)等,这些数据结构经过了高度优化,能够支持快速的数据操作。
5.能说一下 I/O 多路复用吗?
I/O 多路复用(I/O Multiplexing)是一种高效的 I/O 模型,允许一个线程同时监视多个文件描述符(如套接字),一旦某个文件描述符准备好进行 I/O 操作(如读或写),线程就可以对其进行相应的操作。I/O 多路复用在高并发网络服务器中非常常用,因为它可以有效地管理大量的并发连接。
I/O 多路复用的工作原理
I/O 多路复用的核心思想是通过一个系统调用(如 select、poll 或 epoll)来监视多个文件描述符,并在其中任何一个文件描述符准备好进行 I/O 操作时通知应用程序。这样,应用程序可以在一个线程中高效地处理多个 I/O 事件。
常见的 I/O 多路复用机制
select:
- select 是最早的 I/O 多路复用机制,几乎在所有操作系统上都可用。
- 它使用一个固定大小的数组来存储文件描述符,并在每次调用时遍历整个数组,检查哪些文件描述符准备好进行 I/O 操作。
- 缺点是每次调用都需要遍历整个数组,效率较低,且支持的文件描述符数量有限。
poll:
- poll 是 select 的改进版,使用一个链表来存储文件描述符,避免了 select 的固定大小限制。
- 它的工作原理与 select 类似,但在处理大量文件描述符时效率仍然不高。
epoll:
- epoll 是 Linux 特有的 I/O 多路复用机制,专为高并发场景设计。
- 它使用一个红黑树和一个双向链表来管理文件描述符,支持动态添加和删除文件描述符。
- epoll 提供了 epoll_create、epoll_ctl 和 epoll_wait 三个系统调用,分别用于创建 epoll 实例、控制文件描述符和等待 I/O 事件。
- epoll 的效率非常高,因为它只在文件描述符状态发生变化时通知应用程序,而不是每次都遍历所有文件描述符。
Redis 中的 I/O 多路复用
Redis 使用 I/O 多路复用来处理客户端的并发连接。具体来说,Redis 使用 epoll(在 Linux 上)、kqueue(在 macOS 上)或 select(在其他操作系统上)来实现 I/O 多路复用。
Redis 的 I/O 多路复用机制使得它可以在单线程模型下高效地处理大量并发连接,避免了多线程上下文切换和锁竞争的问题。
6.Redis 为什么早期选择单线程?
官方 FAQ 表示,因为 Redis 是基于内存的操作,CPU 成为 Redis 的瓶颈的情况很少见,Redis 的瓶颈最有可能是内存的大小或者网络限制。
如果想要最大程度利用 CPU,可以在一台机器上启动多个 Redis 实例。
同时 FAQ 里还提到了, Redis 4.0 之后开始变成多线程,除了主线程外,它也有后台线程在处理一些较为缓慢的操作,例如清理脏数据、无用连接的释放、大 Key 的删除等等。
7.Redis6.0 使用多线程是怎么回事?
Redis 6.0 引入了多线程支持,以提高某些操作的性能,特别是网络 I/O 和命令处理。以下是 Redis 6.0 多线程的详细介绍:
1. 多线程的引入背景
- 性能瓶颈:虽然 Redis 早期版本使用单线程模型处理请求,但在高并发场景下,网络 I/O 和命令处理可能成为性能瓶颈。
- 硬件发展:随着多核 CPU 的普及,单线程模型无法充分利用多核 CPU 的计算能力。
2. 多线程的实现
Redis 6.0 引入了多线程来处理网络 I/O 和命令解析,但数据操作仍然在单线程中进行。这种设计确保了 Redis 的线程安全性,同时提高了并发处理能力。
多线程处理的部分
- 网络 I/O:多线程用于处理客户端的读写请求,减少了网络 I/O 的瓶颈。
- 命令解析:多线程用于解析客户端发送的命令,提高了命令处理的并发能力。
单线程处理的部分
- 数据操作:所有的数据操作仍然在单线程中进行,确保了数据的一致性和线程安全性。
- 事务:事务操作仍然在单线程中进行,避免了多线程带来的复杂性。
3. 多线程的配置
Redis 6.0 的多线程功能是可配置的,可以通过配置文件或命令行参数进行设置。
配置文件
在 Redis 配置文件 redis.conf 中,可以通过 io-threads 参数设置 I/O 线程的数量:
// 设置 I/O 线程的数量,默认为 1(即单线程)
io-threads 4
命令行参数
启动 Redis 时,可以通过 --io-threads 参数设置 I/O 线程的数量:
redis-server --io-threads 4
4. 多线程的优点
- 提高并发处理能力:多线程处理网络 I/O 和命令解析,提高了 Redis 的并发处理能力。
- 充分利用多核 CPU:多线程模型可以充分利用多核 CPU 的计算能力,提高系统性能。
- 保持数据一致性:数据操作仍然在单线程中进行,确保了数据的一致性和线程安全性。
以下是一个简单的 Redis 配置示例,展示了如何启用多线程:
配置文件 redis.conf
// 启用多线程,并设置 I/O 线程的数量为 4
io-threads 4
启动 Redis 服务器
redis-server redis.conf
6. 总结
Redis 6.0 引入了多线程支持,以提高网络 I/O 和命令处理的性能。多线程用于处理客户端的读写请求和命令解析,而数据操作仍然在单线程中进行,确保了数据的一致性和线程安全性。通过配置文件或命令行参数,可以灵活地设置 I/O 线程的数量,以充分利用多核 CPU 的计算能力,提高 Redis 的并发处理能力。
8.Redis 常用命令
Redis 提供了丰富的命令集,用于操作各种数据类型和管理 Redis 实例。以下是一些常用的 Redis 命令,按数据类型和功能分类:
1. 字符串(String)命令
SET key value:设置指定 key 的值。GET key:获取指定 key 的值。INCR key:将 key 的值加1(适用于整数)。DECR key:将 key 的值减1(适用于整数)。APPEND key value:将 value 追加到 key 原来的值之后。MSET key1 value1 key2 value2 ...:同时设置多个 key-value 对。MGET key1 key2 ...:获取多个 key 的值。
2. 哈希(Hash)命令
HSET key field value:设置哈希表 key 中的字段 field 的值为 value。HGET key field:获取哈希表 key 中的字段 field 的值。HGETALL key:获取哈希表 key 中的所有字段和值。HDEL key field:删除哈希表 key 中的一个或多个指定字段。HEXISTS key field:检查哈希表 key 中是否存在指定字段。HINCRBY key field increment:将哈希表 key 中的字段 field 的值加上指定增量(适用于整数)。
3. 列表(List)命令
LPUSH key value:将一个值插入到列表头部。RPUSH key value:将一个值插入到列表尾部。LPOP key:移除并返回列表的头元素。RPOP key:移除并返回列表的尾元素。LRANGE key start stop:获取列表指定范围内的元素。LLEN key:获取列表的长度。
4. 集合(Set)命令
SADD key member:向集合添加一个或多个成员。SREM key member:移除集合中的一个或多个成员。SMEMBERS key:返回集合中的所有成员。SISMEMBER key member:判断 member 元素是否是集合 key 的成员。SCARD key:获取集合的成员数。
5. 有序集合(Sorted Set)命令
ZADD key score member:向有序集合添加一个成员,并设置分数。ZREM key member:移除有序集合中的一个或多个成员。ZRANGE key start stop [WITHSCORES]:返回有序集合中指定范围内的成员。ZSCORE key member:返回有序集合中,成员的分数值。ZCARD key:获取有序集合的成员数。
6. 位图(Bitmap)命令
SETBIT key offset value:对 key 所储存的字符串值,设置或清除指定偏移量上的位。GETBIT key offset:对 key 所储存的字符串值,获取指定偏移量上的位。BITCOUNT key [start end]:计算字符串中被设置为 1 的位的数量。
7. HyperLogLog 命令
PFADD key element [element ...]:添加指定元素到 HyperLogLog 中。PFCOUNT key [key ...]:返回给定 HyperLogLog 的基数估算值。PFMERGE destkey sourcekey [sourcekey ...]:将多个 HyperLogLog 合并为一个。
8. 地理空间(GEO)命令
GEOADD key longitude latitude member:将地理空间位置(经度、纬度、名称)添加到指定 key 中。GEODIST key member1 member2 [unit]:返回两个给定位置之间的距离。GEORADIUS key longitude latitude radius m|km|ft|mi:以给定的经纬度为中心,返回指定范围内的地理位置集合。
9. 发布/订阅(Pub/Sub)命令
PUBLISH channel message:将信息发送到指定的频道。SUBSCRIBE channel [channel ...]:订阅一个或多个频道。UNSUBSCRIBE [channel ...]:退订一个或多个频道。
10. 事务(Transaction)命令
MULTI:标记一个事务块的开始。EXEC:执行所有事务块内的命令。DISCARD:取消事务块内的所有命令。WATCH key [key ...]:监视一个或多个 key,如果在事务执行之前这些 key 被修改,事务将被中止。
11. 脚本(Scripting)命令
EVAL script numkeys key [key ...] arg [arg ...]:执行 Lua 脚本。EVALSHA sha1 numkeys key [key ...] arg [arg ...]:执行缓存的 Lua 脚本。
12. 服务器(Server)命令
INFO:获取 Redis 服务器的各种信息和统计数据。CONFIG GET parameter:获取 Redis 配置参数的值。CONFIG SET parameter value:修改 Redis 配置参数的值。CLIENT LIST:获取连接到 Redis 服务器的客户端列表。MONITOR:实时打印出 Redis 服务器接收到的命令。
以下是一些常用 Redis 命令的示例代码:
// 字符串操作
SET mykey "Hello"
GET mykey
// 哈希操作
HSET myhash field1 "value1"
HGET myhash field1
// 列表操作
LPUSH mylist "World"
RPUSH mylist "Hello"
LRANGE mylist 0 -1
// 集合操作
SADD myset "one"
SADD myset "two"
SMEMBERS myset
// 有序集合操作
ZADD myzset 1 "one"
ZADD myzset 2 "two"
ZRANGE myzset 0 -1 WITHSCORES
// 发布/订阅操作
PUBLISH mychannel "Hello, World!"
SUBSCRIBE mychannel
9.单线程 Redis 的 QPS 是多少?
Redis 的 QPS(Queries Per Second,每秒查询数)取决于多种因素,包括硬件配置、操作类型、数据量和网络延迟等。在理想条件下,单线程 Redis 的 QPS 可以达到非常高的水平。
理想条件下的 QPS
在高性能硬件和优化的网络环境下,单线程 Redis 的 QPS 可以达到以下水平:
- 简单操作:对于简单的读写操作(如
GET和SET),Redis 的 QPS 可以达到 10 万到 20 万。 - 复杂操作:对于复杂的操作(如
LRANGE、ZADD等),QPS 会有所降低,但仍然可以达到数万。
影响 QPS 的因素
- 硬件配置:
- CPU:Redis 是 CPU 密集型应用,CPU 的性能对 QPS 有直接影响。高主频、多核 CPU 可以显著提高 Redis 的性能。
- 内存:充足的内存可以确保数据全部存储在内存中,避免磁盘 I/O 的瓶颈。
- 网络:低延迟、高带宽的网络环境可以减少网络传输的开销,提高 QPS。
- 操作类型:
- 简单操作:如
GET、SET等简单的键值操作,处理速度非常快,QPS 较高。 - 复杂操作:如
LRANGE、ZADD等涉及数据结构操作的命令,处理速度相对较慢,QPS 较低。
- 简单操作:如
- 数据量:
- 小数据量:数据量较小时,Redis 可以更快地处理请求,QPS 较高。
- 大数据量:数据量较大时,Redis 需要更多的时间进行数据操作,QPS 较低。
- 客户端数量:
- 并发客户端:更多的并发客户端可以提高 Redis 的 QPS,但也会增加 CPU 和网络的负载。
- 单客户端:单客户端的 QPS 受限于网络延迟和客户端的处理能力。
实际测试
在实际测试中,Redis 的 QPS 可能会受到上述因素的影响。以下是一些常见的测试工具和方法:
- redis-benchmark:
- Redis 自带的性能测试工具,可以模拟多种操作类型和并发客户端,测试 Redis 的 QPS。
-
示例命令:
redis-benchmark -t get,set -n 100000 -c 50该命令测试
GET和SET操作,执行 10 万次请求,使用 50 个并发客户端。
- 自定义测试:
- 使用编程语言(如 Python、Java 等)编写自定义测试脚本,模拟实际应用场景,测试 Redis 的 QPS。
-
示例 Python 脚本:
import redis import time r = redis.Redis(host='localhost', port=6379, db=0) start = time.time() for i in range(100000): r.set(f'key{i}', f'value{i}') end = time.time() print(f'QPS: {100000 / (end - start)}')
总结- 9
在理想条件下,单线程 Redis 的 QPS 可以达到 10 万到 20 万,具体取决于硬件配置、操作类型、数据量和网络延迟等因素。通过使用 redis-benchmark 等工具,可以测试 Redis 在不同条件下的 QPS,评估其性能表现。
10.Redis 持久化⽅式有哪些?有什么区别?
Redis 提供了两种主要的持久化方式:RDB(Redis Database)和 AOF(Append-Only File)。这两种持久化方式各有优缺点,可以根据具体需求选择使用。
1. RDB(Redis Database)
RDB工作原理
- RDB 是 Redis 的默认持久化方式,它会在指定的时间间隔内生成数据快照(snapshot),并将快照保存到磁盘上。
- RDB 文件是一个紧凑的二进制文件,包含了某个时间点上 Redis 数据库的所有数据。
RDB配置示例
在 redis.conf 文件中,可以通过以下参数配置 RDB 持久化:
// 配置在指定时间间隔内生成快照
save 900 1 // 900 秒内如果至少有 1 个键发生变化,则生成快照
save 300 10 // 300 秒内如果至少有 10 个键发生变化,则生成快照
save 60 10000 // 60 秒内如果至少有 10000 个键发生变化,则生成快照
// 指定 RDB 文件的保存路径
dir /var/lib/redis
// 指定 RDB 文件的名称
dbfilename dump.rdb
②、当 Redis 服务器通过 SHUTDOWN 命令正常关闭时,如果没有禁用 RDB 持久化,Redis 会自动执行一次 RDB 持久化,以确保数据在下次启动时能够恢复。
③、在 Redis 复制场景中,当一个 Redis 实例被配置为从节点并且与主节点建立连接时,它可能会根据配置接收主节点的 RDB 文件来初始化数据集。这个过程中,主节点会在后台自动触发 RDB 持久化,然后将生成的 RDB 文件发送给从节点。
手动RDB
①、save 命令:会同步地将 Redis 的所有数据保存到磁盘上的一个 RDB 文件中。这个操作会阻塞所有客户端请求直到 RDB 文件被完全写入磁盘。
当 Redis 数据集较大时,使用 SAVE 命令会导致 Redis 服务器停止响应客户端的请求。
不推荐在生产环境中使用,除非数据集非常小,或者可以接受服务暂时的不可用状态。
②、bgsave 命令:会在后台异步地创建 Redis 的数据快照,并将快照保存到磁盘上的 RDB 文件中。这个命令会立即返回,Redis 服务器可以继续处理客户端请求。
在 BGSAVE 命令执行期间,Redis 会继续响应客户端的请求,对服务的可用性影响较小。快照的创建过程是由一个子进程完成的,主进程不会被阻塞。是在生产环境中执行 RDB 持久化的推荐方式。
RDB优点
- 性能高:RDB 文件是紧凑的二进制文件,生成快照的过程对 Redis 的性能影响较小。
- 恢复速度快:RDB 文件包含了某个时间点上 Redis 数据库的所有数据,恢复速度较快。
- 适合备份:RDB 文件是一个完整的快照,适合用于定期备份。
RDB缺点
- 数据丢失风险:由于 RDB 是在指定时间间隔内生成快照,因此在快照之间的数据变更可能会丢失。
- 生成快照开销大:生成快照的过程需要复制整个数据集,数据量较大时可能会占用较多的内存和 CPU 资源。
2. AOF(Append-Only File)
AOF工作原理
- AOF 是通过记录每次写操作的日志来实现持久化的。每次写操作都会被追加到 AOF 文件的末尾。
- Redis 会定期对 AOF 文件进行重写(rewrite),以压缩文件大小。
- AOF 的工作流程操作有四个步骤:命令写入 (append)、文件同步(sync)、文件重写(rewrite)、重启加载(load)
AOF配置示例
在 redis.conf 文件中,可以通过以下参数配置 AOF 持久化:
// 启用 AOF 持久化
appendonly yes
// 指定 AOF 文件的名称
appendfilename "appendonly.aof"
// 配置 AOF 文件的同步策略
// always: 每次写操作后都同步到 AOF 文件,性能较低但数据最安全
// everysec: 每秒同步一次,性能和数据安全性折中
// no: 由操作系统决定何时同步,性能最高但数据安全性最低
appendfsync everysec
// 启用 AOF 文件重写
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
1)当 AOF 持久化功能被启用时(通过在配置文件中设置 appendonly 参数为 yes 来启用),Redis 服务器会将接收到的所有写命令(比如 SET, LPUSH, SADD 等修改数据的命令)追加到 AOF 缓冲区(buffer)的末尾。
2)为了将缓冲区中的命令持久化到磁盘中的 AOF 文件,Redis 提供了几种不同的同步策略:
- always:每次写命令都会同步到 AOF 文件,这提供了最高的数据安全性,但可能因为磁盘 I/O 的延迟而影响性能。
- everysec(默认):每秒同步一次,这是一种折衷方案,提供了较好的性能和数据安全性。如果系统崩溃,最多可能丢失最后一秒的数据。
- no:只会在 AOF 关闭或 Redis 关闭时执行, 或由操作系统内核触发。在这种模式下,如果发生宕机,那么丢失的数据量由操作系统内核的缓存冲洗策略决定。
3)随着操作的不断执行,AOF 文件会不断增长,为了减小 AOF 文件大小,Redis 可以重写 AOF 文件:
- 重写过程不会解析原始的 AOF 文件,而是将当前内存中的数据库状态转换为一系列写命令,然后保存到一个新的 AOF 文件中。
- AOF 重写操作由 BGREWRITEAOF 命令触发,它会创建一个子进程来执行重写操作,因此不会阻塞主进程。
- 重写过程中,新的写命令会继续追加到旧的 AOF 文件中,同时也会被记录到一个缓冲区中。一旦重写完成,Redis 会将这个缓冲区中的命令追加到新的 AOF 文件中,然后切换到新的 AOF 文件上,以确保数据的完整性。
4)当 Redis 服务器启动时,如果配置为使用 AOF 持久化方式,它会读取 AOF 文件中的所有命令并重新执行它们,以恢复数据库的状态。
AOF优点
- 数据安全性高:AOF 记录每次写操作,数据丢失风险较低。
- 可读性好:AOF 文件是一个日志文件,包含了所有写操作的记录,便于分析和调试。
- 灵活性高:可以通过配置不同的同步策略来平衡性能和数据安全性。
AOF缺点
- 文件大小大:AOF 文件会随着写操作的增加而不断增大,需要定期进行重写以压缩文件大小。
- 恢复速度慢:AOF 文件记录了所有写操作,恢复时需要逐条执行这些操作,恢复速度较慢。
- 性能开销大:每次写操作都需要记录到 AOF 文件,性能开销较大。
3. 混合持久化
Redis 4.0 引入了混合持久化(Hybrid Persistence),结合了 RDB 和 AOF 的优点。
工作原理
- 在进行持久化时,Redis 会先生成一个 RDB 快照,然后将最近的写操作追加到 AOF 文件中。
- 这样既可以利用 RDB 快照的高效性,又可以保证 AOF 的数据安全性。
配置示例
在 redis.conf 文件中,可以通过以下参数启用混合持久化:
// 启用混合持久化
aof-use-rdb-preamble yes
总结- 10
- RDB:适合用于定期备份,生成快照的过程对性能影响较小,但在快照之间的数据变更可能会丢失。
- AOF:适合用于需要高数据安全性的场景,记录每次写操作,数据丢失风险较低,但文件大小较大,恢复速度较慢。
- 混合持久化:结合了 RDB 和 AOF 的优点,既可以利用 RDB 快照的高效性,又可以保证 AOF 的数据安全性。
根据具体需求,可以选择合适的持久化方式,或者结合使用 RDB 和 AOF,以实现最佳的性能和数据安全性。
11.RDB 和 AOF 如何选择?
选择 RDB(Redis Database)和 AOF(Append-Only File)持久化方式时,需要根据具体的应用场景和需求来决定。以下是一些选择建议:
选择 RDB 的场景
- 数据备份:
- 如果主要需求是定期备份数据,RDB 是一个很好的选择。RDB 生成的数据快照文件紧凑,适合用于备份和恢复。
- 快速恢复:
- 如果需要快速恢复数据,RDB 是一个不错的选择。RDB 文件包含了某个时间点上 Redis 数据库的所有数据,恢复速度较快。
- 性能优先:
- 如果对性能要求较高,且可以接受一定的数据丢失,RDB 是一个合适的选择。RDB 生成快照的过程对 Redis 的性能影响较小。
选择 AOF 的场景
- 数据安全性:
- 如果数据安全性非常重要,不能接受数据丢失,AOF 是一个更好的选择。AOF 记录每次写操作,数据丢失风险较低。
- 数据可追溯性:
- 如果需要追溯数据的变化历史,AOF 是一个合适的选择。AOF 文件是一个日志文件,包含了所有写操作的记录,便于分析和调试。
- 灵活的同步策略:
- 如果需要灵活地平衡性能和数据安全性,AOF 提供了多种同步策略(always、everysec、no),可以根据具体需求进行配置。
选择混合持久化的场景
- 综合需求:
- 如果既需要 RDB 的高效性,又需要 AOF 的数据安全性,混合持久化是一个理想的选择。混合持久化结合了 RDB 和 AOF 的优点,既可以利用 RDB 快照的高效性,又可以保证 AOF 的数据安全性。
总结- 11
- RDB:适合用于定期备份和快速恢复,性能影响较小,但可能会丢失快照之间的数据。
- AOF:适合需要高数据安全性和数据可追溯性的场景,数据丢失风险较低,但文件较大,恢复速度较慢。
- 混合持久化:结合了 RDB 和 AOF 的优点,适合需要综合考虑性能和数据安全性的场景。
根据具体需求,可以选择合适的持久化方式,或者结合使用 RDB 和 AOF,以实现最佳的性能和数据安全性。
12.Redis 的数据恢复?
当 Redis 中的数据丢失时,可以从 RDB 或者 AOF 中恢复数据。
可以将 RDB 文件或者 AOF 文件复制到 Redis 的数据目录下,然后重启 Redis 服务,Redis 会自动加载数据文件并恢复数据。
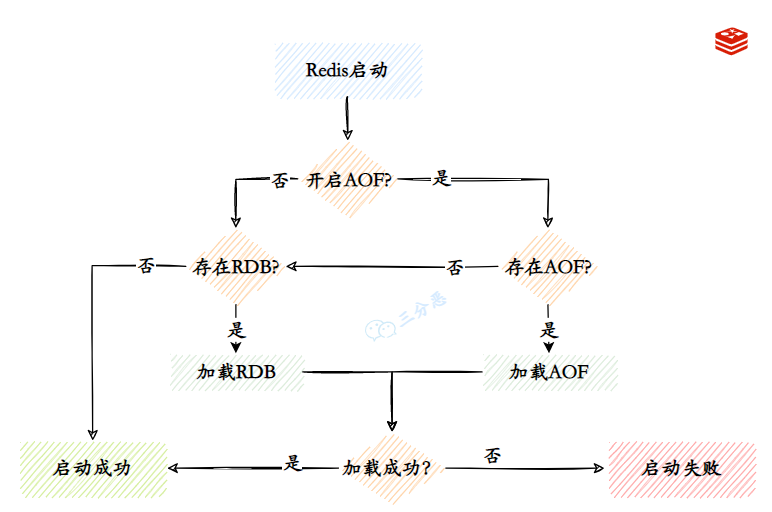
Redis 启动时加载数据的流程:
- AOF 开启且存在 AOF 文件时,优先加载 AOF 文件。
- AOF 关闭或者 AOF 文件不存在时,加载 RDB 文件。
13.Redis主从复制
主从复制(Master-Slave Replication)是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。
前者称为主节点(master),后者称为从节点(slave)。且数据的复制是单向的,只能由主节点到从节点。
在 Redis 主从架构中,主节点负责处理所有的写操作,并将这些操作异步复制到从节点。从节点主要用于读取操作,以分担主节点的压力和提高读性能。
主从复制主要的作用是什么?
①、数据冗余: 主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
②、故障恢复: 如果主节点挂掉了,可以将一个从节点提升为主节点,从而实现故障的快速恢复。
通常会使用 Sentinel 哨兵来实现自动故障转移,当主节点挂掉时,Sentinel 会自动将一个从节点升级为主节点,保证系统的可用性。
// sentinel.conf
port 26379
sentinel monitor mymaster 192.168.1.1 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1
假如是从节点挂掉了,主节点不受影响,但应该尽快修复并重启挂掉的从节点,使其重新加入集群并从主节点同步数据。
③、负载均衡: 在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写 Redis 时连接主节点,读 Redis 时连接从节点),分担服务器负载。尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高 Redis 服务器的并发量。
④、高可用基石: 除了上述作用以外,主从复制还是哨兵和集群能够实施的 基础。
主从复制出现数据不一致怎么办?
Redis 的主从复制是异步进行的,这意味着主节点在执行完写操作后,会立即返回给客户端,而不是等待从节点完成数据同步。
在主节点将数据同步到从节点的过程中,可能会出现网络延迟或中断,从而导致从节点的数据滞后于主节点。
为了解决数据不一致的问题,应该尽量保证主从节点之间的网络连接状况良好,比如说避免在不同机房之间部署主从节点,以减少网络延迟。但可能会带来新的问题,就是整个机房都挂掉的情况。
此外,Redis 本身也提供了一些机制来解决数据不一致的问题,比如说通过 Redis 的 INFO replication 命令监控主从节点的复制进度,及时发现和处理复制延迟。
具体做法是获取主节点的 master_repl_offset 和从节点的 slave_repl_offset,计算两者的差值。如果差值超过预设的阈值,采取措施(如停止从节点的数据读取)以减少读到不一致数据的情况。
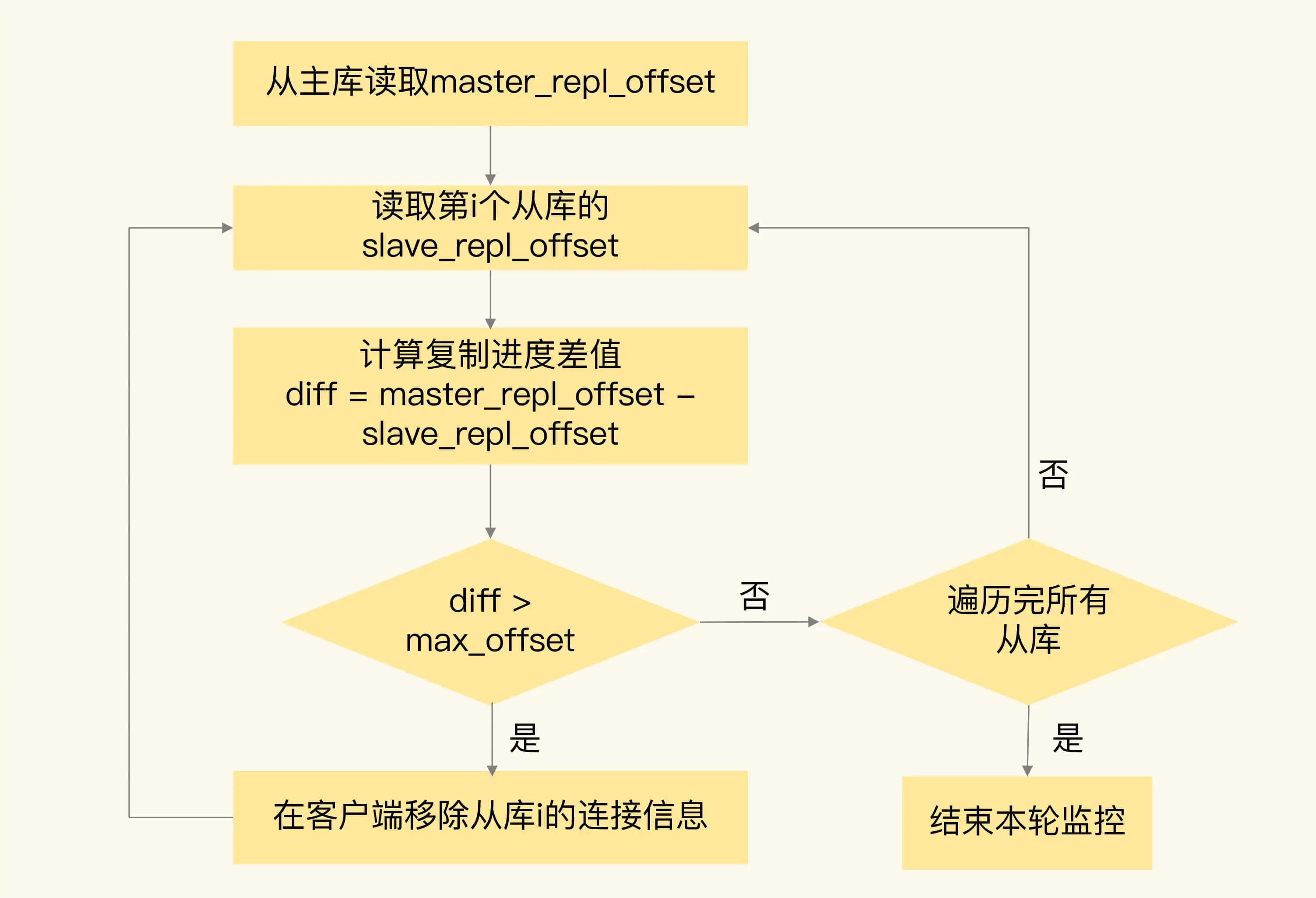
Redis解决单点故障主要靠什么?
主从复制,当主节点发生故障时,可以通过手动或自动方式将某个从节点提升为新的主节点,继续对外提供服务,从而避免单点故障。
Redis 的哨兵机制(Sentinel)可以实现自动化的故障转移,当主节点宕机时,哨兵会自动将一个从节点升级为新的主节点。
另外,集群模式下,当某个节点发生故障时,Redis Cluster 会自动将请求路由到其他节点,并通过从节点进行故障恢复。
14.Redis 主从有几种常见的拓扑结构?
Redis 主从复制有几种常见的拓扑结构,每种结构适用于不同的应用场景和需求。以下是几种常见的 Redis 主从拓扑结构:
1. 单主多从结构
描述
- 单主节点:一个主节点负责处理所有的写操作。
- 多从节点:多个从节点负责处理读操作,从主节点同步数据。
优点
- 读写分离:主节点处理写操作,从节点处理读操作,提高系统的读性能。
- 数据冗余:多个从节点提供数据冗余,提高数据的可靠性。
- 负载均衡:多个从节点分担读负载,提高系统的并发能力。
缺点
- 单点故障:主节点故障会导致写操作不可用,需要手动或自动进行故障转移。
示例
Master
|
---------------
| | |
Slave1 Slave2 Slave3
2. 菊花链结构(链式复制)
描述
- 链式复制:从节点不仅从主节点同步数据,还可以从其他从节点同步数据,形成链式结构。
优点
- 减少主节点压力:从节点可以从其他从节点同步数据,减轻主节点的同步压力。
- 灵活性高:可以根据需要调整链的长度和结构。
缺点
- 数据延迟:链式结构可能会导致数据同步延迟,从节点的数据可能滞后于主节点。
- 复杂性高:链式结构的管理和维护较为复杂。
示例
Master
|
Slave1
|
Slave2
|
Slave3
3. 哨兵模式(Sentinel)
描述
- 哨兵监控:使用哨兵(Sentinel)监控主节点和从节点的状态,自动进行故障转移。
- 自动故障转移:当主节点故障时,哨兵会自动将一个从节点提升为新的主节点。
优点
- 高可用性:哨兵模式提供自动故障转移,保证系统的高可用性。
- 自动化管理:哨兵模式自动监控和管理主从节点,减少人工干预。
缺点
- 配置复杂:哨兵模式的配置和管理较为复杂,需要额外的哨兵节点。
示例
Sentinel
|
Master
|
---------------
| | |
Slave1 Slave2 Slave3
4. 集群模式(Cluster)
描述
- 分片存储:Redis 集群将数据分片存储在多个主节点上,每个主节点负责一部分数据。
- 多主多从:每个主节点都有一个或多个从节点,提供数据冗余和高可用性。
优点
- 水平扩展:集群模式支持水平扩展,可以通过增加节点来扩展存储容量和处理能力。
- 高可用性:集群模式提供自动故障转移和数据冗余,保证系统的高可用性。
缺点
- 复杂性高:集群模式的配置和管理较为复杂,需要额外的集群管理工具。
示例
Master1 ---- Master2 ---- Master3
| | |
--------------- --------------- ---------------
| | | | | | | | |
Slave1 Slave2 Slave3 Slave4 Slave5 Slave6 Slave7 Slave8 Slave9
5.一主一从结构
一主一从结构是最简单的复制拓扑结构,用于主节点出现宕机时从节点提供故障转移支持。
15.Redis 的主从复制原理了解吗?
- 1.保存主节点(master)信息 这一步只是保存主节点信息,保存主节点的 ip 和 port。
- 2.主从建立连接 从节点(slave)发现新的主节点后,会尝试和主节点建立网络连接。
- 3.发送 ping 命令 连接建立成功后从节点发送 ping 请求进行首次通信,主要是检测主从之间网络套接字是否可用、主节点当前是否可接受处理命令。
- 4.权限验证 如果主节点要求密码验证,从节点必须正确的密码才能通过验证。
- 5.同步数据集 主从复制连接正常通信后,主节点会把持有的数据全部发送给从节点。
- 6.命令持续复制 接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。
16.说说主从数据同步的方式?
Redis 在 2.8 及以上版本使用 psync 命令完成主从数据同步,同步过程分为:全量复制和部分复制。
全量复制 一般用于初次复制场景,Redis 早期支持的复制功能只有全量复制,它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。
全量复制的流程如下:
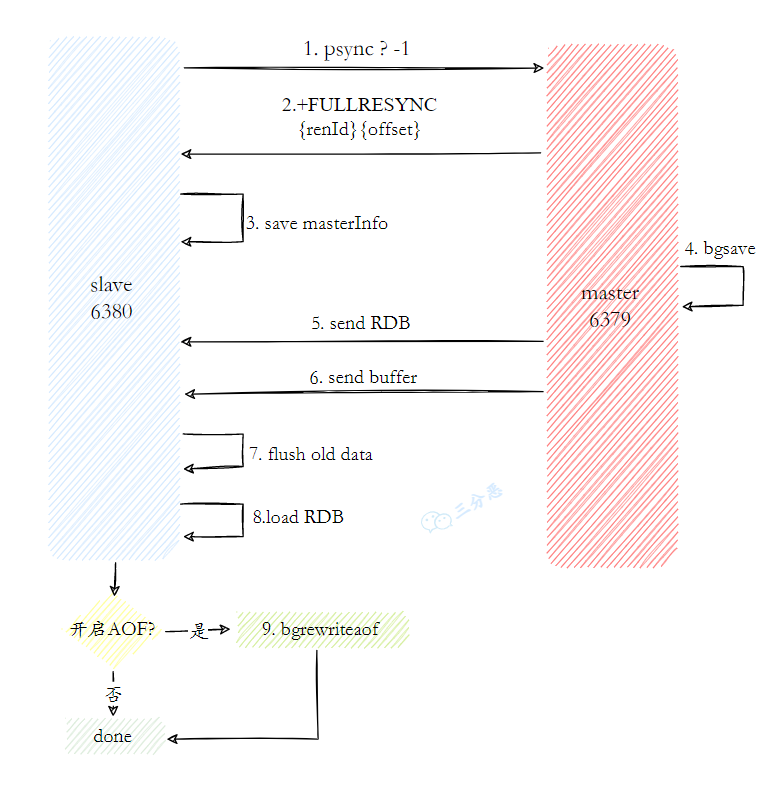
- 1.发送 psync 命令进行数据同步,由于是第一次进行复制,从节点没有复制偏移量和主节点的运行 ID,所以发送 psync-1。
- 2.主节点根据 psync-1 解析出当前为全量复制,回复+FULLRESYNC 响应。
- 3.从节点接收主节点的响应数据保存运行 ID 和偏移量 offset
- 4.主节点执行 bgsave 保存 RDB 文件到本地
- 5.主节点发送 RDB 文件给从节点,从节点把接收的 RDB 文件保存在本地并直接作为从节点的数据文件
- 6.对于从节点开始接收 RDB 快照到接收完成期间,主节点仍然响应读写命令,因此主节点会把这期间写命令数据保存在复制客户端缓冲区内,当从节点加载完 RDB 文件后,主节点再把缓冲区内的数据发送给从节点,保证主从之间数据一致性。
- 7.从节点接收完主节点传送来的全部数据后会清空自身旧数据
- 8.从节点清空数据后开始加载 RDB 文件
- 9.从节点成功加载完 RDB 后,如果当前节点开启了 AOF 持久化功能, 它会立刻做 bgrewriteaof 操作,为了保证全量复制后 AOF 持久化文件立刻可用。
部分复制 部分复制主要是 Redis 针对全量复制的过高开销做出的一种优化措施, 使用 psync{runId}{offset}命令实现。当从节点(slave)正在复制主节点 (master)时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向 主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区内存在这部分数据则直接发送给从节点,这样就可以保持主从节点复制的一致性。
部分复制的流程如下:
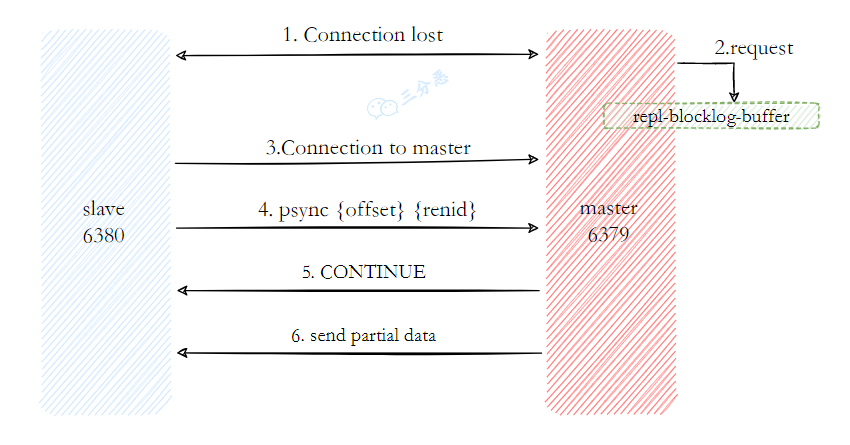
- 1.当主从节点之间网络出现中断时,如果超过 repl-timeout 时间,主节点会认为从节点故障并中断复制连接
- 2.主从连接中断期间主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内部存在的复制积压缓冲区,依然可以保存最近一段时间的写命令数据,默认最大缓存 1MB。
- 3.当主从节点网络恢复后,从节点会再次连上主节点
- 4.当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行 ID。因此会把它们当作 psync 参数发送给主节点,要求进行部分复制操作。
- 5.主节点接到 psync 命令后首先核对参数 runId 是否与自身一致,如果一 致,说明之前复制的是当前主节点;之后根据参数 offset 在自身复制积压缓冲区查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送+CONTINUE 响应,表示可以进行部分复制。
- 6.主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态。
17.主从复制存在哪些问题呢?
主从复制虽好,但也存在一些问题:
- 一旦主节点出现故障,需要手动将一个从节点晋升为主节点,同时需要修改应用方的主节点地址,还需要命令其他从节点去复制新的主节点,整个过程都需要人工干预。
- 主节点的写能力受到单机的限制。
- 主节点的存储能力受到单机的限制。 第一个问题是 Redis 的高可用问题,第二、三个问题属于 Redis 的分布式问题。
18.Redis 哨兵了解吗?
哨兵机制是 Redis 提供的一个高可用性解决方案,用于监控 Redis 的主从复制,以自动完成故障转移和通知管理员。
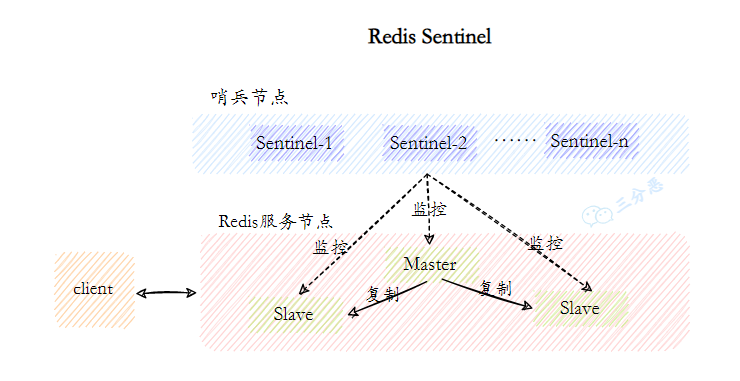
哨兵主要由两部分组成:
- 哨兵节点: 哨兵节点是特殊的 Redis 节点,不存储数据,只对数据节点进行监控。
- 数据节点: 主节点和从节点都是数据节点。
哨兵的主要功能有:
- 监控(Monitoring): 哨兵 Sentinel 会不断检查主节点和从节点是否正常工作。
- 通知(Notification): Sentinel 可以向管理员或其他应用程序发送通知,告知 Redis 实例的状态变化。
- 自动故障转移(Automatic failover): 当 Sentinel 检测到主节点不可用时,会自动将一个从节点提升为新的主节点,并让其他从节点开始复制新的主节点。
- 配置提供者(Configuration provider): Sentinel 客户端可以从 Sentinel 集群获取当前的主节点地址,以实现动态配置。
19.Redis 哨兵实现原理知道吗?
哨兵模式是通过哨兵节点完成对数据节点的监控、下线、故障转移。

定时监控
Redis Sentinel 通过三个定时监控任务完成对各个节点发现和监控:
- 1.每隔 10 秒,每个 Sentinel 节点会向主节点和从节点发送 info 命令获取最新的拓扑结构
- 2.每隔 2 秒,每个 Sentinel 节点会向 Redis 数据节点的sentinel:hello 频道上发送该 Sentinel 节点对于主节点的判断以及当前 Sentinel 节点的信息
- 3.每隔 1 秒,每个 Sentinel 节点会向主节点、从节点、其余 Sentinel 节点发送一条 ping 命令做一次心跳检测,来确认这些节点当前是否可达

主观下线和客观下线
主观下线就是哨兵节点认为某个节点有问题,客观下线就是超过一定数量的哨兵节点认为主节点有问题。
-
主观下线 每个 Sentinel 节点会每隔 1 秒对主节点、从节点、其他 Sentinel 节点发送 ping 命令做心跳检测,当这些节点超过 down-after-milliseconds 没有进行有效回复,Sentinel 节点就会对该节点做失败判定,这个行为叫做主观下线。
-
客观下线 当 Sentinel 主观下线的节点是主节点时,该 Sentinel 节点会通过 sentinel is- master-down-by-addr 命令向其他 Sentinel 节点询问对主节点的判断,当超过
<quorum>个数,Sentinel 节点认为主节点确实有问题,这时该 Sentinel 节点会做出客观下线的决定
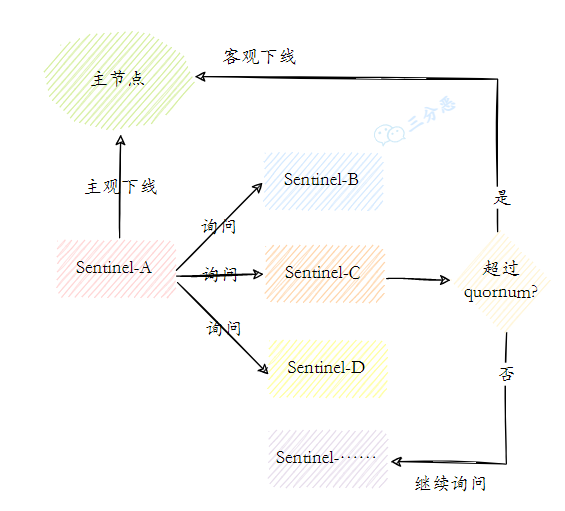
领导者 Sentinel 节点选举
Sentinel 节点之间会做一个领导者选举的工作,选出一个 Sentinel 节点作为领导者进行故障转移的工作。Redis 使用了 Raft 算法实现领导者选举。
Redis 使用 Raft 算法实现领导者选举的:当主节点挂掉后,新的主节点是由剩余的从节点发起选举后晋升的。
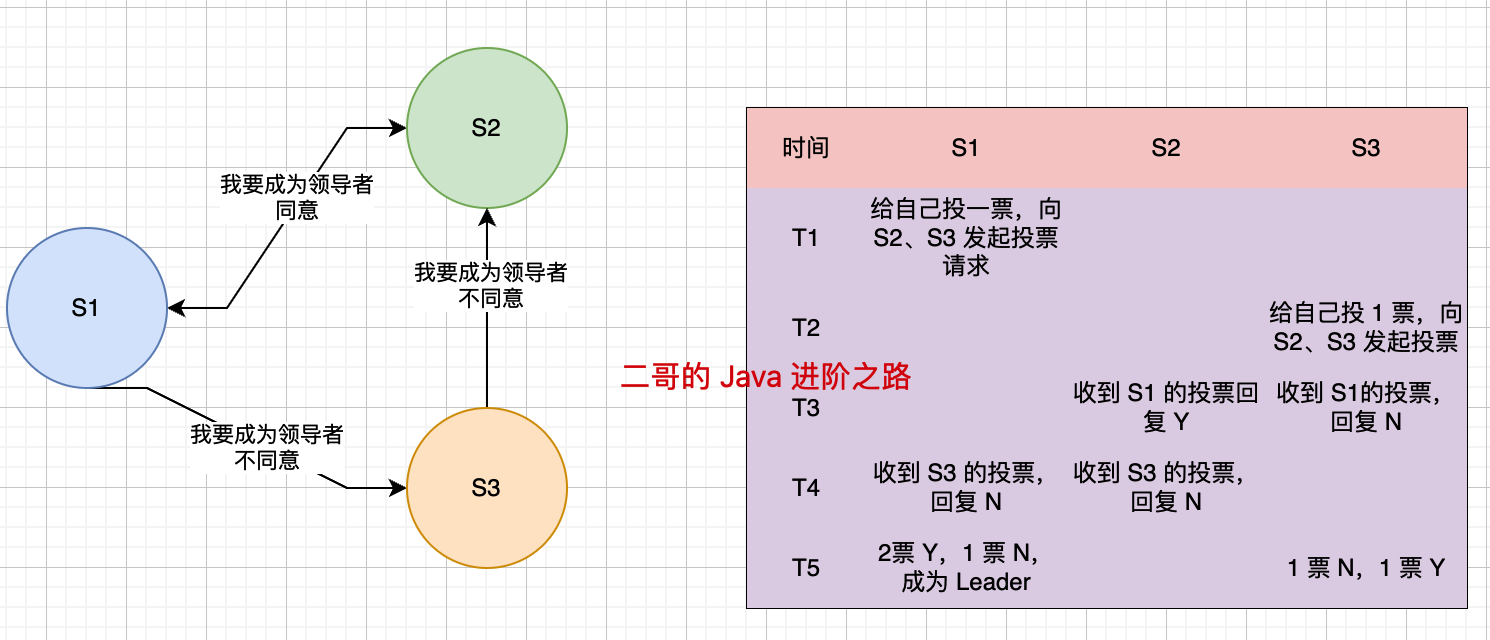
①、每个在线的 Sentinel 节点都有资格成为领导者,当它确认主节点下线时候,会向其他哨兵节点发送命令,表明希望由自己来执行主从切换,并让所有其他哨兵进行投票。
这个投票过程称为“Leader 选举”。候选者会给自己先投 1 票,然后向其他 Sentinel 节点发送投票的请求。
②、收到请求的 Sentinel 节点会进行判断,如果候选者的日志与自己的日志一样新,任期号也小于自己,且之前没有投票过,就会同意投票,回复 Y。否则回复 N。
③、候选者收到投票后会统计支持自己的得票数,如果候选者获得了集群中超过半数节点的投票支持(即多数原则),它将成为新的主节点。
新的主节点在确立后,会向其他从节点发送心跳信号,告诉它们自己已经成为主节点,并将其他节点的状态重置为从节点。
④、如果多个节点同时成为候选者,并且都有可能获得足够的票数,这种情况下可能会出现选票分裂。也就是没有候选者获得超过半数的选票,那么这次选举就会失败,所有候选者都会再次发起选举。
为了防止无限制的选举失败,每个节点都会有一个选举超时时间,且是随机的。
故障转移
领导者选举出的 Sentinel 节点负责故障转移,过程如下:

- 1.在从节点列表中选出一个节点作为新的主节点,这一步是相对复杂一些的一步
- 2.Sentinel 领导者节点会对第一步选出来的从节点执行 slaveof no one 命令让其成为主节点
- 3.Sentinel 领导者节点会向剩余的从节点发送命令,让它们成为新主节点的从节点
- 4.Sentinel 节点集合会将原来的主节点更新为从节点,并保持着对其关注,当其恢复后命令它去复制新的主节点
20.新的主节点是怎样被挑选出来的?
选出新的主节点,大概分为这么几步:
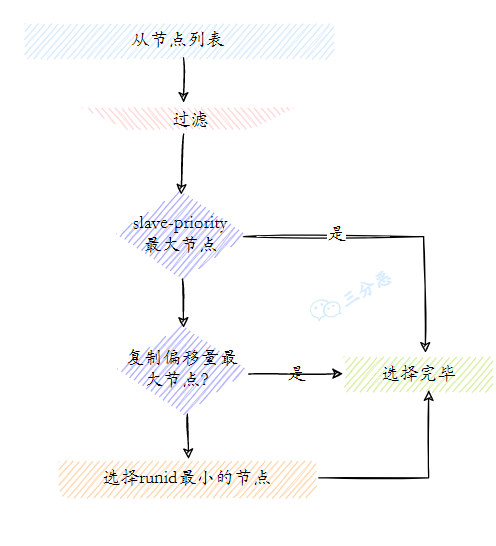
- 1.过滤:“不健康”(主观下线、断线)、5 秒内没有回复过 Sentinel 节 点 ping 响应、与主节点失联超过 down-after-milliseconds*10 秒。
- 2.选择 slave-priority(从节点优先级)最高的从节点列表,如果存在则返回,不存在则继续。
- 3.选择复制偏移量最大的从节点(复制的最完整),如果存在则返 回,不存在则继续。
- 4.选择 runid 最小的从节点。
21.Redis 集群了解吗?
前面说到了主从存在高可用和分布式的问题,哨兵解决了高可用的问题,而集群就是终极方案,一举解决高可用和分布式问题。
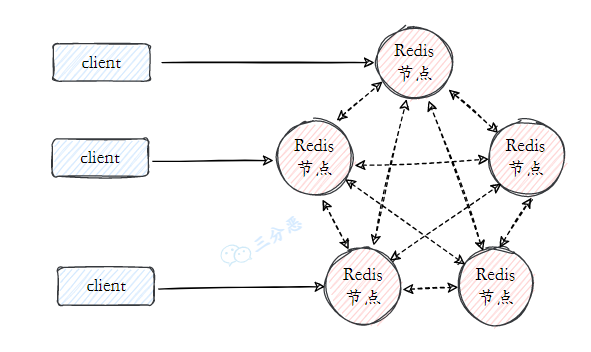
数据分区: 数据分区 (或称数据分片) 是集群最核心的功能。集群将数据分散到多个节点,一方面 突破了 Redis 单机内存大小的限制,存储容量大大增加;另一方面 每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
高可用: 集群支持主从复制和主节点的 自动故障转移 (与哨兵类似),当任一节点发生故障时,集群仍然可以对外提供服务。
21.切片集群了解吗?
切片集群是一种将数据分片存储在多个 Redis 实例上的集群架构,每个 Redis 实例负责存储部分数据。
数据和实例之间如何映射呢?
在 Redis 3.0 之前,官方并没有针对切片集群提供具体的解决方案;但是在 Redis 3.0 之后,官方提供了 Redis Cluster,它是 Redis 官方推荐的分布式解决方案。
在 Redis Cluster 中,数据和实例之间的映射是通过哈希槽(hash slot)来实现的。Redis Cluster 有 16384 个哈希槽,每个键根据其名字的 CRC16 值被映射到这些哈希槽上。然后,这些哈希槽会被均匀地分配到所有的 Redis 实例上。
CRC16 是一种哈希算法,它可以将任意长度的输入数据映射为一个 16 位的哈希值。
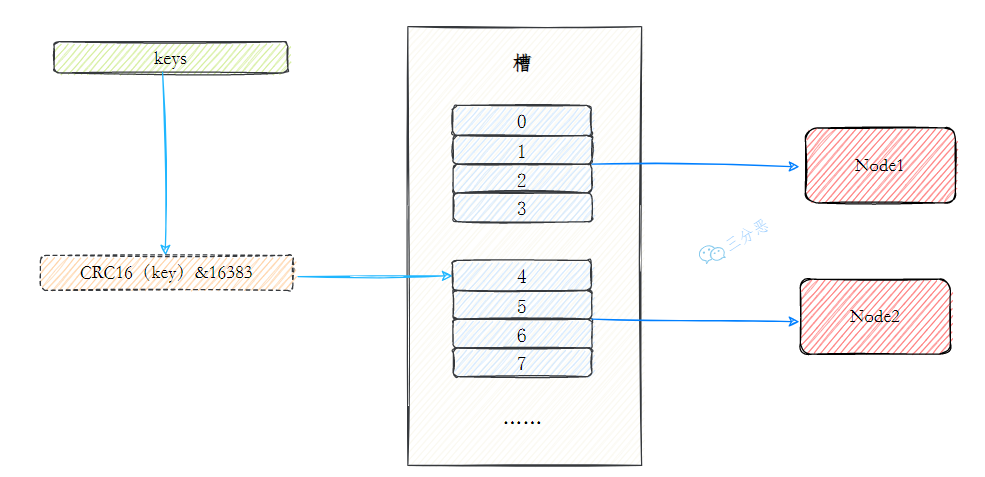
例如,如果我们有 3 个 Redis 实例,那么每个实例可能会负责大约 5461 个哈希槽。
当需要存储或检索一个键值对时,Redis Cluster 会先计算这个键的哈希槽,然后找到负责这个哈希槽的 Redis 实例,最后在这个实例上进行操作。
22.集群中的数据如何分区
在 Redis 集群中,数据分区是通过将数据分散到不同的节点来实现的,常见的数据分区规则有三种:节点取余分区、一致性哈希分区、虚拟槽分区。
节点取余分区
节点取余分区是一种简单的分区策略,其中数据项通过对某个值(通常是键的哈希值)进行取余操作来分配到不同的节点。
类似 HashMap 中的取余操作,数据项的键经过哈希函数计算后,对节点数量取余,然后将数据项分配到余数对应的节点上。
缺点是扩缩容时,大多数数据需要重新分配,因为节点总数的改变会影响取余结果,这可能导致大量数据迁移。
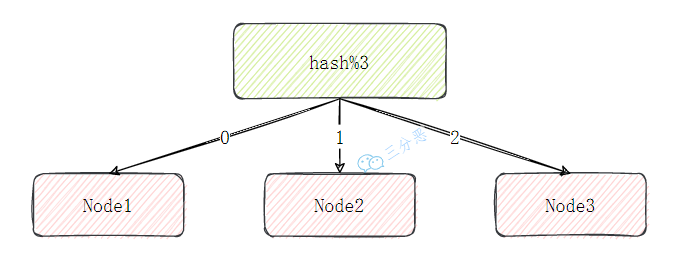
一致性哈希分区
一致性哈希分区的原理是:将哈希值空间组织成一个环,数据项和节点都映射到这个环上。数据项由其哈希值直接映射到环上,然后顺时针分配到遇到的第一个节点。
从而来减少节点变动时数据迁移的量。
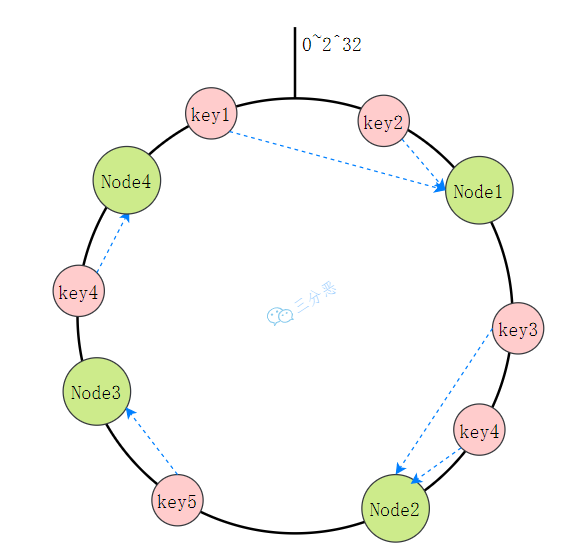
Key 1 和 Key 2 会落入到 Node 1 中,Key 3、Key 4 会落入到 Node 2 中,Key 5 落入到 Node 3 中,Key 6 落入到 Node 4 中。
这种方式相比节点取余最大的好处在于加入和删除节点只影响哈希环中相邻的节点,对其他节点无影响。
但它还是存在问题:
- 节点在圆环上分布不平均,会造成部分缓存节点的压力较大
- 当某个节点故障时,这个节点所要承担的所有访问都会被顺移到另一个节点上,会对后面这个节点造成压力。
虚拟槽分区?
在虚拟槽(也叫哈希槽)分区中,槽位的数量是固定的(例如 Redis Cluster 有 16384 个槽),每个键通过哈希算法(比如 CRC16)映射到这些槽上,每个集群节点负责管理一定范围内的槽。
这种分区可以灵活地将槽(以及槽中的数据)从一个节点迁移到另一个节点,从而实现平滑扩容和缩容;数据分布也更加均匀,Redis Cluster 采用的正是这种分区方式。
假设系统中有 4 个实际节点,假设为其分配了 16 个槽(0-15);
- 槽 0-3 位于节点 node1;
- 槽 4-7 位于节点 node2;
- 槽 8-11 位于节点 node3;
- 槽 12-15 位于节点 node4。
如果此时删除 node2,只需要将槽 4-7 重新分配即可,例如将槽 4-5 分配给 node1,槽 6 分配给 node3,槽 7 分配给 node4,数据在节点上的分布仍然较为均衡。
如果此时增加 node5,也只需要将一部分槽分配给 node5 即可,比如说将槽 3、槽 7、槽 11、槽 15 迁移给 node5,节点上的其他槽位保留。
当然了,这取决于 CRC16(key) % 槽的个数 的具体结果。因为在 Redis Cluster 中,槽的个数刚好是 2 的 14 次方,这和 HashMap 中数组的长度必须是 2 的幂次方有着异曲同工之妙。
它能保证扩容后,大部分数据停留在扩容前的位置,只有少部分数据需要迁移到新的槽上。
23.能说说 Redis 集群的原理吗?
Redis 集群通过数据分区来实现数据的分布式存储,通过自动故障转移实现高可用。
集群创建
数据分区是在集群创建的时候完成的。
设置节点 Redis 集群一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群。每个节点需要开启配置 cluster-enabled yes,让 Redis 运行在集群模式下。
节点握手 节点握手是指一批运行在集群模式下的节点通过 Gossip 协议彼此通信, 达到感知对方的过程。节点握手是集群彼此通信的第一步,由客户端发起命 令:cluster meet{ip}{port}。完成节点握手之后,一个个的 Redis 节点就组成了一个多节点的集群。
分配槽(slot) Redis 集群把所有的数据映射到 16384 个槽中。每个节点对应若干个槽,只有当节点分配了槽,才能响应和这些槽关联的键命令。通过 cluster addslots 命令为节点分配槽。
故障转移
Redis 集群的故障转移和哨兵的故障转移类似,但是 Redis 集群中所有的节点都要承担状态维护的任务。
故障发现 Redis 集群内节点通过 ping/pong 消息实现节点通信,集群中每个节点都会定期向其他节点发送 ping 消息,接收节点回复 pong 消息作为响应。如果在 cluster-node-timeout 时间内通信一直失败,则发送节 点会认为接收节点存在故障,把接收节点标记为主观下线(pfail)状态。
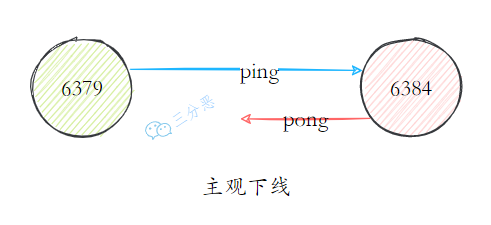
当某个节点判断另一个节点主观下线后,相应的节点状态会跟随消息在集群内传播。通过 Gossip 消息传播,集群内节点不断收集到故障节点的下线报告。当半数以上持有槽的主节点都标记某个节点是主观下线时。触发客观下线流程。
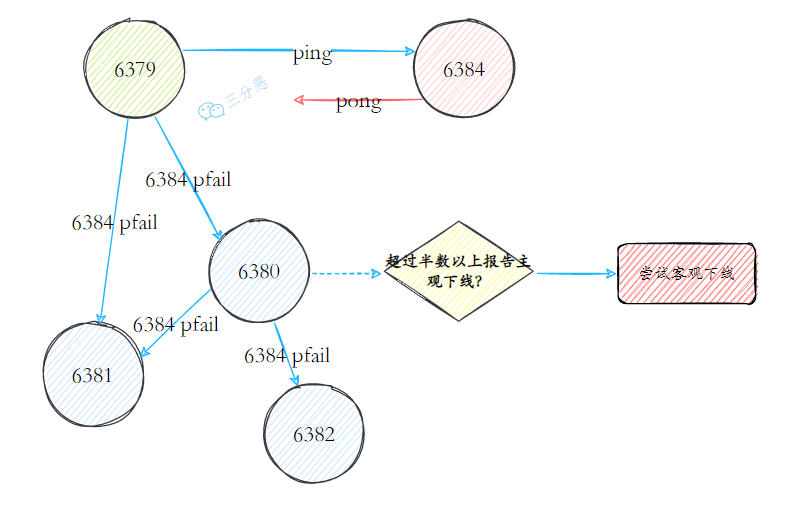
故障恢复
故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它 的从节点中选出一个替换它,从而保证集群的高可用。
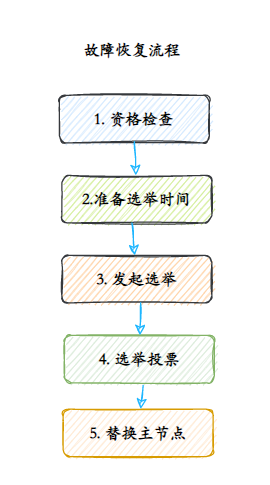
- 1.资格检查 每个从节点都要检查最后与主节点断线时间,判断是否有资格替换故障 的主节点。
- 2.准备选举时间 当从节点符合故障转移资格后,更新触发故障选举的时间,只有到达该 时间后才能执行后续流程。
- 3.发起选举 当从节点定时任务检测到达故障选举时间(failover_auth_time)到达后,发起选举流程。
- 4.选举投票 持有槽的主节点处理故障选举消息。投票过程其实是一个领导者选举的过程,如集群内有 N 个持有槽的主节 点代表有 N 张选票。由于在每个配置纪元内持有槽的主节点只能投票给一个 从节点,因此只能有一个从节点获得 N/2+1 的选票,保证能够找出唯一的从节点。
- 5.替换主节点 当从节点收集到足够的选票之后,触发替换主节点操作。
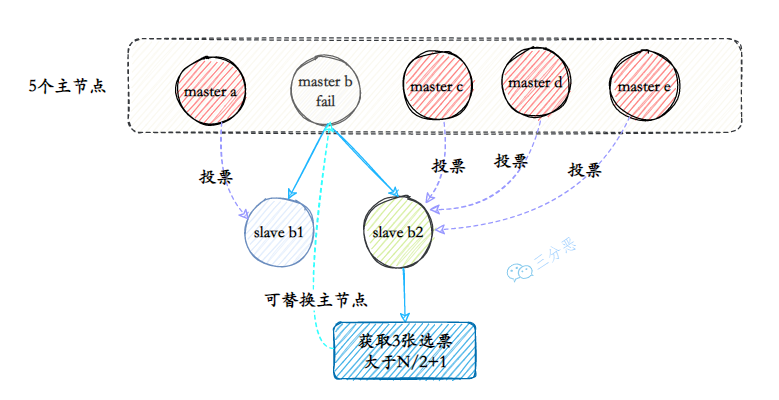
24.部署 Redis 集群至少需要几个物理节点?
在投票选举的环节,故障主节点也算在投票数内,假设集群内节点规模是 3 主 3 从,其中有 2 个主节点部署在一台机器上,当这台机器宕机时,由于从节点无法收集到 3/2+1 个主节点选票将导致故障转移失败。这个问题也适用于故障发现环节。因此部署集群时所有主节点最少需要部署在 3 台物理机上才能避免单点问题。
25.说说集群的伸缩?
Redis 集群提供了灵活的节点扩容和收缩方案,可以在不影响集群对外服务的情况下,为集群添加节点进行扩容也可以下线部分节点进行缩容。
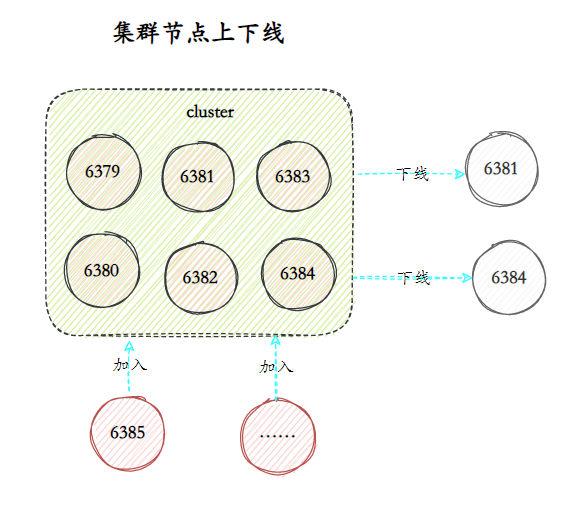
其实,集群扩容和缩容的关键点,就在于槽和节点的对应关系,扩容和缩容就是将一部分槽和数据迁移给新节点。
例如下面一个集群,每个节点对应若干个槽,每个槽对应一定的数据,如果希望加入 1 个节点希望实现集群扩容时,需要通过相关命令把一部分槽和内容迁移给新节点。
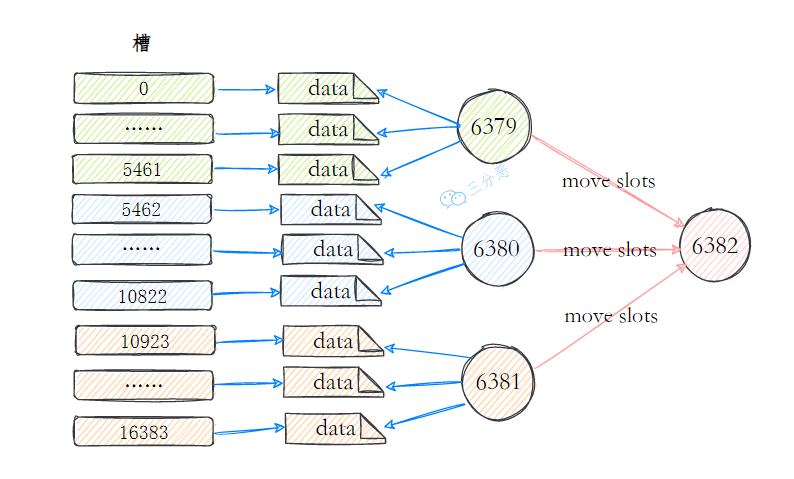
缩容也是类似,先把槽和数据迁移到其它节点,再把对应的节点下线。
26.什么是缓存击穿、缓存穿透、缓存雪崩?
缓存穿透、缓存击穿和缓存雪崩是指在使用 Redis 做为缓存时可能遇到的三种问题。
缓存击穿(Cache Breakdown)
缓存击穿是指某一个或少数几个数据被高频访问,当这些数据在缓存中过期的那一刻,大量请求就会直接到达数据库,导致数据库瞬间压力过大。
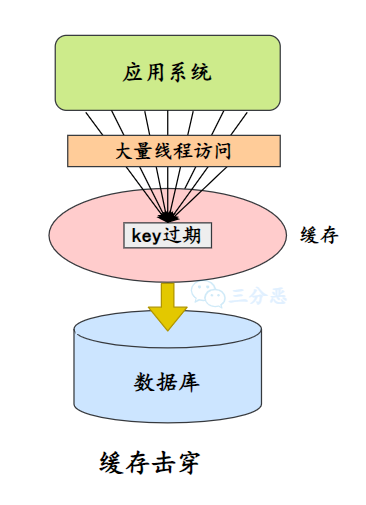
解决方案
①、加锁更新,比如请求查询 A,发现缓存中没有,对 A 这个 key 加锁,同时去数据库查询数据,写⼊缓存,再返回给用户,这样后面的请求就可以从缓存中拿到数据了。
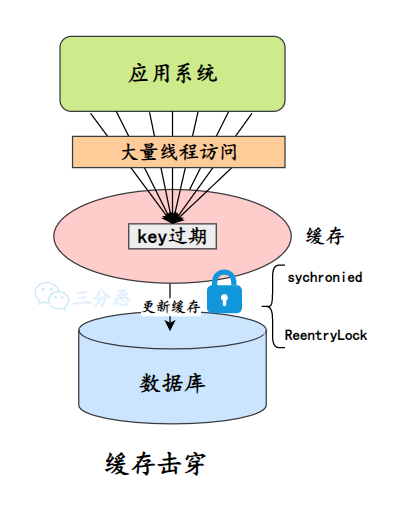
②、将过期时间组合写在 value 中,通过异步的方式不断刷新过期时间,防止此类现象
缓存穿透(Cache Penetration)
缓存穿透是指查询不存在的数据,由于缓存没有命中(因为数据根本就不存在),请求每次都会穿过缓存去查询数据库。如果这种查询非常频繁,就会给数据库造成很大的压力。
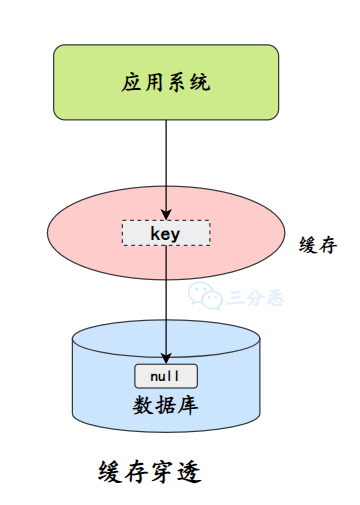
缓存穿透意味着缓存失去了减轻数据压力的意义。缓存穿透可能有两种原因:
1.自身业务代码问题
2.恶意攻击,爬虫造成空命中
解决方案
①、缓存空值/默认值
在数据库无法命中之后,把一个空对象或者默认值保存到缓存,之后再访问这个数据,就会从缓存中获取,这样就保护了数据库。
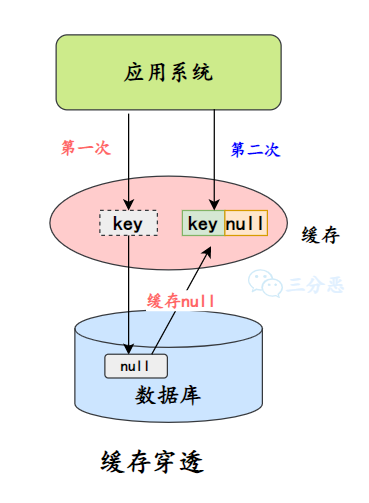
缓存空值有两大问题:
- 1.空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
- 2.缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。 例如过期时间设置为 5 分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致。
这时候可以利用消息队列或者其它异步方式清理缓存中的空对象。
②、布隆过滤器
除了缓存空对象,我们还可以在存储和缓存之前,加一个布隆过滤器,做一层过滤。
布隆过滤器里会保存数据是否存在,如果判断数据不存在,就不会访问存储。
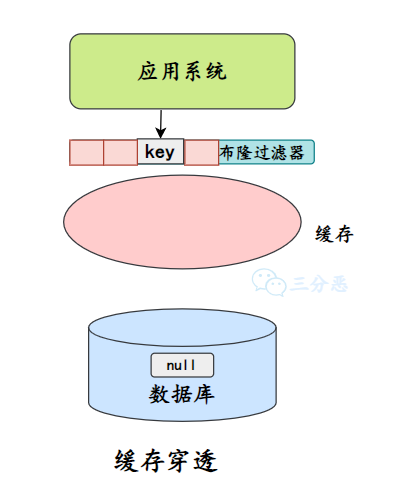
两种解决方案的对比:
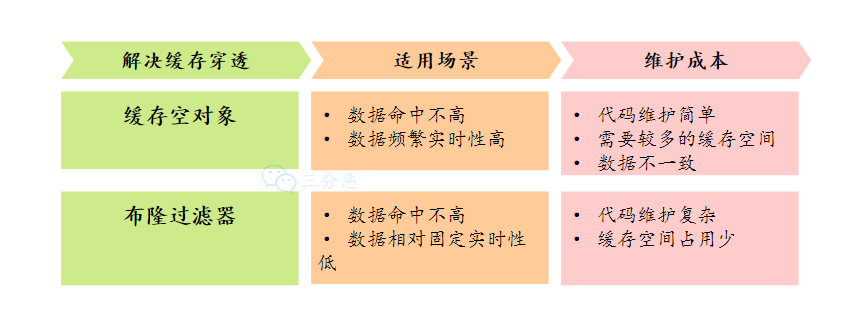
缓存雪崩(Cache Avalanche)
缓存雪崩是指在某个时间段内,大量缓存同时失效,导致大量请求直接访问数据库,造成数据库压力过大甚至崩溃。
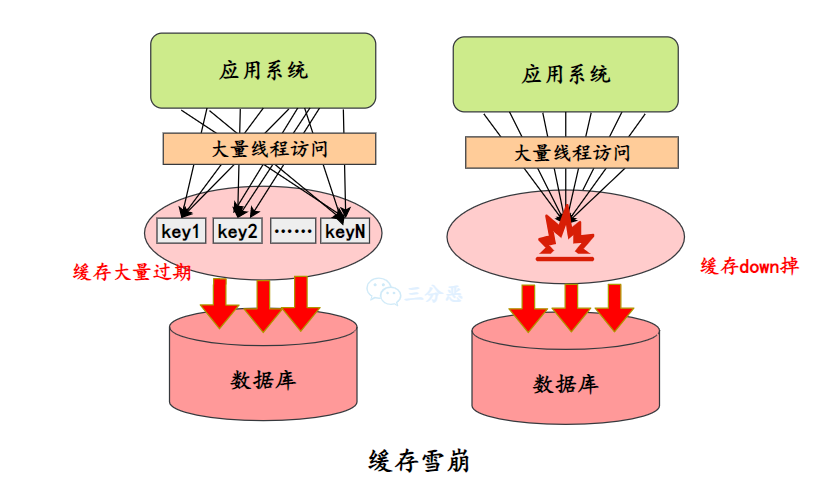
解决方案
1、提高缓存可用性
集群部署:采用分布式缓存而不是单一缓存服务器,可以降低单点故障的风险。即使某个缓存节点发生故障,其他节点仍然可以提供服务,从而避免对数据库的大量直接访问。
可以利用 Redis Cluster,或者第三方集群方案 Codis。
备份缓存:对于关键数据,除了在主缓存中存储,还可以在备用缓存中保存一份。当主缓存不可用时,可以快速切换到备用缓存,确保系统的稳定性和可用性。
2、过期时间
对于缓存数据,设置不同的过期时间,避免大量缓存数据同时过期。可以通过在原有过期时间的基础上添加一个随机值来实现,这样可以分散缓存过期时间,减少同一时间对数据库的访问压力。
3、限流和降级
通过设置合理的系统限流策略,如令牌桶或漏斗算法,来控制访问流量,防止在缓存失效时数据库被打垮。
此外,系统可以实现降级策略,在缓存雪崩或系统压力过大时,暂时关闭一些非核心服务,确保核心服务的正常运行。
27.能说说布隆过滤器吗?
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,用于快速检查一个元素是否存在于一个集合中。
布隆过滤器由一个长度为 m 的位数组和 k 个哈希函数组成。
- 开始时,布隆过滤器的每个位都被设置为 0。
- 当一个元素被添加到过滤器中时,它会被 k 个哈希函数分别计算得到 k 个位置,然后将位数组中对应的位设置为 1。
- 当检查一个元素是否存在于过滤器中时,同样使用 k 个哈希函数计算位置,如果任一位置的位为 0,则该元素肯定不在过滤器中;如果所有位置的位都为 1,则该元素可能在过滤器中。
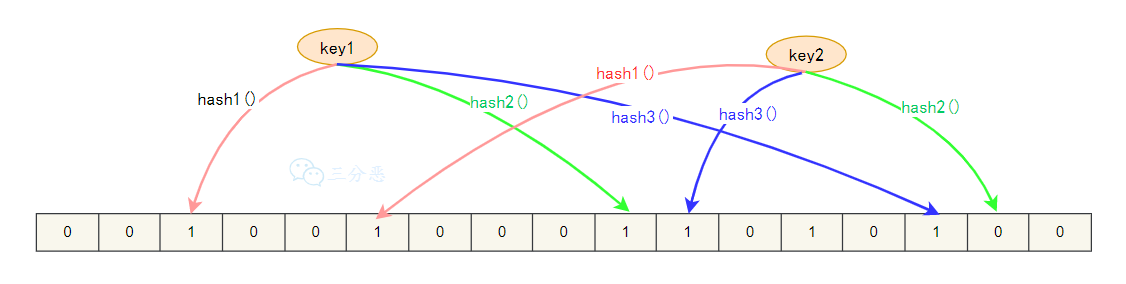
因为布隆过滤器占用的内存空间非常小,所以查询效率也非常高,所以在 Redis 缓存中,使用布隆过滤器可以快速判断请求的数据是否在缓存中。
但是布隆过滤器也有一定的缺点,因为是通过哈希函数计算的,所以存在哈希冲突的问题,可能会导致误判。
28.如何保证缓存和数据库的数据⼀致性?
采用先写 MySQL,再删除 Redis 的方式来保证缓存和数据库的数据一致性。
为什么要删除缓存而不是更新缓存?
因为相对而言,删除缓存的速度比更新缓存的速度要快得多。举个例子:假设商品 product_123 的当前库存是 10,现在有一次购买操作,库存减 1,我们需要更新 Redis 中的库存信息。
product_id = "product_123"
// 假设这是购买操作后的新库存值
new_stock = 9
// 更新Redis中的库存信息
redis.set(product_id, new_stock)
更新操作至少涉及到两个步骤:计算新的库存值和更新 Redis 中的库存值。
假如是直接删除操作,直接就一步到位了:
product_id = "product_123"
// 删除Redis中的库存缓存
redis.del(product_id)
假如是更新缓存,那么可能请求 A 更新完 MySQL 后在更新 Redis 中,请求 B 已经读取到 Redis 中的旧值返回了,又一次导致了缓存和数据库不一致。
为什么要先更新数据库,再删除缓存?
因为更新数据库的速度比删除缓存的速度要慢得多。因为更新 MySQL 是磁盘 IO 操作,而 Redis 是内存操作。内存操作比磁盘 IO 快得多(这是硬件层面的天然差距)。
那假如是先删除缓存,再更新数据库,就会造成这样的情况:
缓存中不存在,数据库又没有完成更新,此时有请求进来读取数据,并写入到缓存,那么在更新完缓存后,缓存中这个 key 就成了一个脏数据。
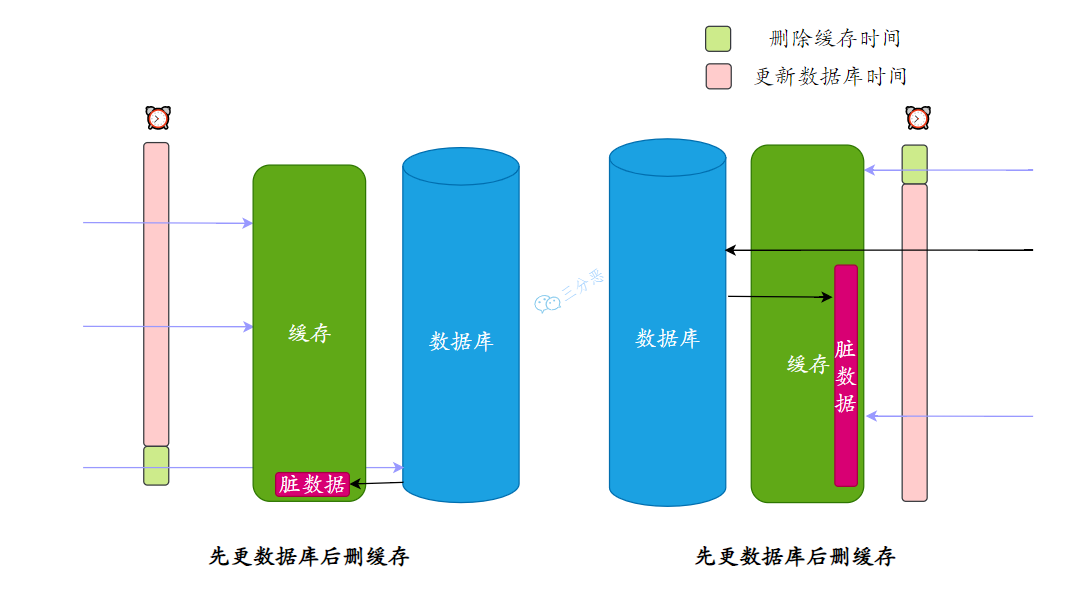
目前最流行的缓存读写策略 Cache Aside Pattern(旁路缓存模式)就是采用的先写数据库,再删缓存的方式。
- 失效:应用程序先从缓存读取数据,如果数据不存在,再从数据库中读取数据,成功后,放入缓存。
- 命中:应用程序从缓存读取数据,如果数据存在,直接返回。
- 更新:先把数据写入数据库,成功后,再让缓存失效。
那假如对一致性要求很高,该怎么办呢?
缓存和数据库数据不一致的原因,常见的有两种:
- 缓存删除失败
- 并发导致写入了脏数据
那通常有四种方案可以解决。
①、引入消息队列保证缓存被删除
使用消息队列(如 Kafka、RabbitMQ)保证数据库更新和缓存更新之间的最终一致性。当数据库更新完成后,将更新事件发送到消息队列。有专门的服务监听这些事件并负责更新或删除缓存。
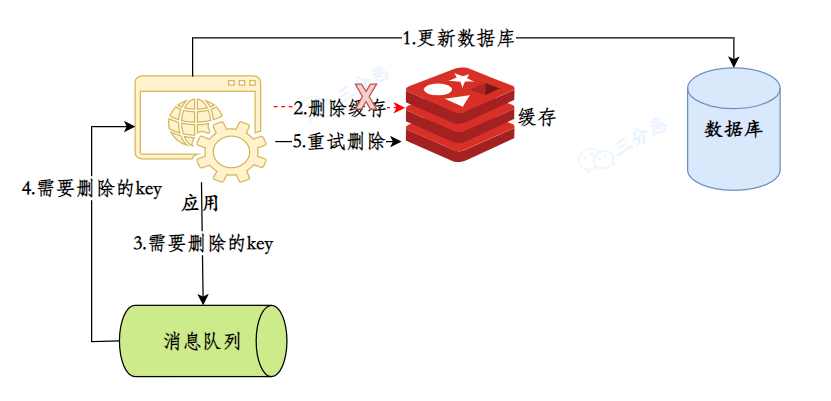
这种方案很不错,缺点是对业务代码有一定的侵入,引入了消息队列。
②、数据库订阅+消息队列保证缓存被删除
可以专门起一个服务(比如 Canal,阿里巴巴 MySQL binlog 增量订阅&消费组件)去监听 MySQL 的 binlog,获取需要操作的数据。
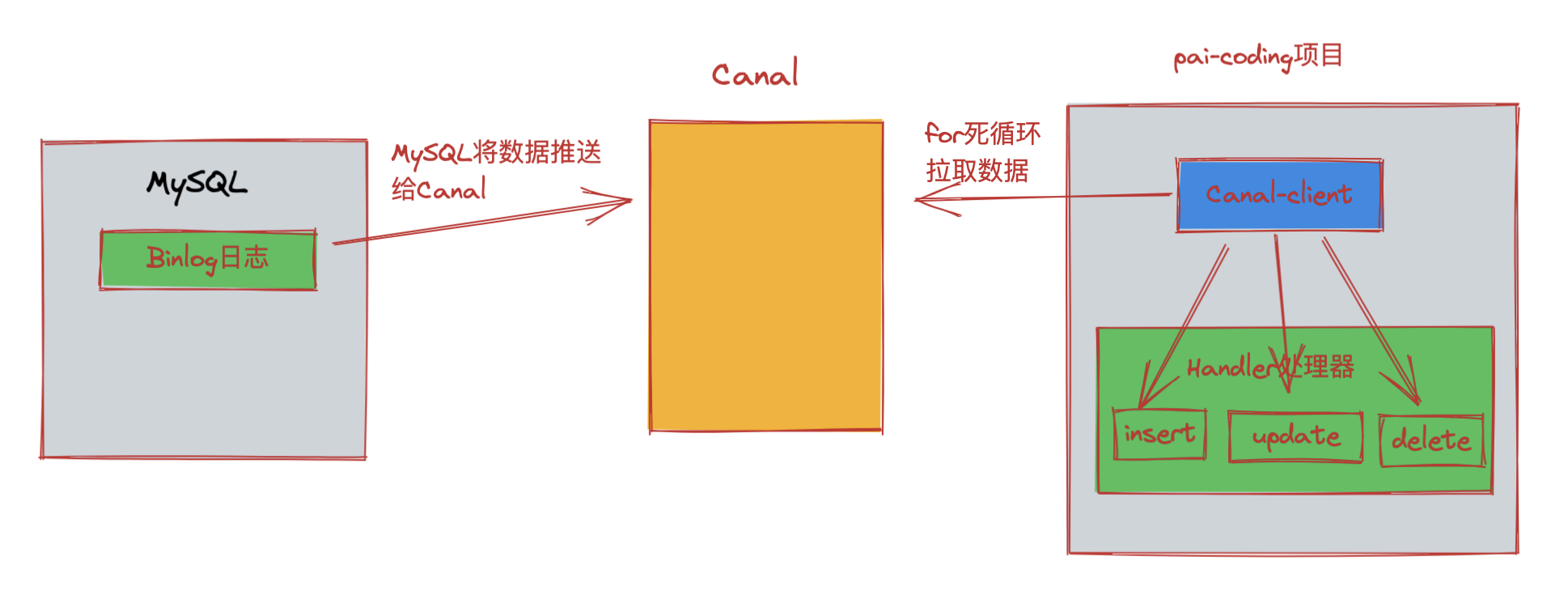
然后用一个公共的服务获取订阅程序传来的信息,进行缓存删除。
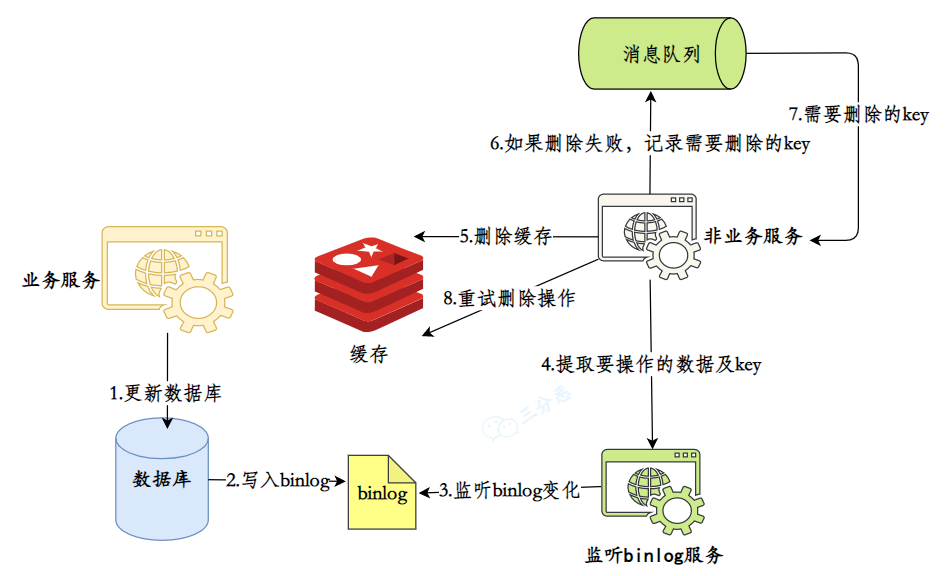
这种方式虽然降低了对业务的侵入,但增加了整个系统的复杂度,适合基建完善的大厂。
③、延时双删防止脏数据
简单说,就是在第一次删除缓存之后,过一段时间之后,再次删除缓存。
主要针对缓存不存在,但写入了脏数据的情况。在先删缓存,再写数据库的更新策略下发生的比较多。
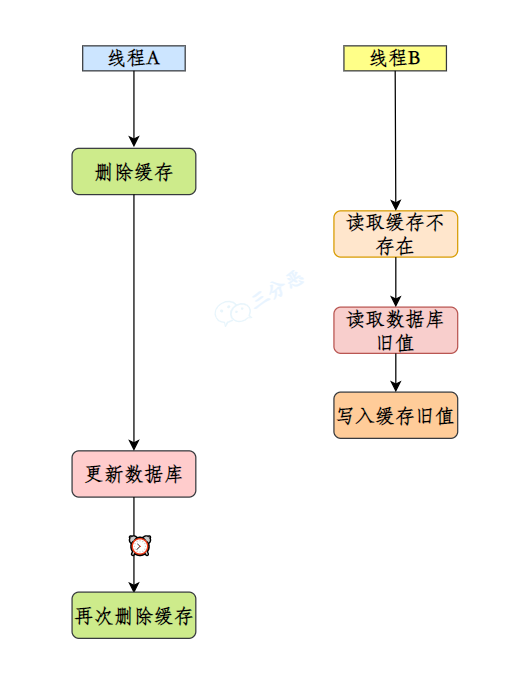
这种方式的延时时间需要仔细考量和测试。
④:设置缓存过期时间兜底
这是一个朴素但有用的兜底策略,给缓存设置一个合理的过期时间,即使发生了缓存和数据库的数据不一致问题,也不会永远不一致下去,缓存过期后,自然就一致了。
29.如何保证本地缓存和分布式缓存的一致?
为了保证本地缓存和 Redis 缓存的一致性,我们可以采用的策略有:
①、设置本地缓存的过期时间,这是最简单也是最直接的方法,当本地缓存过期时,就从 Redis 缓存中去同步。
②、使用 Redis 的 Pub/Sub 机制,当 Redis 缓存发生变化时,发布一个消息,本地缓存订阅这个消息,然后删除对应的本地缓存。
③、Redis 缓存发生变化时,引入消息队列,比如 RocketMQ、RabbitMQ 去更新本地缓存。
如果在项目中多个地方都要使用到二级缓存的逻辑,如何设计这一块?
在设计时,应该清楚地区分何时使用一级缓存和何时使用二级缓存。通常情况下,对于频繁访问但不经常更改的数据,可以放在本地缓存中以提供最快的访问速度。而对于需要共享或者一致性要求较高的数据,应当放在一级缓存中。
本地缓存和 Redis 缓存的区别和效率对比?
Redis 可以部署在多个节点上,支持数据分片,适用于跨服务器的缓存共享。而本地缓存只能在单个服务器上使用。
Redis 还可以持久化数据,支持数据备份和恢复,适用于对数据安全性要求较高的场景。并且支持发布/订阅、事务、Lua 脚本等高级功能。
效率上,Redis 和本地缓存都是存储在内存中,读写速度都非常快。
30.怎么处理热 key?
所谓的热 key,就是指在很短时间内被频繁访问的键。
比如,热门新闻或热门商品,这类 key 通常会有大流量的访问,对存储这类信息的 Redis 来说,是不小的压力。
某天某流量明星突然爆出一个大瓜,微博突然就崩了,这就是热 key 的压力。
再比如说 Redis 是集群部署,热 key 可能会造成整体流量的不均衡(网络带宽、CPU 和内存资源),个别节点出现 OPS 过大的情况,极端情况下热点 key 甚至会超过 Redis 本身能够承受的 OPS。
OPS(Operations Per Second)是 Redis 的一个重要指标,表示 Redis 每秒钟能够处理的命令数。
通常以 Key 被请求的频率来判定,比如:
- QPS 集中在特定的 Key:总的 QPS(每秒查询率)为 10000,其中一个 Key 的 QPS 飙到了 8000。
- 带宽使用率集中在特定的 Key:一个拥有上千成员且总大小为 1M 的哈希 Key,每秒发送大量的 HGETALL 请求。
-
CPU 使用率集中在特定的 Key:一个拥有数万个成员的 ZSET Key,每秒发送大量的 ZRANGE 请求。
- HGETALL 命令用于返回哈希表中,所有的字段和值。
- ZRANGE 命令用于返回有序集中,指定区间内的成员。
捕捉热key
对热 key 的处理,最关键的是对热 key 的监控:
①、客户端
客户端其实是距离 key“最近”的地方,因为 Redis 命令就是从客户端发出的,例如在客户端设置全局字典(key 和调用次数),每次调用 Redis 命令时,使用这个字典进行记录。
②、代理端
像 Twemproxy、Codis 这些基于代理的 Redis 分布式架构,所有客户端的请求都是通过代理端完成的,可以在代理端进行监控。
③、Redis 服务端
使用 monitor 命令统计热点 key 是很多开发和运维人员首先想到的方案,monitor 命令可以监控到 Redis 执行的所有命令。
monitor 命令的使用:redis-cli monitor
还可以通过 bigkeys 参数来分析热 Key。
bigkeys 命令的使用:redis-cli --bigkeys
处理热key
只要监控到了热 key,对热 key 的处理就简单了:
①、把热 key 打散到不同的服务器,降低压⼒。
基本思路就是给热 Key 加上前缀或者后缀,见下例:
// N 为 Redis 实例个数,M 为 N 的 2倍
const M = N * 2
//生成随机数
random = GenRandom(0, M)
//构造备份新 Key
bakHotKey = hotKey + "_" + random
data = redis.GET(bakHotKey)
if data == NULL {
data = redis.GET(hotKey)
if data == NULL {
data = GetFromDB()
// 可以利用原子锁来写入数据保证数据一致性
redis.SET(hotKey, data, expireTime)
redis.SET(bakHotKey, data, expireTime + GenRandom(0, 5))
} else {
redis.SET(bakHotKey, data, expireTime + GenRandom(0, 5))
}
}
②、加⼊二级缓存,当出现热 Key 后,把热 Key 加载到 JVM 中,后续针对这些热 Key 的请求,直接从 JVM 中读取。
这些本地的缓存工具有很多,比如 Caffeine、Guava 等,或者直接使用 HashMap 作为本地缓存都是可以的。
注意,如果对热 Key 进行本地缓存,需要防止本地缓存过大。
31.缓存预热怎么做呢?
缓存预热是指在系统启动时,提前将一些预定义的数据加载到缓存中,以避免在系统运行初期由于缓存未命中(cache miss)导致的性能问题。
通过缓存预热,可以确保系统在上线后能够立即提供高效的服务,减少首次访问时的延迟。
可以使用项目启动时自动加载和定时预热两种方式,比如说每天定时更新站点地图到 Redis 缓存中。
/**
* 采用定时器方案,每天5:15分刷新站点地图,确保数据的一致性
*/
@Scheduled(cron = "0 15 5 * * ?")
public void autoRefreshCache() {
log.info("开始刷新sitemap.xml的url地址,避免出现数据不一致问题!");
refreshSitemap();
log.info("刷新完成!");
}
@Override
public void refreshSitemap() {
initSiteMap();
}
private synchronized void initSiteMap() {
long lastId = 0L;
RedisClient.del(SITE_MAP_CACHE_KEY);
while (true) {
List<SimpleArticleDTO> list = articleDao.getBaseMapper().listArticlesOrderById(lastId, SCAN_SIZE);
// 刷新站点地图信息
Map<String, Long> map = list.stream().collect(Collectors.toMap(s -> String.valueOf(s.getId()), s -> s.getCreateTime().getTime(), (a, b) -> a));
RedisClient.hMSet(SITE_MAP_CACHE_KEY, map);
if (list.size() < SCAN_SIZE) {
break;
}
lastId = list.get(list.size() - 1).getId();
}
}
32.热点 key 重建?问题?解决?
开发的时候一般使用“缓存+过期时间”的策略,既可以加速数据读写,又保证数据的定期更新,这种模式基本能够满足绝大部分需求。
但是有两个问题如果同时出现,可能就会出现比较大的问题:
当前 key 是一个热点 key(例如一个热门的娱乐新闻),并发量非常大。
重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的 SQL、多次 IO、多个依赖等。 在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。
怎么处理呢?
要解决这个问题也不是很复杂,解决问题的要点在于:
- 减少重建缓存的次数。
- 数据尽可能一致。
- 较少的潜在危险。
所以一般采用如下方式:
- 互斥锁(mutex key) 这种方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可。
- 永远不过期 “永远不过期”包含两层意思:
- 从缓存层面来看,确实没有设置过期时间,所以不会出现热点 key 过期后产生的问题,也就是“物理”不过期。
- 从功能层面来看,为每个 value 设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存。
33.知道无底洞问题吗?如何解决?
什么是无底洞问题?
2010 年,Facebook 的 Memcache 节点已经达到了 3000 个,承载着 TB 级别的缓存数据。但开发和运维人员发现了一个问题,为了满足业务要求添加了大量新 Memcache 节点,但是发现性能不但没有好转反而下降了,当时将这 种现象称为缓存的“无底洞”现象。
那么为什么会产生这种现象呢?
通常来说添加节点使得 Memcache 集群 性能应该更强了,但事实并非如此。键值数据库由于通常采用哈希函数将 key 映射到各个节点上,造成 key 的分布与业务无关,但是由于数据量和访问量的持续增长,造成需要添加大量节点做水平扩容,导致键值分布到更多的 节点上,所以无论是 Memcache 还是 Redis 的分布式,批量操作通常需要从不同节点上获取,相比于单机批量操作只涉及一次网络操作,分布式批量操作会涉及多次网络时间。
无底洞问题如何优化呢?
先分析一下无底洞问题:
客户端一次批量操作会涉及多次网络操作,也就意味着批量操作会随着节点的增多,耗时会不断增大。
网络连接数变多,对节点的性能也有一定影响。
常见的优化思路如下:
命令本身的优化,例如优化操作语句等。
减少网络通信次数。
降低接入成本,例如客户端使用长连/连接池、NIO 等。
34.Redis 报内存不足怎么处理?
Redis 内存不足有这么几种处理方式:
- 修改配置文件 redis.conf 的 maxmemory 参数,增加 Redis 可用内存
- 也可以通过命令 set maxmemory 动态设置内存上限
- 修改内存淘汰策略,及时释放内存空间
- 使用 Redis 集群模式,进行横向扩容。
35.Redis 的过期数据回收策略有哪些?
Redis 支持为键设置过期时间,当键的过期时间到达后,Redis 会自动删除这些键。过期回收策略主要有两种:惰性删除和定期删除。
什么是惰性删除?
当某个键被访问时,如果发现它已经过期,Redis 会立即删除该键。这意味着如果一个已过期的键从未被访问,它不会被自动删除,可能会占用额外的内存。
什么是定期删除?
Redis 会定期随机测试一些键,并删除其中已过期的键。这个过程是 Redis 内部自动执行的,旨在减少过期键对内存的占用。可以通过 config get hz 命令查看当前的 hz 值。
结果显示 hz 的值为 “10”。这意味着 Redis 服务器每秒执行其内部定时任务(如过期键的清理)的频率是 10 次。可以通过 CONFIG SET hz 20 进行调整,或者直接通过配置文件中的 hz 设置。
36.Redis 有哪些内存淘汰策略?
Redis 提供了多种内存淘汰策略,用于在内存达到上限时自动删除一些数据,以释放内存。以下是 Redis 支持的内存淘汰策略:
1. noeviction
- 描述:当内存不足时,不再接受写入操作,直接返回错误。
- 适用场景:适用于对数据完整性要求较高的场景,不希望任何数据被淘汰。
2. allkeys-lru
- 描述:在所有键中使用 LRU(最近最少使用)算法进行淘汰。
- 适用场景:适用于希望优先淘汰不常用数据的场景。
3. volatile-lru
- 描述:在设置了过期时间的键中使用 LRU 算法进行淘汰。
- 适用场景:适用于希望优先淘汰不常用且设置了过期时间的数据的场景。
4. allkeys-random
- 描述:在所有键中随机淘汰。
- 适用场景:适用于数据访问模式不确定的场景。
5. volatile-random
- 描述:在设置了过期时间的键中随机淘汰。
- 适用场景:适用于希望优先淘汰设置了过期时间的数据的场景。
6. volatile-ttl
- 描述:在设置了过期时间的键中,优先淘汰存活时间(TTL)最短的键。
- 适用场景:适用于希望优先淘汰即将过期的数据的场景。
7. volatile-lfu
- 描述:在设置了过期时间的键中使用 LFU(最少使用频率)算法进行淘汰。
- 适用场景:适用于希望优先淘汰使用频率较低且设置了过期时间的数据的场景。
8. allkeys-lfu
- 描述:在所有键中使用 LFU 算法进行淘汰。
- 适用场景:适用于希望优先淘汰使用频率较低的数据的场景。
配置示例
在 Redis 配置文件(redis.conf)中设置内存淘汰策略:
maxmemory 2gb
maxmemory-policy allkeys-lru
也可以通过命令动态设置内存淘汰策略:
redis-cli config set maxmemory 2gb
redis-cli config set maxmemory-policy allkeys-lru
示例代码
以下是一个简单的示例代码,展示了如何设置 Redis 的内存淘汰策略:
import redis.clients.jedis.Jedis;
public class RedisEvictionPolicyExample {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost");
// 设置最大内存为 2GB
jedis.configSet("maxmemory", "2gb");
// 设置内存淘汰策略为 allkeys-lru
jedis.configSet("maxmemory-policy", "allkeys-lru");
// 添加一些数据
for (int i = 0; i < 100000; i++) {
jedis.set("key" + i, "value" + i);
}
jedis.close();
}
}
总结
Redis 提供了多种内存淘汰策略,包括 noeviction、allkeys-lru、volatile-lru、allkeys-random、volatile-random、volatile-ttl、volatile-lfu 和 allkeys-lfu。通过合理选择和配置内存淘汰策略,可以有效管理 Redis 的内存使用,确保系统的稳定性和性能。
37.Redis 阻塞?怎么解决?
API 或数据结构使用不合理
通常 Redis 执行命令速度非常快,但是不合理地使用命令,可能会导致执行速度很慢,导致阻塞,对于高并发的场景,应该尽量避免在大对象上执行算法复杂 度超过 O(n)的命令。
对慢查询的处理分为两步:
- 1.发现慢查询: slowlog get{n}命令可以获取最近 的 n 条慢查询命令;
- 2.发现慢查询后,可以从两个方向去优化慢查询:
- 1)修改为低算法复杂度的命令,如 hgetall 改为 hmget 等,禁用 keys、sort 等命令
- 2)调整大对象:缩减大对象数据或把大对象拆分为多个小对象,防止一次命令操作过多的数据。
CPU 饱和的问题
单线程的 Redis 处理命令时只能使用一个 CPU。而 CPU 饱和是指 Redis 单核 CPU 使用率跑到接近 100%。
针对这种情况,处理步骤一般如下:
- 1.判断当前 Redis 并发量是否已经达到极限,可以使用统计命令 redis-cli-h{ip}-p{port}–stat 获取当前 Redis 使用情况
- 2.如果 Redis 的请求几万+,那么大概就是 Redis 的 OPS 已经到了极限,应该做集群化水品扩展来分摊 OPS 压力
- 3.如果只有几百几千,那么就得排查命令和内存的使用
持久化相关的阻塞
对于开启了持久化功能的 Redis 节点,需要排查是否是持久化导致的阻塞。
- 1.fork 阻塞 fork 操作发生在 RDB 和 AOF 重写时,Redis 主线程调用 fork 操作产生共享 内存的子进程,由子进程完成持久化文件重写工作。如果 fork 操作本身耗时过长,必然会导致主线程的阻塞。
- 2.AOF 刷盘阻塞 当我们开启 AOF 持久化功能时,文件刷盘的方式一般采用每秒一次,后台线程每秒对 AOF 文件做 fsync 操作。当硬盘压力过大时,fsync 操作需要等待,直到写入完成。如果主线程发现距离上一次的 fsync 成功超过 2 秒,为了 数据安全性它会阻塞直到后台线程执行 fsync 操作完成。
- 3.HugePage 写操作阻塞 对于开启 Transparent HugePages 的 操作系统,每次写命令引起的复制内存页单位由 4K 变为 2MB,放大了 512 倍,会拖慢写操作的执行时间,导致大量写操作慢查询。
38.大 key 问题了解吗?
大 key 指的是存储了大量数据的键,比如:
- 单个简单的 key 存储的 value 很大,size 超过 10KB
- hash,set,zset,list 中存储过多的元素(以万为单位)
如何找到大 key?
①、bigkeys 参数:使用 bigkeys 命令以遍历的方式分析 Redis 实例中的所有 Key,并返回整体统计信息与每个数据类型中 Top1 的大 Key
bigkeys 命令的使用:redis-cli –bigkeys
②、redis-rdb-tools:redis-rdb-tools 是由 Python 语言编写的用来分析 Redis 中 rdb 快照文件的工具。
如何处理大 key?
①、删除大 key
- 当 Redis 版本大于 4.0 时,可使用 UNLINK 命令安全地删除大 Key,该命令能够以非阻塞的方式,逐步地清理传入的大 Key。
- 当 Redis 版本小于 4.0 时,建议通过 SCAN 命令执行增量迭代扫描 key,然后判断进行删除。
②、压缩和拆分 key
- 当 vaule 是 string 时,比较难拆分,则使用序列化、压缩算法将 key 的大小控制在合理范围内,但是序列化和反序列化都会带来额外的性能消耗。
- 当 value 是 string,压缩之后仍然是大 key 时,则需要进行拆分,将一个大 key 分为不同的部分,记录每个部分的 key,使用 multiget 等操作实现事务读取。
- 当 value 是 list/set 等集合类型时,根据预估的数据规模来进行分片,不同的元素计算后分到不同的片。
39.Redis 常见性能问题和解决方案?
- 1.Master 最好不要做任何持久化工作,包括内存快照和 AOF 日志文件,特别是不要启用内存快照做持久化。
- 2.如果数据比较关键,某个 Slave 开启 AOF 备份数据,策略为每秒同步一次。
- 3.为了主从复制的速度和连接的稳定性,Slave 和 Master 最好在同一个局域网内。
- 4.尽量避免在压力较大的主库上增加从库。
- 5.Master 调用 BGREWRITEAOF 重写 AOF 文件,AOF 在重写的时候会占大量的 CPU 和内存资源,导致服务 load 过高,出现短暂服务暂停现象。
- 6.为了 Master 的稳定性,主从复制不要用图状结构,用单向链表结构更稳定,即主从关为:Master<–Slave1<–Slave2<–Slave3…,这样的结构也方便解决单点故障问题,实现 Slave 对 Master 的替换,也即,如果 Master 挂了,可以立马启用 Slave1 做 Master,其他不变。
40.使用 Redis 如何实现异步队列?
Redis作为异步队列通常有以下几种情况:
使用 list 作为队列,lpush 生产消息,rpop 消费消息
这种方式,消费者死循环 rpop 从队列中消费消息。但是这样,即使队列里没有消息,也会进行 rpop,会导致 Redis CPU 的消耗。
可以通过让消费者休眠的方式的方式来处理,但是这样又会又消息的延迟问题。
使用 list 作为队列,lpush 生产消息,brpop 消费消息
brpop 是 rpop 的阻塞版本,list 为空的时候,它会一直阻塞,直到 list 中有值或者超时。
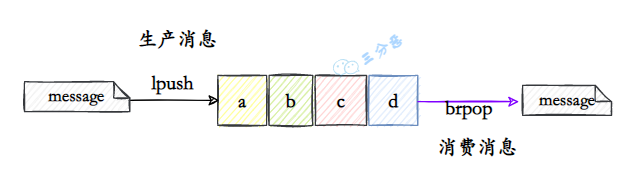
这种方式只能实现一对一的消息队列。
使用 Redis 的 pub/sub 来进行消息的发布/订阅
发布/订阅模式可以 1:N 的消息发布/订阅。发布者将消息发布到指定的频道频道(channel),订阅相应频道的客户端都能收到消息。
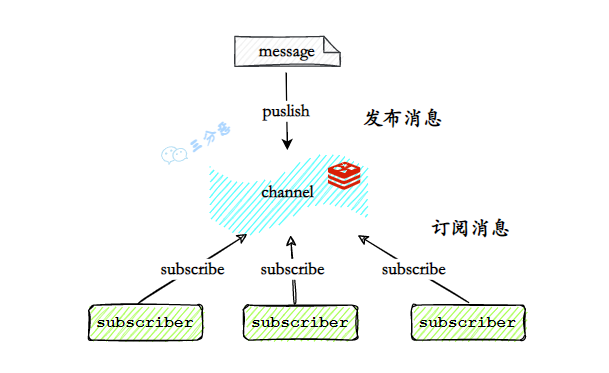
但是这种方式不是可靠的,它不保证订阅者一定能收到消息,也不进行消息的存储。
所以,一般的异步队列的实现还是交给专业的消息队列。
41.Redis 如何实现延时队列?
可以使用 Redis 的 zset(有序集合)来实现延时队列。

第一步,将任务添加到 zset 中,score 为任务的执行时间戳,value 为任务的内容。
ZADD delay_queue 1617024000 task1
第二步,定期(例如每秒)从 zset 中获取 score 小于当前时间戳的任务,然后执行任务。
ZREMRANGEBYSCORE delay_queue -inf 1617024000
第三步,任务执行后,从 zset 中删除任务。
ZREM delay_queue task1
41.Redis 支持事务吗?
Redis 支持简单的事务,可以将多个命令打包,然后一次性的,按照顺序执行。主要通过 multi、exec、discard、watch 等命令来实现:
- multi:标记一个事务块的开始
- exec:执行所有事务块内的命令
- discard:取消事务,放弃执行事务块内的所有命令
- watch:监视一个或多个 key,如果在事务执行之前这个 key 被其他命令所改动,那么事务将被打断
事务的原理
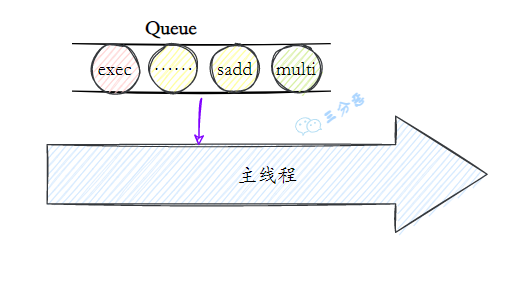
- 使用 MULTI 命令开始一个事务。从这个命令执行之后开始,所有的后续命令都不会立即执行,而是被放入一个队列中。在这个阶段,Redis 只是记录下了这些命令。
- 使用 EXEC 命令触发事务的执行。一旦执行了 EXEC,之前 MULTI 后队列中的所有命令会被原子地(atomic)执行。这里的“原子”意味着这些命令要么全部执行,要么(在出现错误时)全部不执行。
- 如果在执行 EXEC 之前决定不执行事务,可以使用 DISCARD 命令来取消事务。这会清空事务队列并退出事务状态。
- WATCH 命令用于实现乐观锁。WATCH 命令可以监视一个或多个键,如果在执行事务的过程中(即在执行 MULTI 之后,执行 EXEC 之前),被监视的键被其他命令改变了,那么当执行 EXEC 时,事务将被取消,并且返回一个错误。
Redis 事务的注意点有哪些?
Redis 事务是不支持回滚的,不像 MySQL 的事务一样,要么都执行要么都不执行;一旦 EXEC 命令被调用,所有命令都会被执行,即使有些命令可能执行失败。失败的命令不会影响到其他命令的执行。
Redis 事务为什么不支持回滚?
引入事务回滚机制会大大增加 Redis 的复杂性,因为需要跟踪事务中每个命令的状态,并在发生错误时逆向执行命令以恢复原始状态。
Redis 是一个基于内存的数据存储系统,其设计重点是实现高性能。事务回滚需要额外的资源和时间来管理和执行,这与 Redis 的设计目标相违背。因此,Redis 选择不支持事务回滚。
Redis 事务的 ACID 特性如何体现?
ACID 是 MySQL 事务中常见的四个属性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。虽然 Redis 提供了事务的支持,但它在 ACID 属性上的表现与 MySQL 有所不同。
Redis 事务中,所有命令会依次执行,但并不支持部分失败后的自动回滚。因此 Redis 的事务原子性有限。
Redis 在事务层面并不强制保证一致性。用户必须通过正确的命令顺序和逻辑来确保在事务执行后数据的一致性。
Redis 事务在一定程度上提供了隔离性,事务中的命令会按顺序执行,不会被其他客户端的命令插入。
Redis 的持久性依赖于其持久化机制(如 RDB 和 AOF),而不是事务本身。
42.Redis 和 Lua 脚本的使用了解吗?
Redis 的事务功能比较简单,平时的开发中,可以利用 Lua 脚本来增强 Redis 的命令。
Lua 脚本能给开发人员带来这些好处:
- Lua 脚本在 Redis 中是原子执行的,执行过程中间不会插入其他命令。
- Lua 脚本可以帮助开发和运维人员创造出自己定制的命令,并可以将这 些命令常驻在 Redis 内存中,实现复用的效果。
- Lua 脚本可以将多条命令一次性打包,有效地减少网络开销。
-- 尝试获取锁
if redis.call("setnx", KEYS[1], ARGV[1]) == 1 then
redis.call("expire", KEYS[1], ARGV[2])
return 1
else
return 0
end
import redis.clients.jedis.Jedis;
public class RedisDistributedLock {
private static final String LOCK_SCRIPT =
"if redis.call('setnx', KEYS[1], ARGV[1]) == 1 then " +
"redis.call('expire', KEYS[1], ARGV[2]) " +
"return 1 " +
"else " +
"return 0 " +
"end";
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost");
String lockKey = "lock:key";
String lockValue = "unique_value";
int lockExpire = 10; // 锁的过期时间,单位:秒
// 尝试获取锁
Object result = jedis.eval(LOCK_SCRIPT, 1, lockKey, lockValue, String.valueOf(lockExpire));
if ("1".equals(result.toString())) {
System.out.println("Lock acquired");
// 执行需要加锁的操作
// ...
} else {
System.out.println("Failed to acquire lock");
}
jedis.close();
}
}
43.Redis 的管道Pipeline了解吗?
Pipeline 是 Redis 提供的一种优化手段,允许客户端一次性向服务器发送多个命令,而不必等待每个命令的响应,从而减少网络延迟。它的工作原理类似于批量操作,即多个命令一次性打包发送,Redis 服务器依次执行后再将结果一次性返回给客户端。
通常在 Redis 中,每个请求都会遵循以下流程:
- 1.客户端发送命令到服务器。
- 2.服务器执行命令并将结果返回给客户端。
- 3.客户端接收返回结果。
每一个请求和响应之间存在一次网络通信的往返时间(RTT,Round-Trip Time),如果大量请求依次发送,网络延迟会显著增加请求的总执行时间。
有了 Pipeline 后,流程变为:
发送命令1、命令2、命令3…… -> 服务器处理 -> 一次性返回所有结果。
例如,批量写入大量数据或执行一系列查询时,可以将这些操作打包通过 Pipeline 执行。
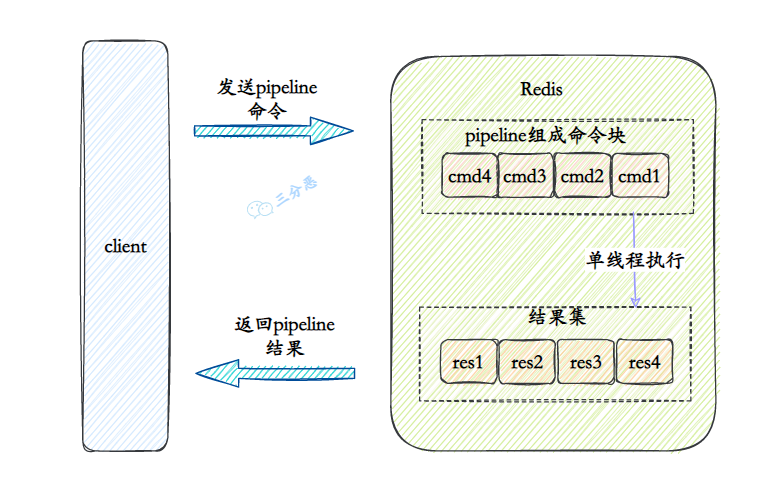
在 Pipeline 模式下,客户端不会在每条命令发送后立即等待 Redis 的响应,而是将多个命令依次写入 TCP 缓冲区,所有命令一起发送到 Redis 服务器。
Redis 服务器接收到批量命令后,依次执行每个命令。
Redis 服务器执行完所有命令后,将每条命令的结果一次性打包通过 TCP 返回给客户端。
客户端一次性接收所有返回结果,并解析每个命令的执行结果。
43.Redis 实现分布式锁了解吗?
分布式锁是一种用于在分布式系统中协调对共享资源的访问的机制。Redis 提供了一种简单而有效的方式来实现分布式锁,通常使用 SETNX 命令和 EXPIRE 命令来实现。
可以使用 Redis 的 SET 命令实现分布式锁。SET 命令支持设置键值对的同时添加过期时间,这样可以防止死锁的发生。
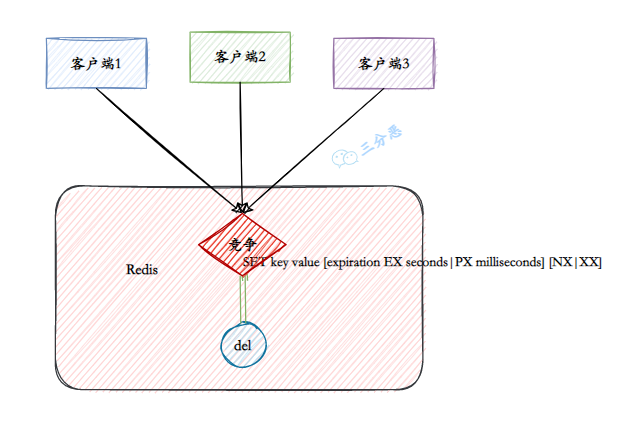
SET key value NX PX 30000
- key 是锁名。
- value 是锁的持有者标识,可以使用 UUID 作为 value。
- NX 只在键不存在时设置。
- PX 30000:设置键的过期时间为 30 秒(防止死锁)。
上面这段命令其实是 setnx 和 expire 组合在一起的原子命令,算是比较完善的一个分布式锁了。
当然,实际的开发中,没人会去自己写分布式锁的命令,因为有专业的轮子——Redisson。(戳链接跳转至悟空聊架构:分布式锁中的王者方案 - Redisson)
Redisson
Redisson 是一个基于 Redis 的 Java 驻内存数据网格(In-Memory Data Grid),提供了一系列 API 用来操作 Redis,其中最常用的功能就是分布式锁。
RLock lock = redisson.getLock("lock");
lock.lock();
try {
// do something
} finally {
lock.unlock();
}
普通锁的实现源码是在 RedissonLock 类中,也是通过 Lua 脚本封装一些 Redis 命令来实现的的,比如说 tryLockInnerAsync 源码:
其中 hincrby 命令用于对哈希表中的字段值执行自增操作,pexpire 命令用于设置键的过期时间。比 SETNX 更优雅。
Redlock
Redlock 是 Redis 作者提出的一种分布式锁实现方案,用于确保在分布式环境下安全可靠地获取锁。它的目标是在分布式系统中提供一种高可用、高容错的锁机制,确保在同一时刻,只有一个客户端能够成功获得锁,从而实现对共享资源的互斥访问。
Redisson 中的 RedLock 是基于 RedissonMultiLock(联锁)实现的。
实现原理:
RedissonMultiLock 的 tryLock 方法会在指定的 Redis 实例上逐一尝试获取锁。
在获取锁的过程中,Redlock 会根据配置的 waitTime(最大等待时间)和 leaseTime(锁的持有时间)进行灵活控制。比如,如果获取锁的时间小于锁的有效期(通过TTL命令获取锁的剩余时间),则表示获取锁成功。
通常,至少需要多数(如 5 个实例中的 3 个)实例成功获取锁,才能认为整个锁获取成功。
如果指定了锁的持有时间(leaseTime),在成功获取锁后,Redlock 会为锁进行续期,以防止锁在操作完成之前意外失效。
红锁能不能保证百分百上锁?
Redlock 不能保证百分百上锁,因为在分布式系统中,网络延迟、时钟漂移、Redis 实例宕机等因素都可能导致锁的获取失败。
44.Redis 底层数据结构?
Redis 的底层数据结构有动态字符串(sds)、链表(list)、字典(ht)、跳跃表(skiplist)、整数集合(intset)、压缩列表(ziplist) 等。
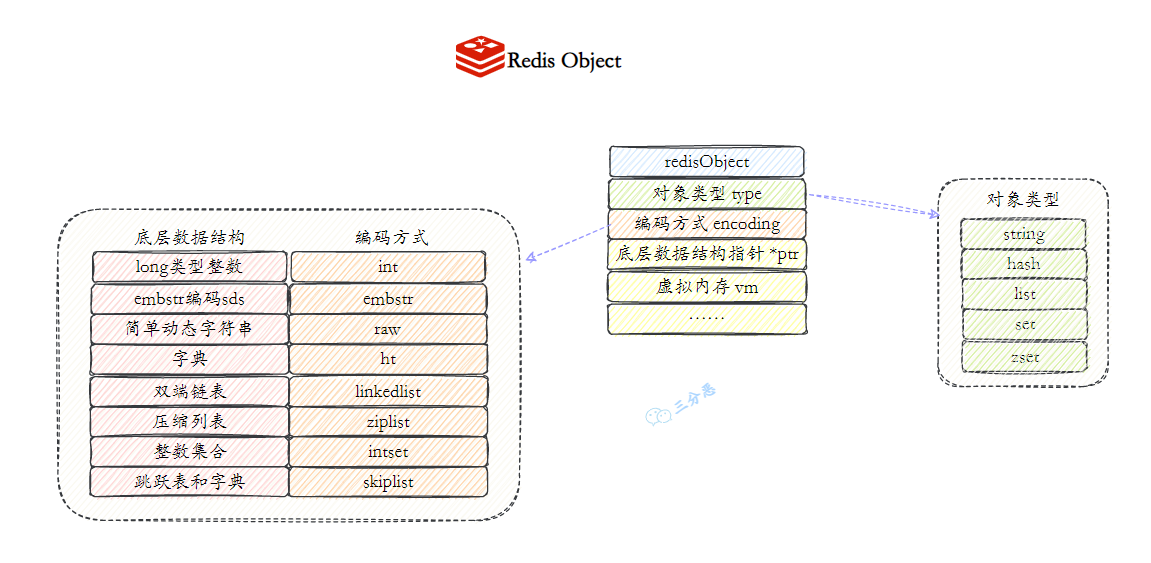
比如说 string 是通过 SDS 实现的,list 是通过链表实现的,hash 是通过字典实现的,set 是通过字典实现的,zset 是通过跳跃表实现的。
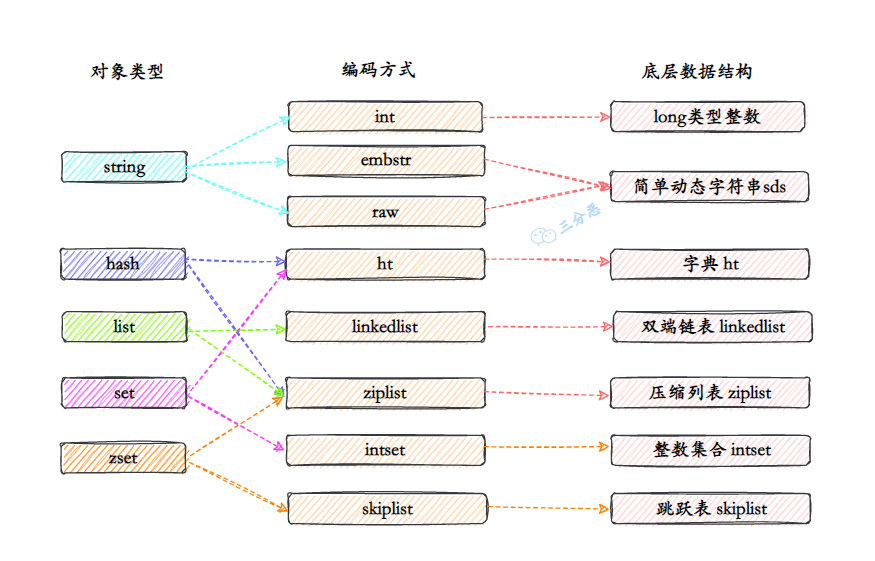
动态字符串 SDS
Redis 是通过 C 语言实现的,但 Redis 并没有直接使用 C 语言的字符串,而是自己实现了一种叫做动态字符串 SDS 的类型。
struct sdshdr {
int len; // buf 中已使用的长度
int free; // buf 中未使用的长度
char buf[]; // 数据空间
};
因为C语言的字符串不记录自身的长度信息,当需要获取字符串长度时,需要遍历整个字符串,时间复杂度为O(N)。
而 SDS 保存了长度信息,这样就将获取字符串长度的时间由 O(N) 降低到了 O(1)。
链表 linkedlist
Redis 的链表是⼀个双向无环链表结构,和 Java 中的 LinkedList 类似。
链表的节点由⼀个叫做 listNode 的结构来表示,每个节点都有指向其前置节点和后置节点的指针,同时头节点的前置和尾节点的后置均指向 null。
字典 dict
⽤于保存键值对的抽象数据结构。Redis 使用 hash 表作为底层实现,一个哈希表里可以有多个哈希表节点,而每个哈希表节点就保存了字典里中的一个键值对。
每个字典带有两个 hash 表,供平时使用和 rehash 时使用,hash 表使用链地址法来解决键冲突,被分配到同⼀个索引位置的多个键值对会形成⼀个单向链表,在对 hash 表进行扩容或者缩容的时候,为了服务的可用性,rehash 的过程不是⼀次性完成的,⽽是渐进式的。
跳跃表 skiplist
跳跃表(也称跳表)是有序集合 Zset 的底层实现之⼀。在 Redis 7.0 之前,如果有序集合的元素个数小于 128 个,并且每个元素的值小于 64 字节时,Redis 会使用压缩列表作为 Zset 的底层实现,否则会使用跳表;在 Redis 7.0 之后,压缩列表已经废弃,交由 listpack 来替代。
跳表由 zskiplist 和 zskiplistNode 组成,zskiplist ⽤于保存跳表的基本信息(表头、表尾、长度、层高等)。
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
zskiplistNode ⽤于表示跳表节点,每个跳表节点的层高是不固定的,每个节点都有⼀个指向保存了当前节点的分值和成员对象的指针。
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
整数集合 intset
⽤于保存整数值的集合抽象数据结构,不会出现重复元素,底层实现为数组。
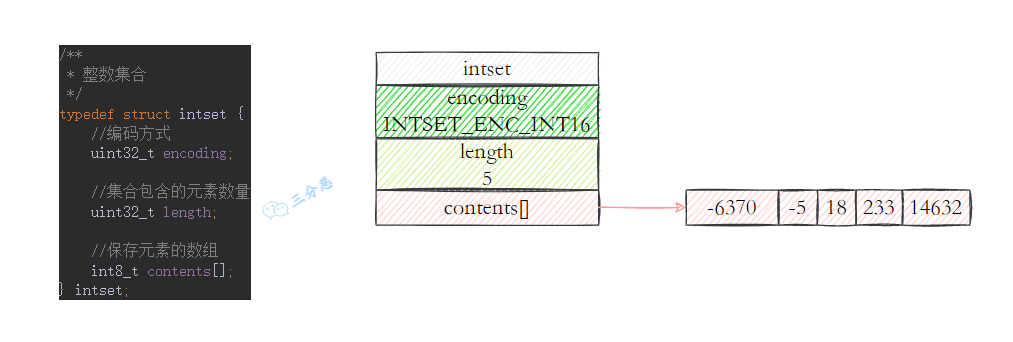
压缩列表 ziplist
压缩列表是为节约内存而开发的顺序性数据结构,它可以包含任意多个节点,每个节点可以保存⼀个字节数组或者整数值。

紧凑列表 listpack
listpack 是 Redis 用来替代压缩列表(ziplist)的一种内存更加紧凑的数据结构。
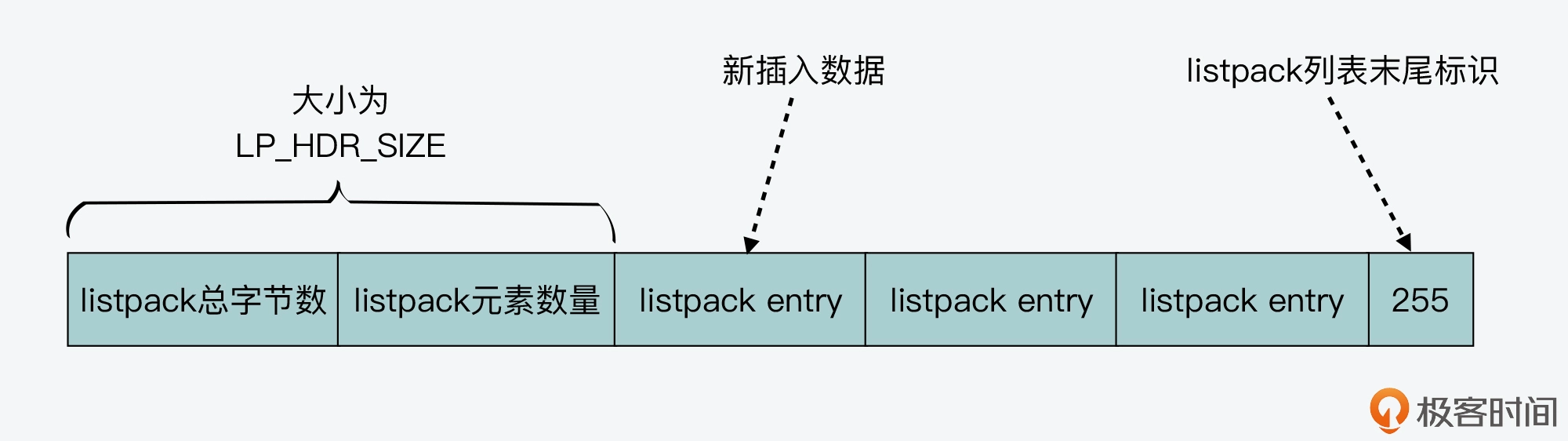
为了避免 ziplist 引起的连锁更新问题,listpack 中的元素不再像 ziplist 那样,保存其前一个元素的长度,而是保存当前元素的编码类型、数据,以及编码类型和数据的长度。
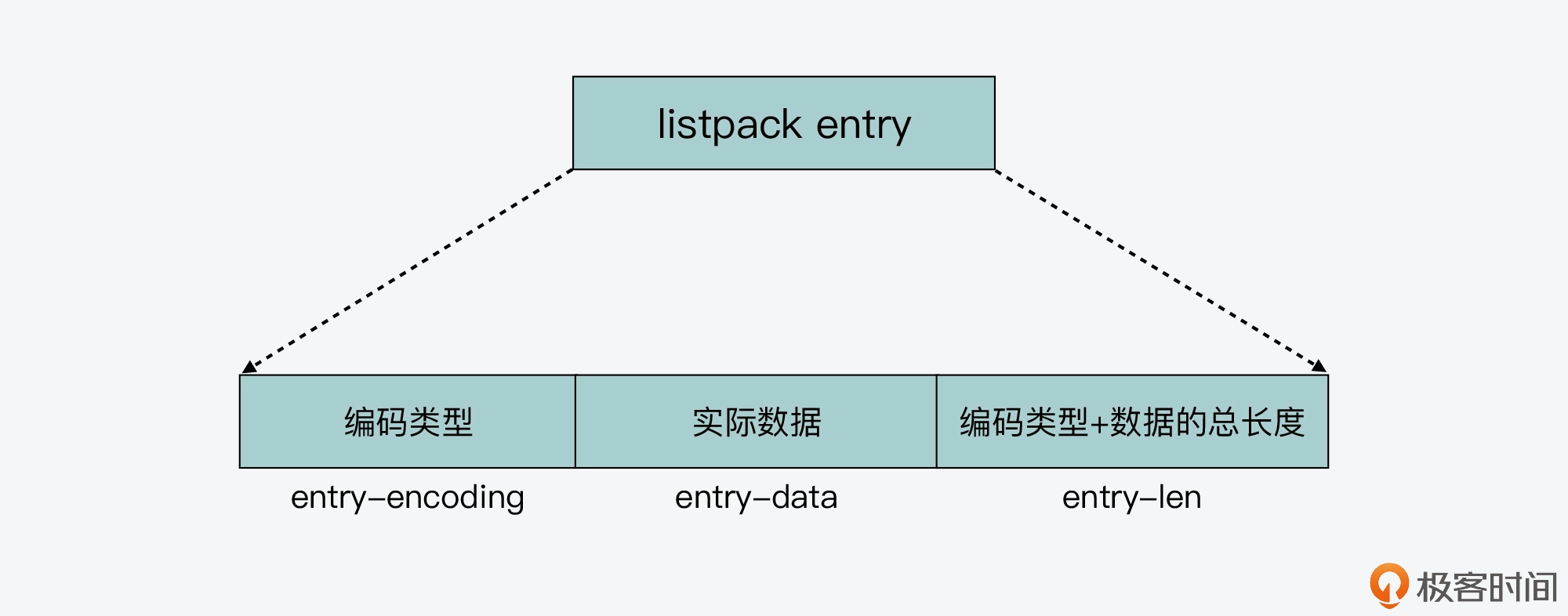
listpack 每个元素项不再保存上一个元素的长度,而是优化元素内字段的顺序,来保证既可以从前也可以向后遍历。
但因为 List/Hash/Set/ZSet 都严重依赖 ziplist,所以这个替换之路很漫长。
45.Redis 的 SDS 和 C 中字符串相比有什么优势?
C 语言使用了一个长度为 N+1 的字符数组来表示长度为 N 的字符串,并且字符数组最后一个元素总是 \0,这种简单的字符串表示方式 不符合 Redis 对字符串在安全性、效率以及功能方面的要求。
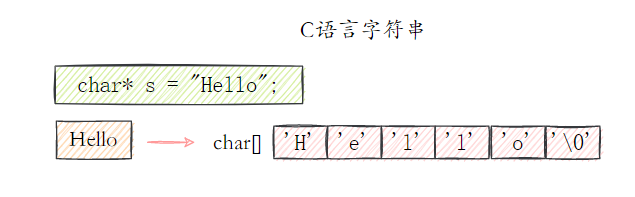
C 语言的字符串可能有什么问题?
- 获取字符串长度复杂度高 :因为 C 不保存数组的长度,每次都需要遍历一遍整个数组,时间复杂度为 O(n);
- 不能杜绝缓冲区溢出/内存泄漏的问题 : C 字符串不记录自身长度带来的另外一个问题是容易造成缓存区溢出(buffer overflow)
- C 字符串只能保存文本数据 → 因为 C 语言中的字符串必须符合某种编码(比如 ASCII),例如中间出现的 ‘\0’ 可能会被判定为提前结束的字符串而识别不了;
Redis 如何解决?优势?
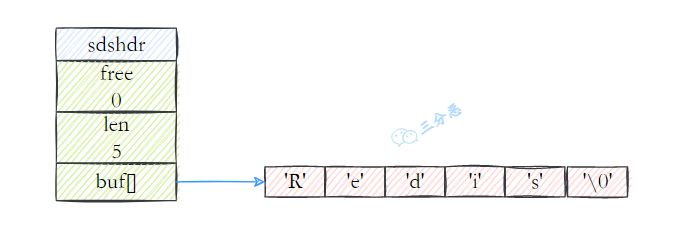
- 多增加 len 表示当前字符串的长度:这样就可以直接获取长度了,复杂度 O(1);
- 自动扩展空间:当 SDS 需要对字符串进行修改时,首先借助于 len 和 alloc 检查空间是否满足修改所需的要求,如果空间不够的话,SDS 会自动扩展空间,避免了像 C 字符串操作中的溢出情况;
- 有效降低内存分配次数:C 字符串在涉及增加或者清除操作时会改变底层数组的大小造成重新分配,SDS 使用了 空间预分配 和 惰性空间释放 机制,简单理解就是每次在扩展时是成倍的多分配的,在缩容是也是先留着并不正式归还给 OS;
- 二进制安全:C 语言字符串只能保存 ascii 码,对于图片、音频等信息无法保存,SDS 是二进制安全的,写入什么读取就是什么,不做任何过滤和限制;
46.字典是如何实现的?Rehash 了解吗?
字典是 Redis 服务器中出现最为频繁的复合型数据结构。除了 hash 结构的数据会用到字典外,整个 Redis 数据库的所有 key 和 value 也组成了一个 全局字典,还有带过期时间的 key 也是一个字典。(存储在 RedisDb 数据结构中)
字典结构是什么样的呢?
Redis 中的字典相当于 Java 中的 HashMap,内部实现也差不多类似,采用哈希与运算计算下标位置;通过 “数组 + 链表” 的链地址法 来解决哈希冲突,同时这样的结构也吸收了两种不同数据结构的优点。
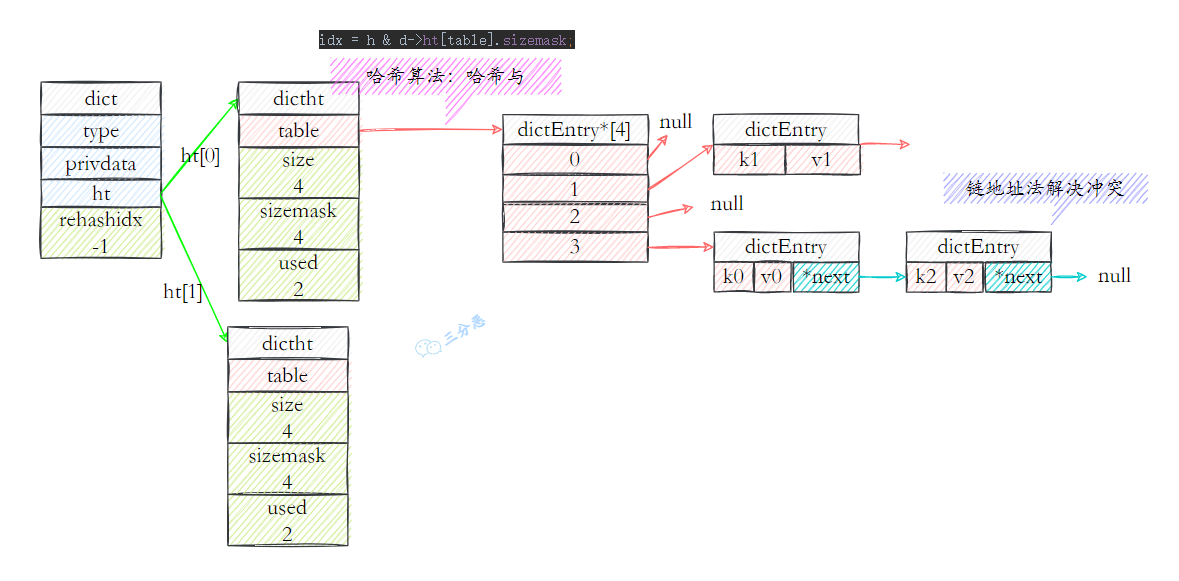
字典是怎么扩容的?
字典结构内部包含 两个 hashtable,通常情况下只有一个哈希表 ht[0] 有值,在扩容的时候,把 ht[0]里的值 rehash 到 ht[1],然后进行 渐进式 rehash ——所谓渐进式 rehash,指的是这个 rehash 的动作并不是一次性、集中式地完成的,而是分多次、渐进式地完成的。
待搬迁结束后,h[1]就取代 h[0]存储字典的元素。
47.跳表是如何实现的?原理?
跳表(skiplist)是一种有序的数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。
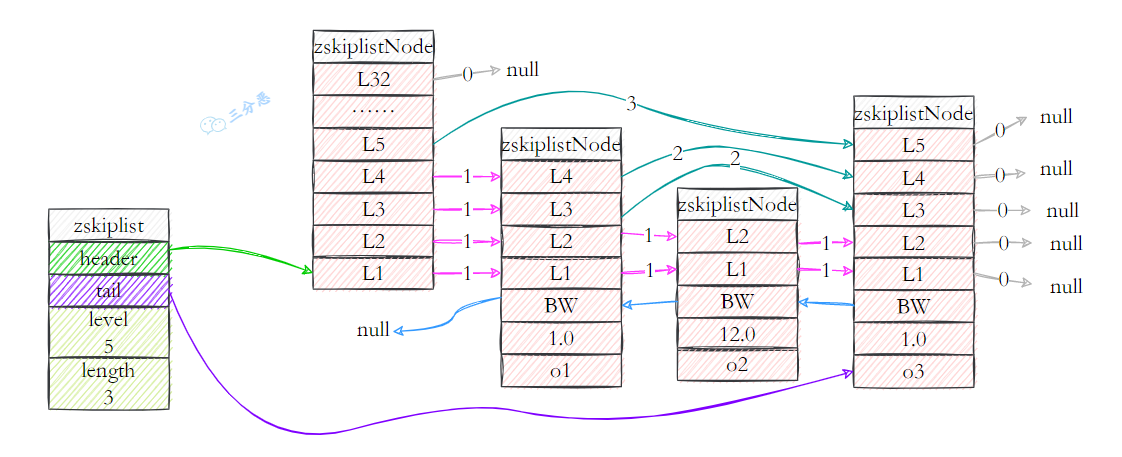
为什么使用跳表?
首先,因为 zset 要支持随机的插入和删除,所以它 不宜使用数组来实现,关于排序问题,我们也很容易就想到 红黑树/ 平衡树 这样的树形结构,为什么 Redis 不使用这样一些结构呢?
- 性能考虑: 在高并发的情况下,树形结构需要执行一些类似于 rebalance 这样的可能涉及整棵树的操作,相对来说跳跃表的变化只涉及局部;
- 实现考虑: 在复杂度与红黑树相同的情况下,跳跃表实现起来更简单,看起来也更加直观;
基于以上的一些考虑,Redis 基于 William Pugh 的论文做出一些改进后采用了 跳跃表 这样的结构。
跳跃表是怎么实现的?
①、层
跳跃表节点的 level 数组可以包含多个元素,每个元素都包含一个指向其它节点的指针,程序可以通过这些层来加快访问其它节点的速度,一般来说,层的数量月多,访问其它节点的速度就越快。
每次创建一个新的跳跃表节点的时候,程序都根据幂次定律,随机生成一个介于 1 和 32 之间的值作为 level 数组的大小,这个大小就是层的“高度”
②、前进指针
每个层都有一个指向表尾的前进指针(level[i].forward 属性),用于从表头向表尾方向访问节点。
我们看一下跳跃表从表头到表尾,遍历所有节点的路径:
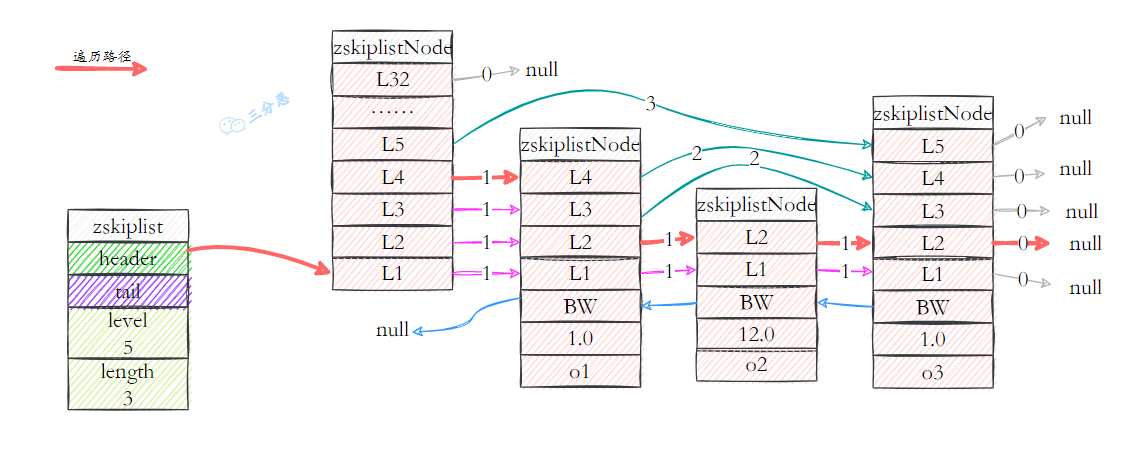
③、跨度
层的跨度用于记录两个节点之间的距离。跨度是用来计算排位(rank)的:在查找某个节点的过程中,将沿途访问过的所有层的跨度累计起来,得到的结果就是目标节点在跳跃表中的排位。
例如查找,分值为 3.0、成员对象为 o3 的节点时,沿途经历的层:查找的过程只经过了一个层,并且层的跨度为 3,所以目标节点在跳跃表中的排位为 3。
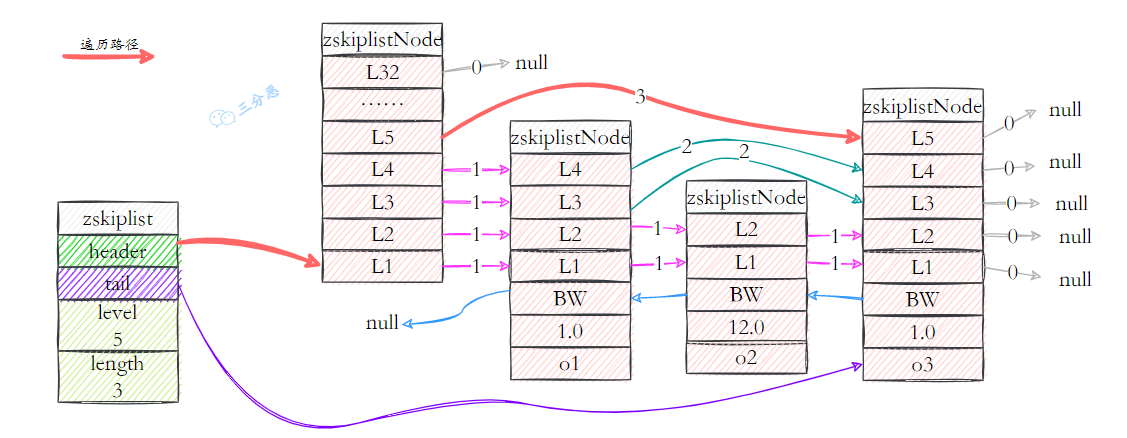
④、分值和成员
节点的分值(score 属性)是一个 double 类型的浮点数,跳跃表中所有的节点都按分值从小到大来排序。
节点的成员对象(obj 属性)是一个指针,它指向一个字符串对象,而字符串对象则保存这一个 SDS 值。
为什么 hash 表范围查询效率比跳表低?
哈希表是一种基于键值对的数据结构,主要用于快速查找、插入和删除操作。
哈希表通过计算键的哈希值来确定值的存储位置,这使得它在单个元素的访问上非常高效,时间复杂度为 O(1)。
然而,哈希表内的元素是无序的。因此,对于范围查询(如查找所有在某个范围内的元素),哈希表无法直接支持,必须遍历整个表来检查哪些元素满足条件,这使得其在范围查询上的效率低下,时间复杂度为 O(n)。
跳表是一种有序的数据结构,能够保持元素的排序顺序。
它通过多层的链表结构实现快速的插入、删除和查找操作,其中每一层都是下一层的一个子集,并且元素在每一层都是有序的。
当进行范围查询时,跳表可以从最高层开始,快速定位到范围的起始点,然后沿着下一层继续直到找到范围的结束点。这种分层的结构使得跳表在进行范围查询时非常高效,时间复杂度为 O(log n) 加上范围内元素的数量。
48.压缩列表了解吗?
压缩列表是 Redis 为了节约内存 而使用的一种数据结构,是由一系列特殊编码的连续内存快组成的顺序型数据结构。
一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。
压缩列表由这么几部分组成:
- zlbyttes:记录整个压缩列表占用的内存字节数
- zltail:记录压缩列表表尾节点距离压缩列表的起始地址有多少字节
- zllen:记录压缩列表包含的节点数量
- entryX:列表节点
- zlend:用于标记压缩列表的末端

49.快速列表 quicklist 了解吗?
Redis 早期版本存储 list 列表数据结构使用的是压缩列表 ziplist 和普通的双向链表 linkedlist,也就是说当元素少时使用 ziplist,当元素多时用 linkedlist。
但考虑到链表的附加空间相对较高,prev 和 next 指针就要占去 16 个字节(64 位操作系统占用 8 个字节),另外每个节点的内存都是单独分配,会家具内存的碎片化,影响内存管理效率。
后来 Redis 新版本(3.2)对列表数据结构进行了改造,使用 quicklist 代替了 ziplist 和 linkedlist,quicklist 是综合考虑了时间效率与空间效率引入的新型数据结构。
quicklist 由 list 和 ziplist 结合而成,它是一个由 ziplist 充当节点的双向链表。
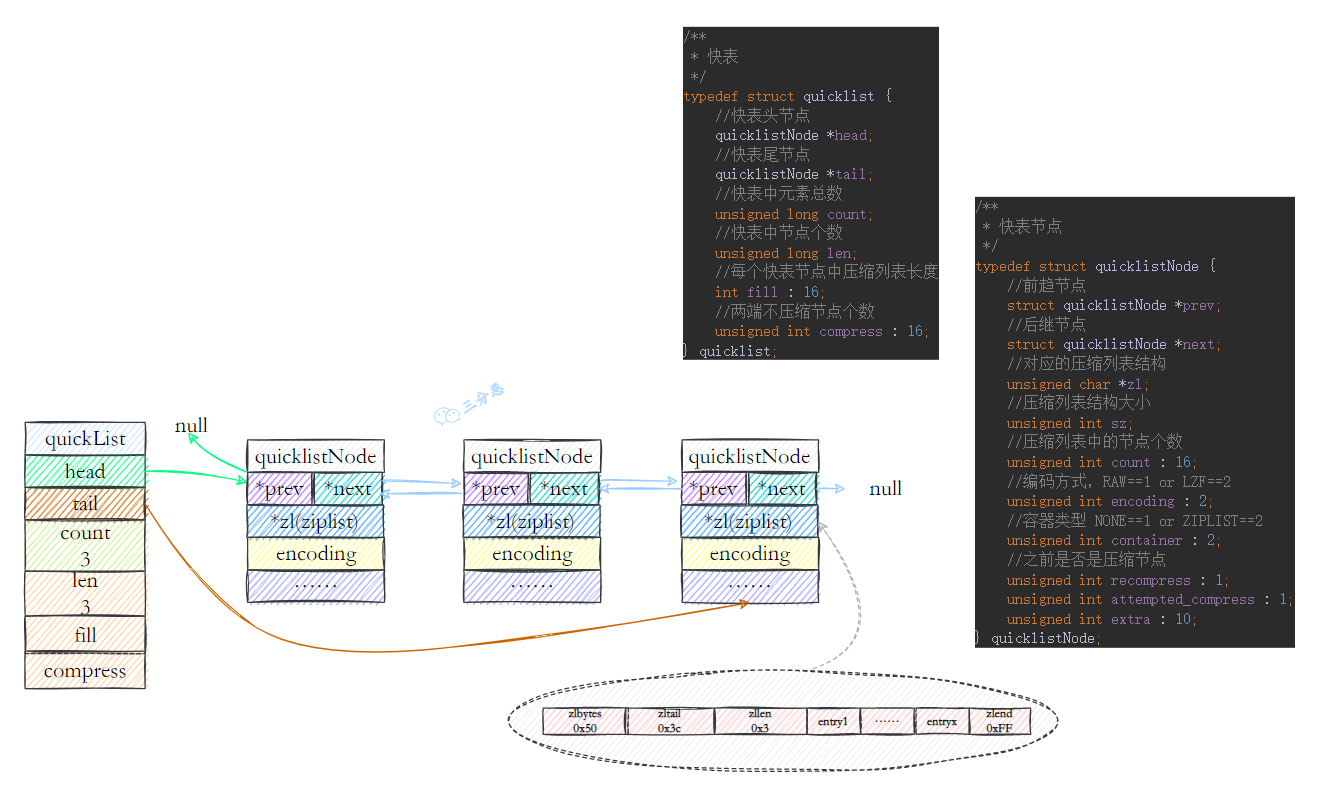
50.假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如何将它们全部找出来?
使用 keys 指令可以扫出指定模式的 key 列表。但是要注意 keys 指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用 scan 指令,scan 指令可以无阻塞的提取出指定模式的 key 列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用 keys 指令长。
与 KEYS 命令不同,SCAN 命令是增量迭代的,不会一次性返回所有结果,从而避免了阻塞服务器的问题。
51.秒杀问题(错峰、削峰、前端、流量控制)
秒杀主要是指大量用户集中在短时间内对服务器进行访问,从而导致服务器负载剧增,可能出现系统响应缓慢甚至崩溃的情况。
解决这一问题的关键就在于错峰削峰和限流。当然了,前端页面的静态化、按钮防抖也能够有效的减轻服务器的压力。
- 页面静态化:将商品详情等页面静态化,使用 CDN 分发。
- 按钮防抖:避免用户因频繁点击造成的额外请求,比如设定间隔时间后才能再次点击。
如何实现错峰削峰呢?
在秒杀场景下,可以通过以下几种方式实现错峰削峰:
①、预热缓存:提前将热点数据加载到 Redis 缓存中,减少对数据库的访问压力。
②、消息队列:引入消息队列,将请求异步处理,减少瞬时请求压力。消息队列就像一个水库,可以削减上游的洪峰流量。
③、多阶段多时间窗口:将秒杀活动分为多个阶段,每个阶段设置不同的时间窗口,让用户在不同的时间段内参与秒杀活动。
④、插入答题系统:在秒杀活动中加入答题环节,只有答对题目的用户才能参与秒杀活动,这样可以减少无效请求。
如何限流呢?
采用令牌桶算法
在实际开发中,我们需要维护一个容器,按照固定的速率往容器中放令牌(token),当请求到来时,从容器中取出一个令牌,如果容器中没有令牌,则拒绝请求。
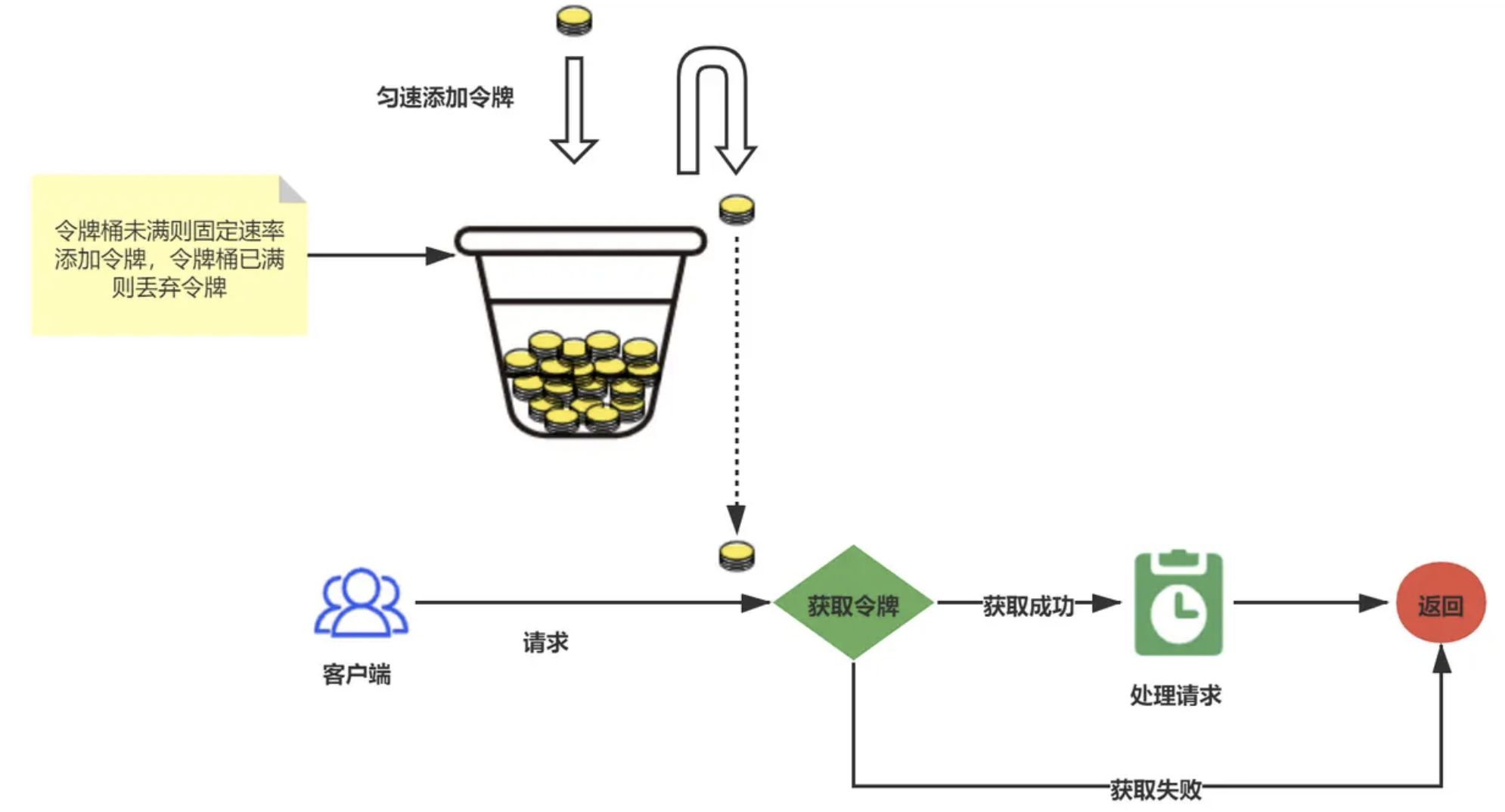
第一步,使用 Redis 初始化令牌桶:
redis-cli SET "token_bucket" "100"
第二步,使用 Lua 脚本实现令牌桶算法;假设每秒向桶中添加 10 个令牌,但不超过桶的最大容量。
-- Lua 脚本来添加令牌,并确保不超过最大容量
local bucket = KEYS[1]
local add_count = tonumber(ARGV[1])
local max_tokens = tonumber(ARGV[2])
local current = tonumber(redis.call('GET', bucket) or 0)
local new_count = math.min(current + add_count, max_tokens)
redis.call('SET', bucket, tostring(new_count))
return new_count
第三步,使用 Shell 脚本调用 Lua 脚本:
// !/bin/bash
while true; do
redis-cli EVAL "$(cat add_tokens.lua)" 1 token_bucket 10 100
sleep 1
done
第四步,当请求到达时,需要检查并消耗一个令牌。
-- Lua 脚本来消耗一个令牌
local bucket = KEYS[1]
local tokens = tonumber(redis.call('GET', bucket) or 0)
if tokens > 0 then
redis.call('DECR', bucket)
return 1 -- 成功消耗令牌
else
return 0 -- 令牌不足
end
调用 Lua 脚本:
redis-cli EVAL "$(cat consume_token.lua)" 1 token_bucket
MyBatis
1.什么是MyBatis?
优点:
- Mybatis 是一个半 ORM(对象关系映射)框架,它内部封装了 JDBC,开发时只需要关注 SQL 语句本身,不需要花费精力去处理加载驱动、创建连接、创建 statement 等繁杂的过程。程序员直接编写原生态 sql,可以严格控制 sql 执行性能,灵活度高。
- MyBatis 可以使用 XML 或注解来配置和映射原生信息,将 POJO 映射成数据库中的记录,避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
缺点:
- SQL 语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写 SQL 语句的功底有一定要求
- SQL 语句依赖于数据库,导致数据库移植性差,不能随意更换数据库
ORM是什么?
ORM(Object Relational Mapping),对象关系映射,是一种为了解决关系型数据库数据与简单 Java 对象(POJO)的映射关系的技术。简单来说,ORM 是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系型数据库中。
为什么说 Mybatis 是半自动 ORM 映射工具?它与全自动的区别在哪里?
- Hibernate 属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。
- 而 Mybatis 在查询关联对象或关联集合对象时,需要手动编写 SQL 来完成,所以,被称之为半自动 ORM 映射工具。
JDBC 编程有哪些不足之处,MyBatis 是如何解决的?

- 1、数据连接创建、释放频繁造成系统资源浪费从而影响系统性能,在 mybatis-config.xml 中配置数据链接池,使用连接池统一管理数据库连接。
- 2、sql 语句写在代码中造成代码不易维护,将 sql 语句配置在 XXXXmapper.xml 文件中与 java 代码分离。
- 3、向 sql 语句传参数麻烦,因为 sql 语句的 where 条件不一定,可能多也可能少,占位符需要和参数一一对应。Mybatis 自动将 java 对象映射至 sql 语句。
- 4、对结果集解析麻烦,sql 变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成 pojo 对象解析比较方便。Mybatis 自动将 sql 执行结果映射至 java 对象。
2. Hibernate 和 MyBatis 有什么区别?
相同点:
都是对 jdbc 的封装,都是应用于持久层的框架。
不同点:
1)映射关系
- MyBatis 是一个半自动映射的框架,配置 Java 对象与 sql 语句执行结果的对应关系,多表关联关系配置简单
- Hibernate 是一个全表映射的框架,配置 Java 对象与数据库表的对应关系,多表关联关系配置复杂
2)SQL 优化和移植性
- Hibernate 对 SQL 语句封装,提供了日志、缓存、级联(级联比 MyBatis 强大)等特性,此外还提供 HQL(Hibernate Query Language)操作数据库,数据库无关性支持好,但会多消耗性能。如果项目需要支持多种数据库,代码开发量少,但 SQL 语句优化困难。
- MyBatis 需要手动编写 SQL,支持动态 SQL、处理列表、动态生成表名、支持存储过程。开发工作量相对大些。直接使用 SQL 语句操作数据库,不支持数据库无关性,但 sql 语句优化容易。
3)MyBatis 和 Hibernate 的适用场景不同
- Hibernate 是标准的 ORM 框架,SQL 编写量较少,但不够灵活,适合于需求相对稳定,中小型的软件项目,比如:办公自动化系统
- MyBatis 是半 ORM 框架,需要编写较多 SQL,但是比较灵活,适合于需求变化频繁,快速迭代的项目,比如:电商网站
3.MyBatis 使用过程?生命周期?
使用过程
MyBatis 基本使用的过程大概可以分为这么几步:
1)创建 SqlSessionFactory
可以从配置或者直接编码来创建 SqlSessionFactory
String resource = "org/mybatis/example/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
2)通过 SqlSessionFactory 创建 SqlSession
SqlSession(会话)可以理解为程序和数据库之间的桥梁
SqlSession session = sqlSessionFactory.openSession();
3)通过 sqlsession 执行数据库操作
可以通过 SqlSession 实例来直接执行已映射的 SQL 语句:
Blog blog = (Blog)session.selectOne("org.mybatis.example.BlogMapper.selectBlog", 101);
更常用的方式是先获取 Mapper(映射),然后再执行 SQL 语句:
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlog(101);
4)调用 session.commit()提交事务
如果是更新、删除语句,我们还需要提交一下事务。
5)调用 session.close()关闭会话
最后一定要记得关闭会话。
生命周期
上面提到了几个 MyBatis 的组件,一般说的 MyBatis 生命周期就是这些组件的生命周期。
SqlSessionFactoryBuilder:
一旦创建了 SqlSessionFactory,就不再需要它了。 因此 SqlSessionFactoryBuilder 实例的生命周期只存在于方法的内部。
SqlSessionFactory:
SqlSessionFactory 是用来创建 SqlSession 的,相当于一个数据库连接池,每次创建 SqlSessionFactory 都会使用数据库资源,多次创建和销毁是对资源的浪费。所以 SqlSessionFactory 是应用级的生命周期,而且应该是单例的。
SqlSession:
SqlSession 相当于 JDBC 中的 Connection,SqlSession 的实例不是线程安全的,因此是不能被共享的,所以它的最佳的生命周期是一次请求或一个方法。
Mapper:
映射器是一些绑定映射语句的接口。映射器接口的实例是从 SqlSession 中获得的,它的生命周期在 sqlsession 事务方法之内,一般会控制在方法级。
MyBatis 通常也是和 Spring 集成使用,Spring 可以帮助我们创建线程安全的、基于事务的 SqlSession 和映射器,并将它们直接注入到我们的 bean 中,我们不需要关心它们的创建过程和生命周期。
4.在 mapper 中如何传递多个参数?
方法 1:顺序传参法:
public User selectUser(String name, int deptId);
<select id="selectUser" resultMap="UserResultMap">
select * from user
where user_name = #{0} and dept_id = #{1}
</select>
\#{}里面的数字代表传入参数的顺序。- 这种方法不建议使用,sql 层表达不直观,且一旦顺序调整容易出错。
方法 2:@Param 注解传参法:
public User selectUser(@Param("userName") String name, int @Param("deptId") deptId);
<select id="selectUser" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
</select>
\#{}里面的名称对应的是注解@Param 括号里面修饰的名称。- 这种方法在参数不多的情况还是比较直观的,(推荐使用)。
方法 3:Map 传参法:
public User selectUser(Map<String, Object> params);
<select id="selectUser" parameterType="java.util.Map" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
</select>
\#{}里面的名称对应的是 Map 里面的 key 名称。- 这种方法适合传递多个参数,且参数易变能灵活传递的情况。
方法 4:Java Bean 传参法:
public User selectUser(User user);
<select id="selectUser" parameterType="com.jourwon.pojo.User" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
</select>
\#{}里面的名称对应的是 User 类里面的成员属性。- 这种方法直观,需要建一个实体类,扩展不容易,需要加属性,但代码可读性强,业务逻辑处理方便,推荐使用。(推荐使用)。
5.实体类属性名和表中字段名不一样 ,怎么办?
第 1 种: 通过在查询的 SQL 语句中定义字段名的别名,让字段名的别名和实体类的属性名一致。
<select id="getOrder" parameterType="int" resultType="com.jourwon.pojo.Order">
select order_id id, order_no orderno ,order_price price form orders where order_id=#{id};
</select>
第 2 种: 通过 resultMap 中的<result>来映射字段名和实体类属性名的一一对应的关系。
<select id="getOrder" parameterType="int" resultMap="orderResultMap">
select * from orders where order_id=#{id}
</select>
<resultMap type="com.jourwon.pojo.Order" id="orderResultMap">
<!–用id属性来映射主键字段–>
<id property="id" column="order_id">
<!–用result属性来映射非主键字段,property为实体类属性名,column为数据库表中的属性–>
<result property ="orderno" column ="order_no"/>
<result property="price" column="order_price" />
</resultMap>
6.Mybatis 是否可以映射 Enum 枚举类?
Mybatis 当然可以映射枚举类,不单可以映射枚举类,Mybatis 可以映射任何对象到表的一列上。映射方式为自定义一个 TypeHandler,实现 TypeHandler 的 setParameter()和 getResult()接口方法。
TypeHandler 有两个作用,一是完成从 javaType 至 jdbcType 的转换,二是完成 jdbcType 至 javaType 的转换,体现为 setParameter()和 getResult()两个方法,分别代表设置 sql 问号占位符参数和获取列查询结果。
7.#{}和${}的区别?
在 MyBatis 中,#{} 和 ${}是两种不同的占位符,#{} 是预编译处理,${} 是字符串替换。
①、当使用 #{} 时,MyBatis 会在 SQL 执行之前,将占位符替换为问号 ?,并使用参数值来替代这些问号。
由于 #{} 使用了预处理,它能有效防止 SQL 注入,可以确保参数值在到达数据库之前被正确地处理和转义。
<select id="selectUser" resultType="User">
SELECT * FROM users WHERE id = #{id}
</select>
②、当使用 ${} 时,参数的值会直接替换到 SQL 语句中去,而不会经过预处理。
这就存在 SQL 注入的风险,因为参数值会直接拼接到 SQL 语句中,假如参数值是 1 or 1=1,那么 SQL 语句就会变成 SELECT * FROM users WHERE id = 1 or 1=1,这样就会导致查询所有用户的结果。
${} 通常用于那些不能使用预处理的场合,比如说动态表名、列名、排序等,要提前对参数进行安全性校验。
<select id="selectUsersByOrder" resultType="User">
SELECT * FROM users ORDER BY ${columnName} ASC
</select>
8.模糊查询 like 语句该怎么写?
- 1
’%${question}%’可能引起 SQL 注入,不推荐 - 2
"%"#{question}"%"注意:因为#{…}解析成 sql 语句时候,会在变量外侧自动加单引号’ ‘,所以这里 % 需要使用双引号” “,不能使用单引号 ’ ‘,不然会查不到任何结果。 - 3
CONCAT('%',#{question},'%')使用CONCAT()函数,(推荐 ✨) - 4 使用 bind 标签(不推荐)
<select id="listUserLikeUsername" resultType="com.jourwon.pojo.User">
  <bind name="pattern" value="'%' + username + '%'" />
  select id,sex,age,username,password from person where username LIKE #{pattern}
</select>
9.Mybatis 能执行一对一、一对多的关联查询吗?
是的,MyBatis 可以执行一对一和一对多的关联查询。通过配置 resultMap 和使用 association 和 collection 元素,可以实现复杂的对象关系映射。
一对一关联查询
一对一关联查询通常用于将一个对象的属性映射到另一个对象。假设我们有两个表 User 和 Address,每个用户都有一个地址。
数据库表结构
CREATE TABLE User (
id INT PRIMARY KEY,
name VARCHAR(50),
address_id INT
);
CREATE TABLE Address (
id INT PRIMARY KEY,
street VARCHAR(50),
city VARCHAR(50)
);
实体类
public class User {
private int id;
private String name;
private Address address;
// getters and setters
}
public class Address {
private int id;
private String street;
private String city;
// getters and setters
}
Mapper XML 配置
<resultMap id="userResultMap" type="com.example.model.User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<association property="address" javaType="com.example.model.Address">
<id property="id" column="address_id"/>
<result property="street" column="street"/>
<result property="city" column="city"/>
</association>
</resultMap>
<select id="getUserById" resultMap="userResultMap">
SELECT u.id, u.name, a.id AS address_id, a.street, a.city
FROM User u
LEFT JOIN Address a ON u.address_id = a.id
WHERE u.id = #{id}
</select>
一对多关联查询
一对多关联查询通常用于将一个对象的属性映射到一个对象集合。假设我们有两个表 User 和 Order,每个用户可以有多个订单。
数据库表结构
CREATE TABLE User (
id INT PRIMARY KEY,
name VARCHAR(50)
);
CREATE TABLE Order (
id INT PRIMARY KEY,
user_id INT,
order_no VARCHAR(50),
price DECIMAL(10, 2)
);
实体类
public class User {
private int id;
private String name;
private List<Order> orders;
// getters and setters
}
public class Order {
private int id;
private String orderNo;
private BigDecimal price;
// getters and setters
}
Mapper XML 配置
<resultMap id="userResultMap" type="com.example.model.User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<collection property="orders" ofType="com.example.model.Order">
<id property="id" column="order_id"/>
<result property="orderNo" column="order_no"/>
<result property="price" column="price"/>
</collection>
</resultMap>
<select id="getUserWithOrders" resultMap="userResultMap">
SELECT u.id, u.name, o.id AS order_id, o.order_no, o.price
FROM User u
LEFT JOIN Order o ON u.id = o.user_id
WHERE u.id = #{id}
</select>
10.Mybatis 是否支持延迟加载?原理?
| Mybatis 支持 association 关联对象和 collection 关联集合对象的延迟加载,association 指的就是一对一,collection 指的就是一对多查询。在 Mybatis 配置文件中,可以配置是否启用延迟加载 lazyLoadingEnabled=true | false。 |
它的原理是,使用 CGLIB 创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用 a.getB().getName(),拦截器 invoke()方法发现 a.getB()是 null 值,那么就会单独发送事先保存好的查询关联 B 对象的 sql,把 B 查询上来,然后调用 a.setB(b),于是 a 的对象 b 属性就有值了,接着完成 a.getB().getName()方法的调用。这就是延迟加载的基本原理。
不光是 Mybatis,几乎所有的包括 Hibernate,支持延迟加载的原理都是一样的。
11.如何获取生成的主键?
新增标签中添加:keyProperty=” ID “ 即可
<insert id="insert" useGeneratedKeys="true" keyProperty="userId" >
insert into user(
user_name, user_password, create_time)
values(#{userName}, #{userPassword} , #{createTime, jdbcType= TIMESTAMP})
</insert>
这时候就可以完成回填主键
mapper.insert(user);
user.getId;
12.MyBatis 支持动态 SQL 吗?
MyBatis 中有一些支持动态 SQL 的标签,它们的原理是使用 OGNL(Object-Graph Navigation Language) 从 SQL 参数对象中计算表达式的值,根据表达式的值动态拼接 SQL,以此来完成动态 SQL 的功能。
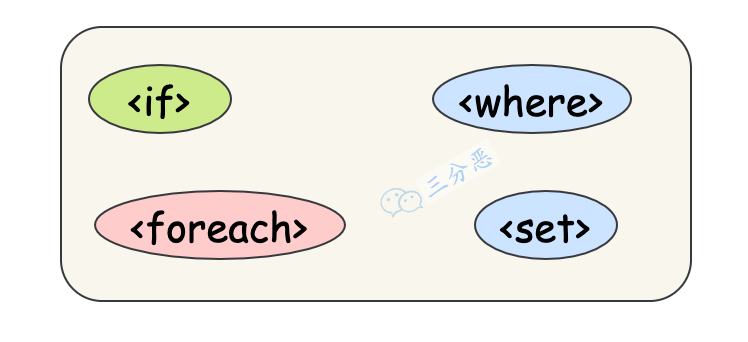
if:
根据条件来组成 where 子句
<select id="findActiveBlogWithTitleLike"
resultType="Blog">
SELECT * FROM BLOG
WHERE state = ‘ACTIVE’
<if test="title != null">
AND title like #{title}
</if>
</select>
choose (when, otherwise):
这个和 Java 中的 switch 语句有点像
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<choose>
<when test="title != null">
AND title like #{title}
</when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
</when>
<otherwise>
AND featured = 1
</otherwise>
</choose>
</select>
where:
<where>可以用在所有的查询条件都是动态的情况
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
set:
可以用在动态更新的时候
<update id="updateAuthorIfNecessary">
update Author
<set>
<if test="username != null">username=#{username},</if>
<if test="password != null">password=#{password},</if>
<if test="email != null">email=#{email},</if>
<if test="bio != null">bio=#{bio}</if>
</set>
where id=#{id}
</update>
foreach:
看到名字就知道了,这个是用来循环的,可以对集合进行遍历
<select id="selectPostIn" resultType="domain.blog.Post">
SELECT *
FROM POST P
<where>
<foreach item="item" index="index" collection="list"
open="ID in (" separator="," close=")" nullable="true">
#{item}
</foreach>
</where>
</select>
13.MyBatis 如何执行批量操作?
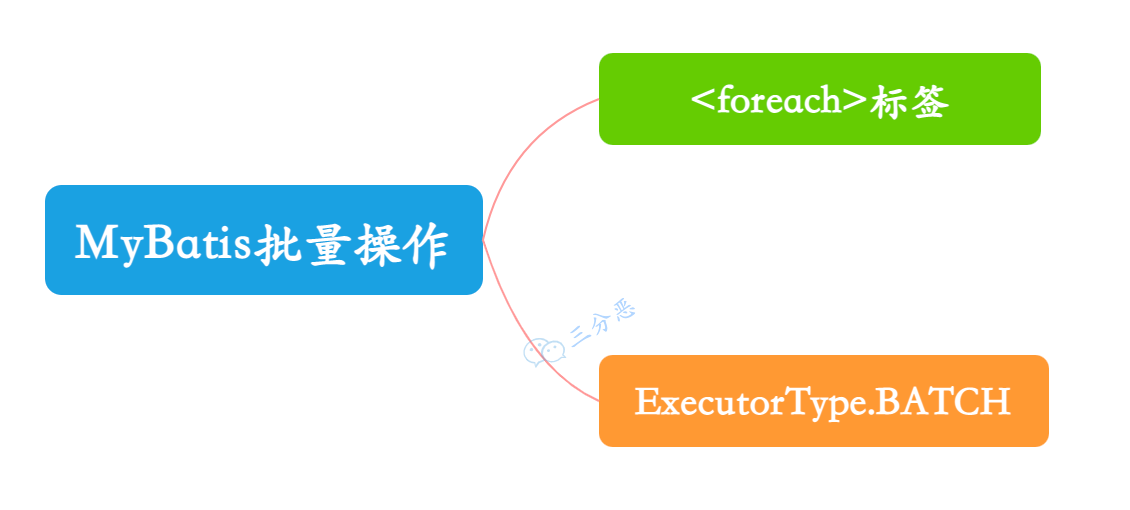
使用 foreach 标签
foreach 的主要用在构建 in 条件中,它可以在 SQL 语句中进行迭代一个集合。foreach 标签的属性主要有 item,index,collection,open,separator,close。
- item 表示集合中每一个元素进行迭代时的别名,随便起的变量名;
- index 指定一个名字,用于表示在迭代过程中,每次迭代到的位置,不常用;
- open 表示该语句以什么开始,常用“(”;
- separator 表示在每次进行迭代之间以什么符号作为分隔符,常用“,”;
- close 表示以什么结束,常用“)”。
在使用 foreach 的时候最关键的也是最容易出错的就是 collection 属性,该属性是必须指定的,但是在不同情况下,该属性的值是不一样的,主要有以下 3 种情况:
1.如果传入的是单参数且参数类型是一个 List 的时候,collection 属性值为 list
2.如果传入的是单参数且参数类型是一个 array 数组的时候,collection 的属性值为 array
3.如果传入的参数是多个的时候,我们就需要把它们封装成一个 Map 了,当然单参数也可以封装成 map,实际上如果你在传入参数的时候,在 MyBatis 里面也是会把它封装成一个 Map 的,map 的 key 就是参数名,所以这个时候 collection 属性值就是传入的 List 或 array 对象在自己封装的 map 里面的 key
<!-- MySQL下批量保存,可以foreach遍历 mysql支持values(),(),()语法 --> //推荐使用
<insert id="addEmpsBatch">
INSERT INTO emp(ename,gender,email,did)
VALUES
<foreach collection="emps" item="emp" separator=",">
(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})
</foreach>
</insert>
<!-- 这种方式需要数据库连接属性allowMutiQueries=true的支持
如jdbc.url=jdbc:mysql://localhost:3306/mybatis?allowMultiQueries=true -->
<insert id="addEmpsBatch">
<foreach collection="emps" item="emp" separator=";">
INSERT INTO emp(ename,gender,email,did)
VALUES(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})
</foreach>
</insert>
使用 ExecutorType.BATCH
Mybatis 内置的 ExecutorType 有 3 种,默认为 simple,该模式下它为每个语句的执行创建一个新的预处理语句,单条提交 sql;
而 batch 模式重复使用已经预处理的语句,并且批量执行所有更新语句,显然 batch 性能将更优;
但 batch 模式也有自己的问题,比如在 Insert 操作时,在事务没有提交之前,是没有办法获取到自增的 id,在某些情况下不符合业务的需求。
//批量保存方法测试
@Test
public void testBatch() throws IOException{
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
//可以执行批量操作的sqlSession
SqlSession openSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
//批量保存执行前时间
long start = System.currentTimeMillis();
try {
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
for (int i = 0; i < 1000; i++) {
mapper.addEmp(new Employee(UUID.randomUUID().toString().substring(0, 5), "b", "1"));
}
openSession.commit();
long end = System.currentTimeMillis();
//批量保存执行后的时间
System.out.println("执行时长" + (end - start));
//批量 预编译sql一次==》设置参数==》10000次==》执行1次 677
//非批量 (预编译=设置参数=执行 )==》10000次 1121
} finally {
openSession.close();
}
}
mapper 和 mapper.xml 如下
public interface EmployeeMapper {
//批量保存员工
Long addEmp(Employee employee);
}
<mapper namespace="com.jourwon.mapper.EmployeeMapper"
<!--批量保存员工 -->
<insert id="addEmp">
insert into employee(lastName,email,gender)
values(#{lastName},#{email},#{gender})
</insert>
</mapper>
14.说说 Mybatis 的一级、二级缓存?
一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 SqlSession,各个 SqlSession 之间的缓存相互隔离,当 Session flush 或 close 之后,该 SqlSession 中的所有 Cache 就将清空,MyBatis 默认打开一级缓存。
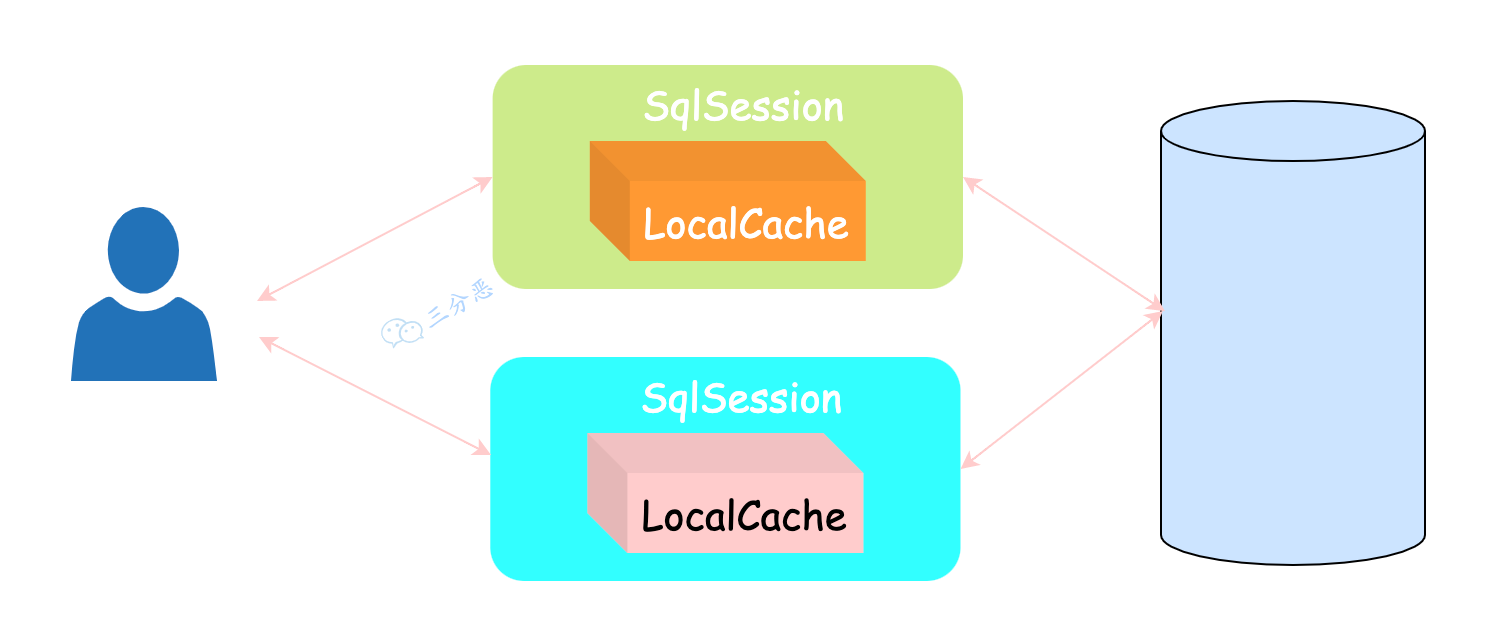
二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同之处在于其存储作用域为 Mapper(Namespace),可以在多个 SqlSession 之间共享,并且可自定义存储源,如 Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现 Serializable 序列化接口(可用来保存对象的状态),可在它的映射文件中配置。
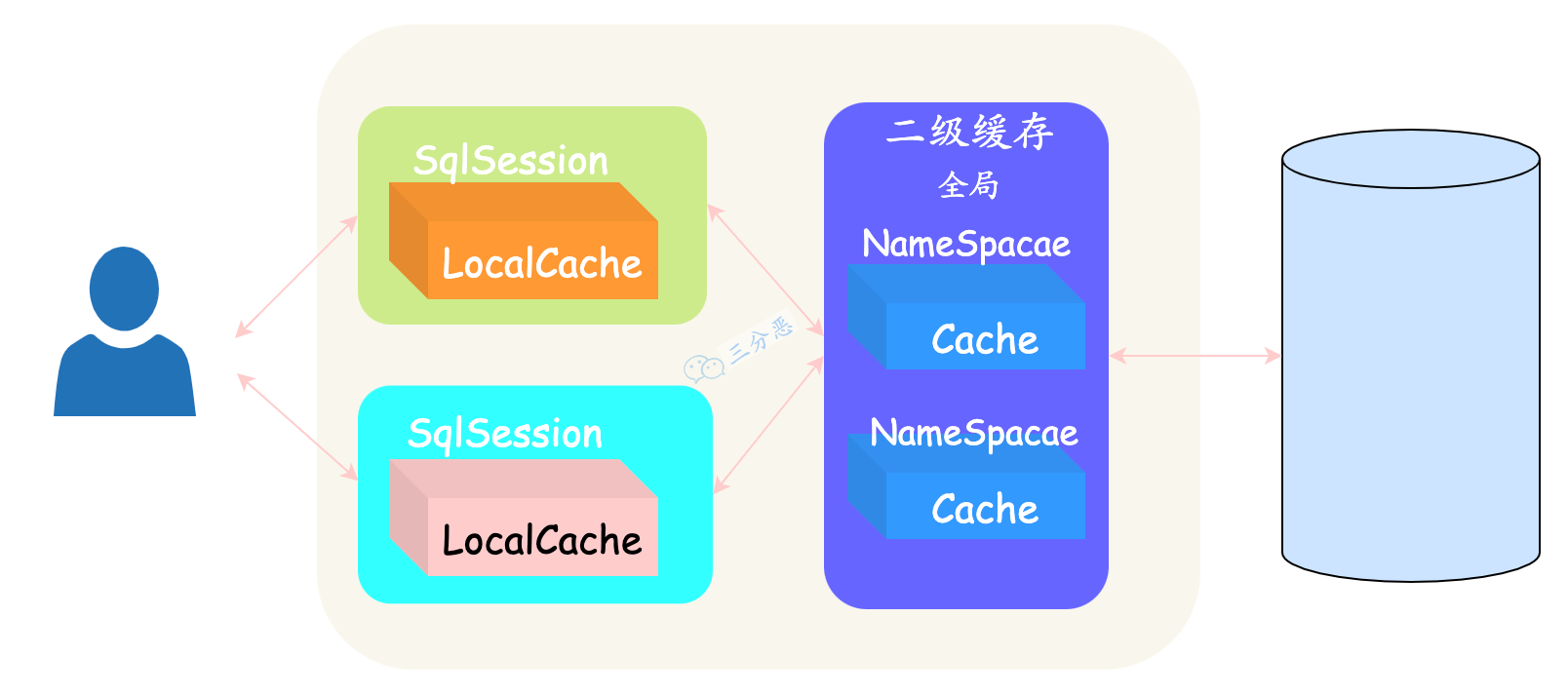
15.能说说 MyBatis 的工作原理吗?
我们已经大概知道了 MyBatis 的工作流程,按工作原理,可以分为两大步:生成会话工厂、会话运行。
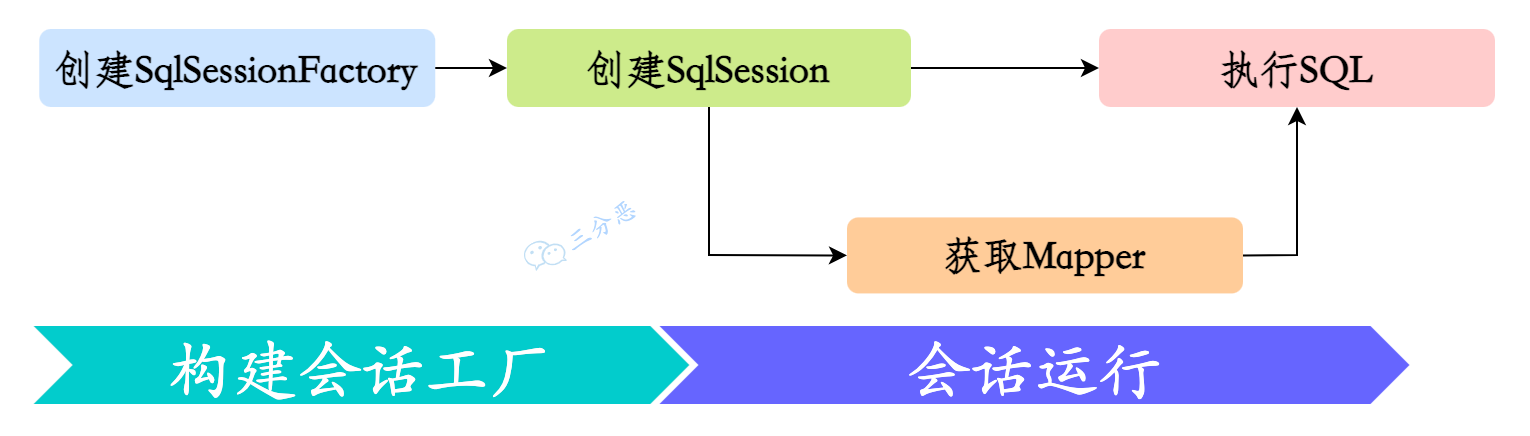
构建会话工厂
构造会话工厂也可以分为两步:
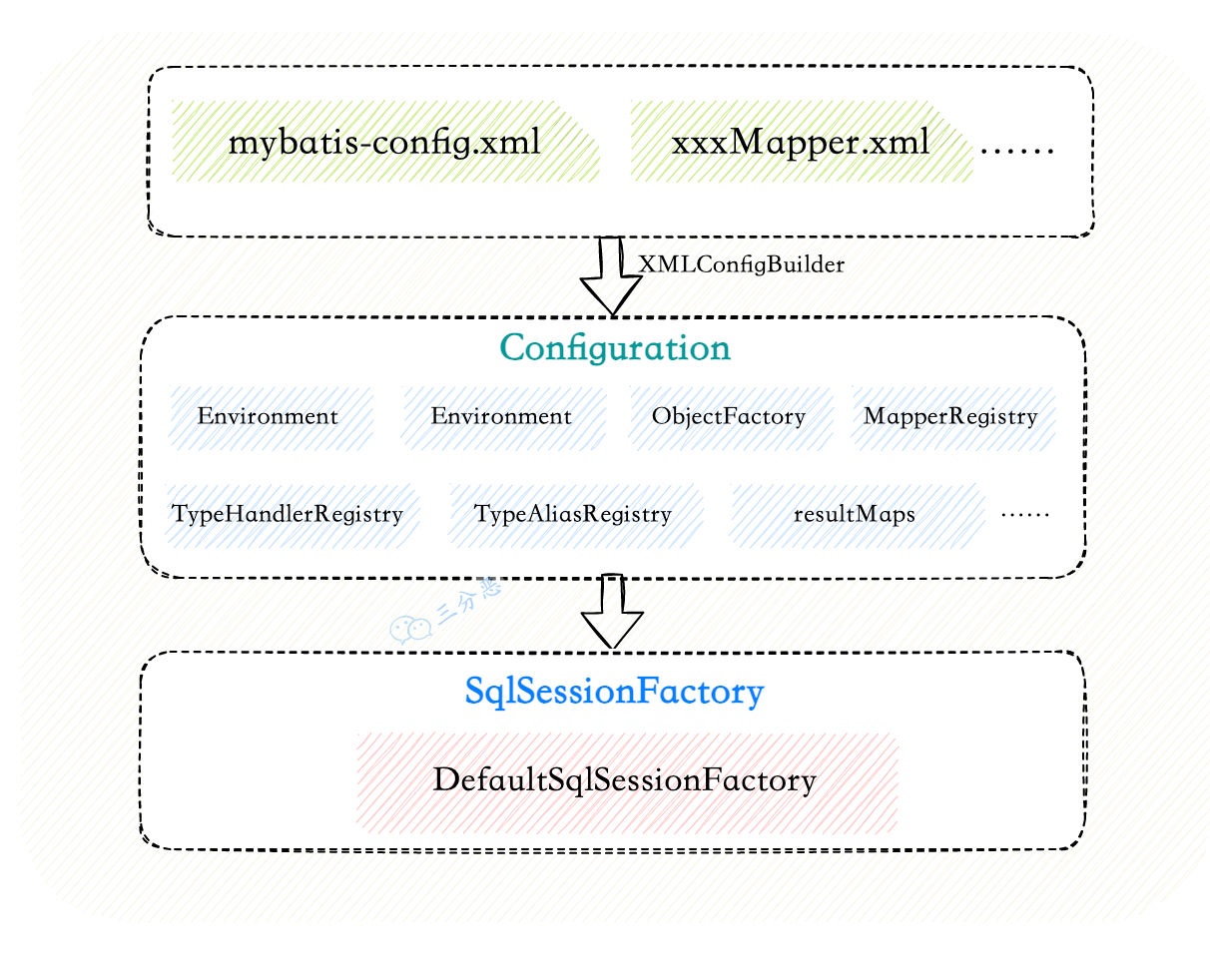
获取配置:
获取配置这一步经过了几步转化,最终由生成了一个配置类 Configuration 实例,这个配置类实例非常重要,主要作用包括:
- 读取配置文件,包括基础配置文件和映射文件
- 初始化基础配置,比如 MyBatis 的别名,还有其它的一些重要的类对象,像插件、映射器、ObjectFactory 等等
- 提供一个单例,作为会话工厂构建的重要参数
- 它的构建过程也会初始化一些环境变量,比如数据源
public SqlSessionFactory build(Reader reader, String environment, Properties properties) {
SqlSessionFactory var5;
//省略异常处理
//xml配置构建器
XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties);
//通过转化的Configuration构建SqlSessionFactory
var5 = this.build(parser.parse());
}
构建 SqlSessionFactory:
SqlSessionFactory 只是一个接口,构建出来的实际上是它的实现类的实例,一般我们用的都是它的实现类 DefaultSqlSessionFactory
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
会话运行
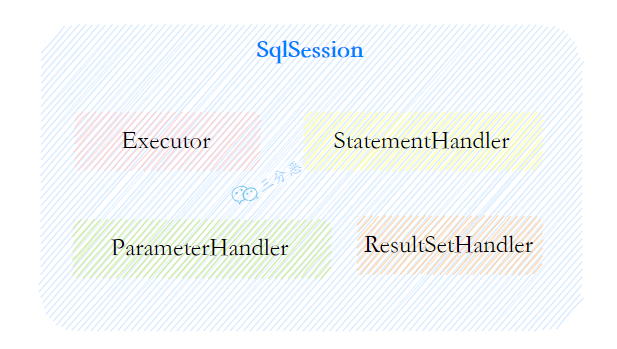
Executor(执行器):
Executor 起到了至关重要的作用,SqlSession 只是一个门面,相当于客服,真正干活的是是 Executor,就像是默默无闻的工程师。它提供了相应的查询和更新方法,以及事务方法。
Environment environment = this.configuration.getEnvironment();
TransactionFactory transactionFactory = this.getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//通过Configuration创建executor
Executor executor = this.configuration.newExecutor(tx, execType);
var8 = new DefaultSqlSession(this.configuration, executor, autoCommit);
StatementHandler(数据库会话器):
StatementHandler,顾名思义,处理数据库会话的。我们以 SimpleExecutor 为例,看一下它的查询方法,先生成了一个 StatementHandler 实例,再拿这个 handler 去执行 query。
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
List var9;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this.wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = this.prepareStatement(handler, ms.getStatementLog());
var9 = handler.query(stmt, resultHandler);
} finally {
this.closeStatement(stmt);
}
return var9;
}
再以最常用的 PreparedStatementHandler 看一下它的 query 方法,其实在上面的prepareStatement已经对参数进行了预编译处理,到了这里,就直接执行 sql,使用 ResultHandler 处理返回结果。
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement)statement;
ps.execute();
return this.resultSetHandler.handleResultSets(ps);
}
ParameterHandler (参数处理器):
PreparedStatementHandler 里对 sql 进行了预编译处理
public void parameterize(Statement statement) throws SQLException {
this.parameterHandler.setParameters((PreparedStatement)statement);
}
这里用的就是 ParameterHandler,setParameters 的作用就是设置预编译 SQL 语句的参数。
里面还会用到 typeHandler 类型处理器,对类型进行处理。
public interface ParameterHandler {
Object getParameterObject();
void setParameters(PreparedStatement var1) throws SQLException;
}
ResultSetHandler(结果处理器):
我们前面也看到了,最后的结果要通过 ResultSetHandler 来进行处理,handleResultSets 这个方法就是用来包装结果集的。Mybatis 为我们提供了一个 DefaultResultSetHandler,通常都是用这个实现类去进行结果的处理的。
public interface ResultSetHandler {
<E> List<E> handleResultSets(Statement var1) throws SQLException;
<E> Cursor<E> handleCursorResultSets(Statement var1) throws SQLException;
void handleOutputParameters(CallableStatement var1) throws SQLException;
}
它会使用 typeHandle 处理类型,然后用 ObjectFactory 提供的规则组装对象,返回给调用者。
整体上总结一下会话运行:
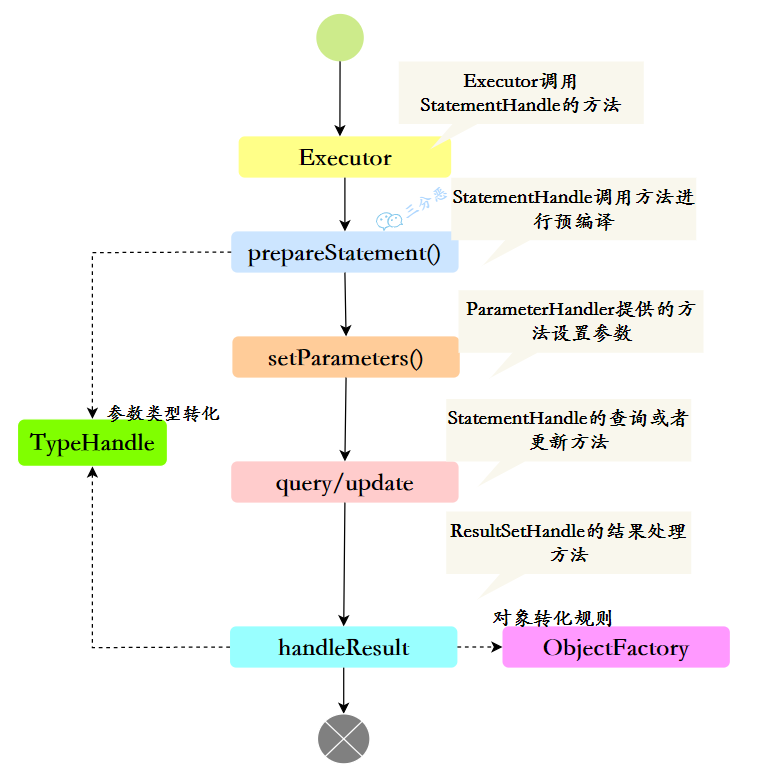
我们最后把整个的工作流程串联起来,简单总结一下:
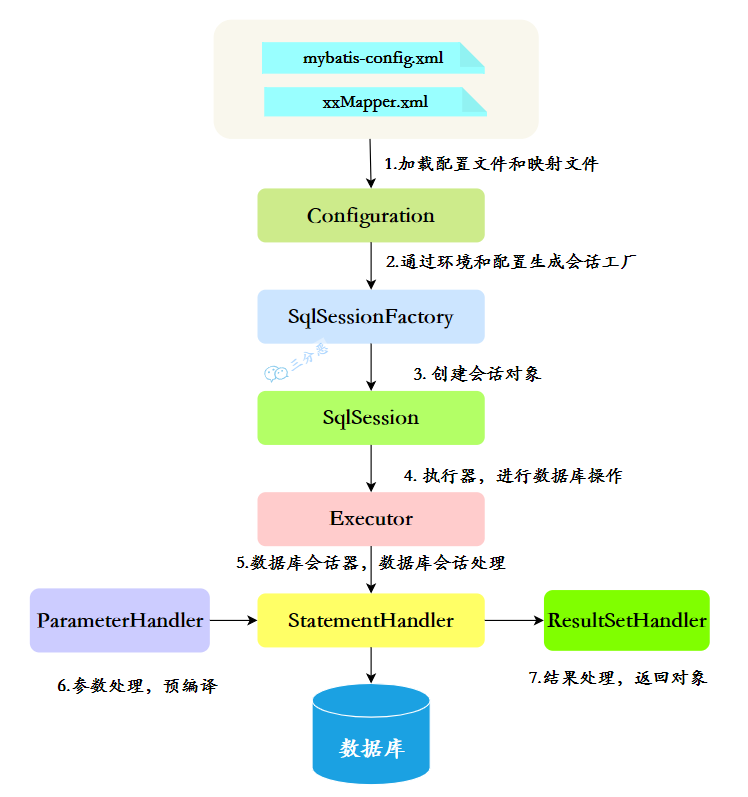
- 1.读取 MyBatis 配置文件——mybatis-config.xml 、加载映射文件——映射文件即 SQL 映射文件,文件中配置了操作数据库的 SQL 语句。最后生成一个配置对象。
- 2.构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory。
- 3.创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
- 4.Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。
- 5.StatementHandler:数据库会话器,串联起参数映射的处理和运行结果映射的处理。
- 6.参数处理:对输入参数的类型进行处理,并预编译。
- 7.结果处理:对返回结果的类型进行处理,根据对象映射规则,返回相应的对象。
16.MyBatis 的功能架构是什么样的?
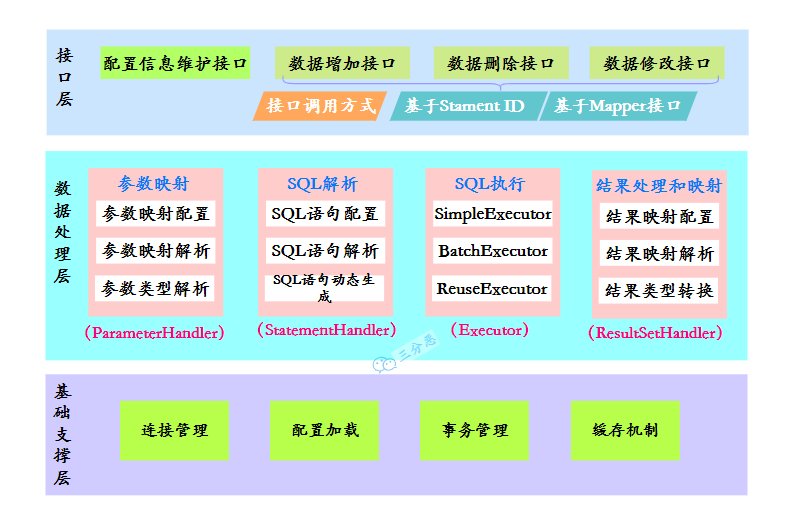
我们一般把 Mybatis 的功能架构分为三层:
- API 接口层:提供给外部使用的接口 API,开发人员通过这些本地 API 来操纵数据库。接口层一接收到调用请求就会调用数据处理层来完成具体的数据处理。
- 数据处理层:负责具体的 SQL 查找、SQL 解析、SQL 执行和执行结果映射处理等。它主要的目的是根据调用的请求完成一次数据库操作。
- 基础支撑层:负责最基础的功能支撑,包括连接管理、事务管理、配置加载和缓存处理,这些都是共用的东西,将他们抽取出来作为最基础的组件。为上层的数据处理层提供最基础的支撑。
17.为什么 Mapper 接口不需要实现类?
动态代理,我们来看一下获取 Mapper 的过程:
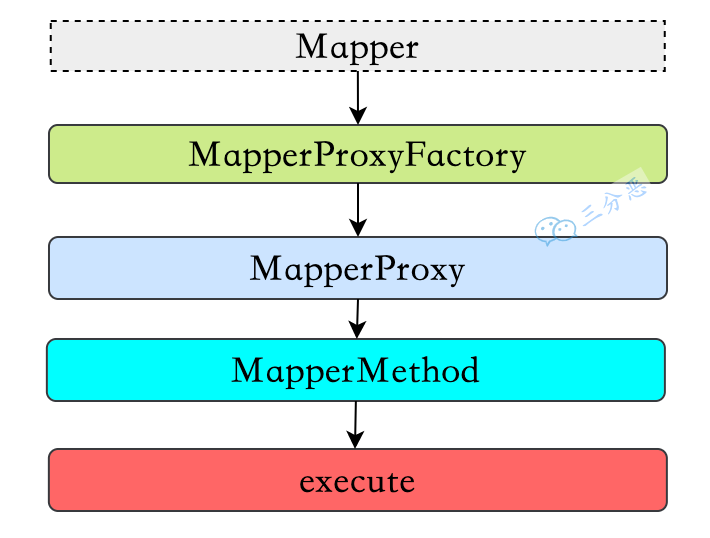
获取 Mapper:
我们都知道定义的 Mapper 接口是没有实现类的,Mapper 映射其实是通过动态代理实现的。
BlogMapper mapper = session.getMapper(BlogMapper.class);
获取 Mapper 的过程,需要先获取 MapperProxyFactory——Mapper 代理工厂。
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory)this.knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
} else {
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception var5) {
throw new BindingException("Error getting mapper instance. Cause: " + var5, var5);
}
}
}
MapperProxyFactory:
MapperProxyFactory 的作用是生成 MapperProxy(Mapper 代理对象)。
public class MapperProxyFactory<T> {
private final Class<T> mapperInterface;
……
protected T newInstance(MapperProxy<T> mapperProxy) {
return Proxy.newProxyInstance(this.mapperInterface.getClassLoader(), new Class[]{this.mapperInterface}, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
MapperProxy<T> mapperProxy = new MapperProxy(sqlSession, this.mapperInterface, this.methodCache);
return this.newInstance(mapperProxy);
}
}
这里可以看到动态代理对接口的绑定,它的作用就是生成动态代理对象(占位),而代理的方法被放到了 MapperProxy 中。
MapperProxy:
MapperProxy 里,通常会生成一个 MapperMethod 对象,它是通过 cachedMapperMethod 方法对其进行初始化的,然后执行 excute 方法。
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
return Object.class.equals(method.getDeclaringClass()) ? method.invoke(this, args) : this.cachedInvoker(method).invoke(proxy, method, args, this.sqlSession);
} catch (Throwable var5) {
throw ExceptionUtil.unwrapThrowable(var5);
}
}
MapperMethod:
MapperMethod 里的 excute 方法,会真正去执行 sql。这里用到了命令模式,其实绕一圈,最终它还是通过 SqlSession 的实例去运行对象的 sql。
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
Object param;
……
case SELECT:
if (this.method.returnsVoid() && this.method.hasResultHandler()) {
this.executeWithResultHandler(sqlSession, args);
result = null;
} else if (this.method.returnsMany()) {
result = this.executeForMany(sqlSession, args);
} else if (this.method.returnsMap()) {
result = this.executeForMap(sqlSession, args);
} else if (this.method.returnsCursor()) {
result = this.executeForCursor(sqlSession, args);
} else {
param = this.method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(this.command.getName(), param);
if (this.method.returnsOptional() && (result == null || !this.method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
……
}
18.Mybatis 都有哪些 Executor 执行器?
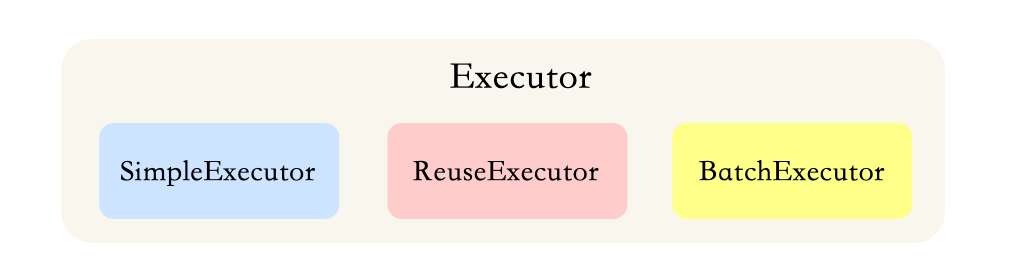
Mybatis 有三种基本的 Executor 执行器,SimpleExecutor、ReuseExecutor、BatchExecutor。
- SimpleExecutor:每执行一次 update 或 select,就开启一个 Statement 对象,用完立刻关闭 Statement 对象。
- ReuseExecutor:执行 update 或 select,以 sql 作为 key 查找 Statement 对象,存在就使用,不存在就创建,用完后,不关闭 Statement 对象,而是放置于
Map<String, Statement>内,供下一次使用。简言之,就是重复使用 Statement 对象。 - BatchExecutor:执行 update(没有 select,JDBC 批处理不支持 select),将所有 sql 都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个 Statement 对象,每个 Statement 对象都是 addBatch()完毕后,等待逐一执行 executeBatch()批处理。与 JDBC 批处理相同。
作用范围:Executor 的这些特点,都严格限制在 SqlSession 生命周期范围内。
Mybatis 中如何指定使用哪一种 Executor 执行器?
- 在 Mybatis 配置文件中,在设置(settings)可以指定默认的 ExecutorType 执行器类型,也可以手动给 DefaultSqlSessionFactory 的创建 SqlSession 的方法传递 ExecutorType 类型参数,如SqlSession openSession(ExecutorType execType)。
- 配置默认的执行器。SIMPLE 就是普通的执行器;REUSE 执行器会重用预处理语句(prepared statements); BATCH 执行器将重用语句并执行批量更新。
19.说说 Mybatis 的插件运行原理,如何编写一个插件?
插件的运行原理?
Mybatis 会话的运行需要 ParameterHandler、ResultSetHandler、StatementHandler、Executor 这四大对象的配合,插件的原理就是在这四大对象调度的时候,插入一些我我们自己的代码。
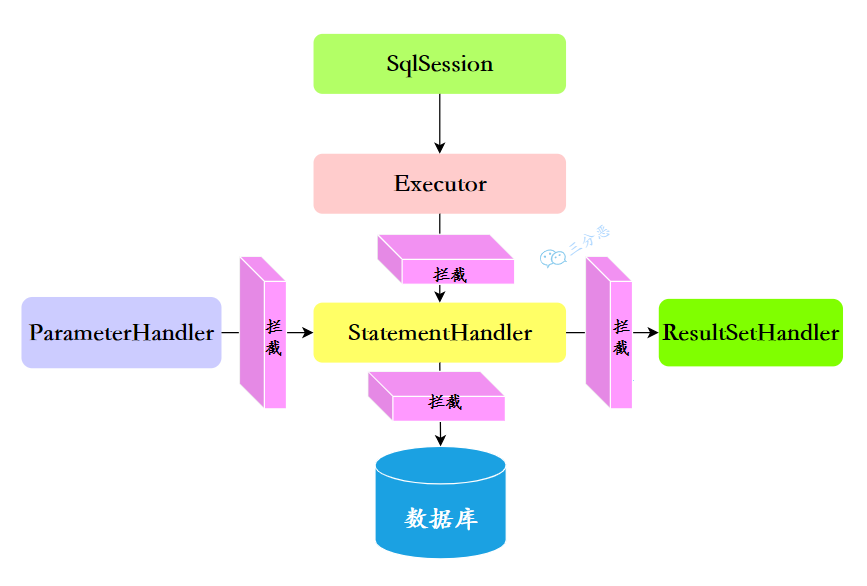
Mybatis 使用 JDK 的动态代理,为目标对象生成代理对象。它提供了一个工具类Plugin,实现了InvocationHandler接口。
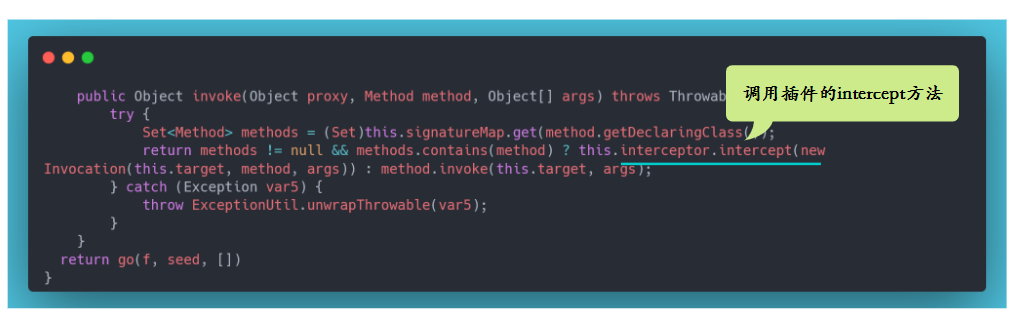
使用Plugin生成代理对象,代理对象在调用方法的时候,就会进入 invoke 方法,在 invoke 方法中,如果存在签名的拦截方法,插件的 intercept 方法就会在这里被我们调用,然后就返回结果。如果不存在签名方法,那么将直接反射调用我们要执行的方法。
如何编写一个插件?
我们自己编写 MyBatis 插件,只需要实现拦截器接口 Interceptor (org.apache.ibatis. plugin Interceptor ),在实现类中对拦截对象和方法进行处理。
实现 Mybatis 的 Interceptor 接口并重写 intercept()方法
这里我们只是在目标对象执行目标方法的前后进行了打印
public class MyInterceptor implements Interceptor {
Properties props=null;
@Override
public Object intercept(Invocation invocation) throws Throwable {
System.out.println("before……");
//如果当前代理的是一个非代理对象,那么就会调用真实拦截对象的方法
// 如果不是它就会调用下个插件代理对象的invoke方法
Object obj=invocation.proceed();
System.out.println("after……");
return obj;
}
}
然后再给插件编写注解,确定要拦截的对象,要拦截的方法
@Intercepts({@Signature(
type = Executor.class, //确定要拦截的对象
method = "update", //确定要拦截的方法
args = {MappedStatement.class,Object.class} //拦截方法的参数
)})
public class MyInterceptor implements Interceptor {
Properties props=null;
@Override
public Object intercept(Invocation invocation) throws Throwable {
System.out.println("before……");
//如果当前代理的是一个非代理对象,那么就会调用真实拦截对象的方法
// 如果不是它就会调用下个插件代理对象的invoke方法
Object obj=invocation.proceed();
System.out.println("after……");
return obj;
}
}
最后,在 MyBatis 配置文件里面配置插件
<plugins>
<plugin interceptor="xxx.MyPlugin">
<property name="dbType",value="mysql"/>
</plugin>
</plugins>
20.MyBatis 是如何进行分页的?分页插件的原理是什么?
MyBatis 是如何分页的?
MyBatis 使用 RowBounds 对象进行分页,它是针对 ResultSet 结果集执行的内存分页,而非物理分页。可以在 sql 内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的原理是什么?
- 分页插件的基本原理是使用 Mybatis 提供的插件接口,实现自定义插件,拦截 Executor 的 query 方法
- 在执行查询的时候,拦截待执行的 sql,然后重写 sql,根据 dialect 方言,添加对应的物理分页语句和物理分页参数。
- 举例:
select * from student,拦截 sql 后重写为:select t.* from (select * from student) t limit 0, 10
可以看一下一个大概的 MyBatis 通用分页拦截器:
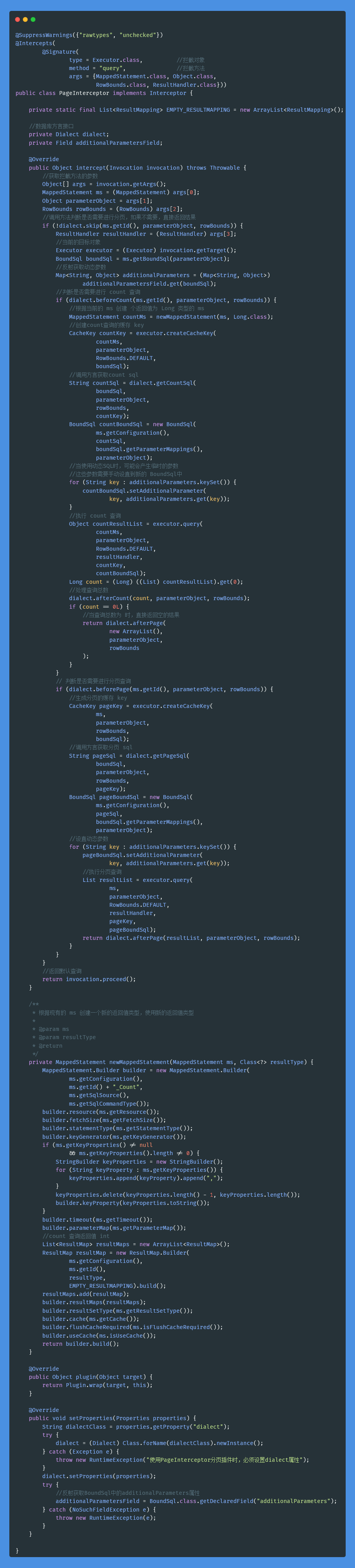
21.说说 JDBC 的执行步骤?
JDBC(Java Database Connectivity)是 Java 语言中用于连接和操作数据库的标准 API。使用 JDBC 进行数据库操作的基本步骤如下:
- 加载数据库驱动程序:
- 通过反射机制加载数据库驱动程序类。不同的数据库有不同的驱动程序。
Class.forName("com.mysql.cj.jdbc.Driver"); - 建立数据库连接:
- 使用
DriverManager类的getConnection方法建立与数据库的连接。需要提供数据库的 URL、用户名和密码。
String url = "jdbc:mysql://localhost:3306/mydatabase"; String username = "root"; String password = "password"; Connection connection = DriverManager.getConnection(url, username, password); - 使用
- 创建 Statement 对象:
- 使用
Connection对象的createStatement方法创建一个Statement对象,用于执行 SQL 语句。
Statement statement = connection.createStatement(); - 使用
- 执行 SQL 语句:
- 使用
Statement对象的executeQuery方法执行查询语句,或使用executeUpdate方法执行更新语句。
// 执行查询语句 String query = "SELECT * FROM employees"; ResultSet resultSet = statement.executeQuery(query); // 执行更新语句 String update = "UPDATE employees SET salary = 5000 WHERE id = 1"; int rowsAffected = statement.executeUpdate(update); - 使用
- 处理结果集:
- 如果执行的是查询语句,结果会返回一个
ResultSet对象。通过ResultSet对象可以遍历查询结果。
while (resultSet.next()) { int id = resultSet.getInt("id"); String name = resultSet.getString("name"); double salary = resultSet.getDouble("salary"); System.out.println("ID: " + id + ", Name: " + name + ", Salary: " + salary); } - 如果执行的是查询语句,结果会返回一个
- 关闭资源:
- 使用完数据库资源后,需要关闭
ResultSet、Statement和Connection对象,以释放资源。
resultSet.close(); statement.close(); connection.close(); - 使用完数据库资源后,需要关闭
示例代码
以下是一个完整的 JDBC 示例代码,展示了上述步骤:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class JDBCDemo {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/mydatabase";
String
username
= "root";
String password = "password";
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
// 1. 加载数据库驱动程序
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. 建立数据库连接
connection = DriverManager.getConnection(url, username, password);
// 3. 创建 Statement 对象
statement = connection.createStatement();
// 4. 执行 SQL 语句
String query = "SELECT * FROM employees";
resultSet = statement.executeQuery(query);
// 5. 处理结果集
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
double salary = resultSet.getDouble("salary");
System.out.println("ID: " + id + ", Name: " + name + ", Salary: " + salary);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
// 6. 关闭资源
if (resultSet != null) resultSet.close();
if (statement != null) statement.close();
if (connection != null) connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
总结
JDBC 的执行步骤包括加载数据库驱动程序、建立数据库连接、创建 Statement 对象、执行 SQL 语句、处理结果集和关闭资源。通过这些步骤,可以实现对数据库的基本操作。
22.创建连接拿到的是什么对象?
在 JDBC 的执行步骤中,创建连接后拿到的对象是java.sql.Connection对象。这个对象是 JDBC API 中用于表示数据库连接的接口,它提供了执行 SQL 语句、管理事务等一系列操作的方法。
Connection对象代表了应用程序和数据库的一个连接会话。
通过调用DriverManager.getConnection()方法并传入数据库的 URL、用户名和密码等信息来获得这个对象。
一旦获得Connection对象,就可以使用它来创建执行 SQL 语句的Statement、PreparedStatement和CallableStatement对象,以及管理事务等。
23.Statement 与 PreparedStatement 的区别
Statement 和 PreparedStatement 是 JDBC 中用于执行 SQL 语句的两个接口,它们有一些重要的区别:
Statement
- 用途:用于执行静态 SQL 语句。
- SQL 拼接:需要手动拼接 SQL 语句,容易导致 SQL 注入风险。
- 性能:每次执行 SQL 语句时,数据库都需要对 SQL 语句进行编译和优化,性能较低。
- 代码示例:
Statement statement = connection.createStatement();
String sql = "SELECT * FROM employees WHERE id = " + employeeId;
ResultSet resultSet = statement.executeQuery(sql);
PreparedStatement
- 用途:用于执行预编译的 SQL 语句,通常用于执行带有参数的查询。
- SQL 拼接:使用占位符(
?)来表示参数,避免了手动拼接 SQL 语句,减少了 SQL 注入风险。 - 性能:SQL 语句在执行前会被预编译,数据库可以对其进行优化,性能较高。对于重复执行的 SQL 语句,性能优势更明显。
- 参数设置:可以通过方法设置参数,类型安全。
- 代码示例:
String sql = "SELECT * FROM employees WHERE id = ?";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, employeeId);
ResultSet resultSet = preparedStatement.executeQuery();
详细对比
| 特性 | Statement |
PreparedStatement |
|---|---|---|
| SQL 拼接 | 手动拼接,容易导致 SQL 注入风险 | 使用占位符,避免 SQL 注入风险 |
| 性能 | 每次执行都需要编译和优化,性能较低 | 预编译 SQL 语句,性能较高 |
| 参数设置 | 需要手动拼接参数,容易出错 | 使用方法设置参数,类型安全 |
| 适用场景 | 适用于执行简单的、一次性的 SQL 语句 | 适用于执行带有参数的、重复执行的 SQL 语句 |
| 执行批处理 | 支持 | 支持 |
| 可读性和维护性 | 较差 | 较好 |
示例代码对比
使用 Statement
Statement statement = connection.createStatement();
String sql = "SELECT * FROM employees WHERE id = " + employeeId;
ResultSet resultSet = statement.executeQuery(sql);
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
double salary = resultSet.getDouble("salary");
System.out.println("ID: " + id + ", Name: " + name + ", Salary: " + salary);
}
使用 PreparedStatement
String sql = "SELECT * FROM employees WHERE id = ?";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, employeeId);
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
double salary = resultSet.getDouble("salary");
System.out.println("ID: " + id + ", Name: " + name + ", Salary: " + salary);
}
总结
Statement适用于执行简单的、一次性的 SQL 语句,但存在 SQL 注入风险,性能较低。PreparedStatement适用于执行带有参数的、重复执行的 SQL 语句,避免了 SQL 注入风险,性能较高,且代码可读性和维护性更好。
24.什么是 SQL 注入?如何防止 SQL 注入?
SQL 注入是一种代码注入技术,通过在输入字段中插入专用的 SQL 语句,从而欺骗数据库执行恶意 SQL,从而获取敏感数据、修改数据,或者删除数据等。
比如说有这样一段代码:
studentId = getRequestString("studentId");
lookupStudent = "SELECT * FROM students WHERE studentId = " + studentId
用户在输入框中输入 117 进行查询:
实际的 SQL 语句类似于:
SELECT * FROM students WHERE studentId = 117
这是我们期望用户输入的正确方式。但是,如果用户输入了117 OR 1=1,那么 SQL 语句就变成了:
SELECT * FROM students WHERE studentId = 117 OR 1=1
由于1=1为真,所以这个查询将返回所有学生的信息,而不仅仅是 ID 为 117 的学生。
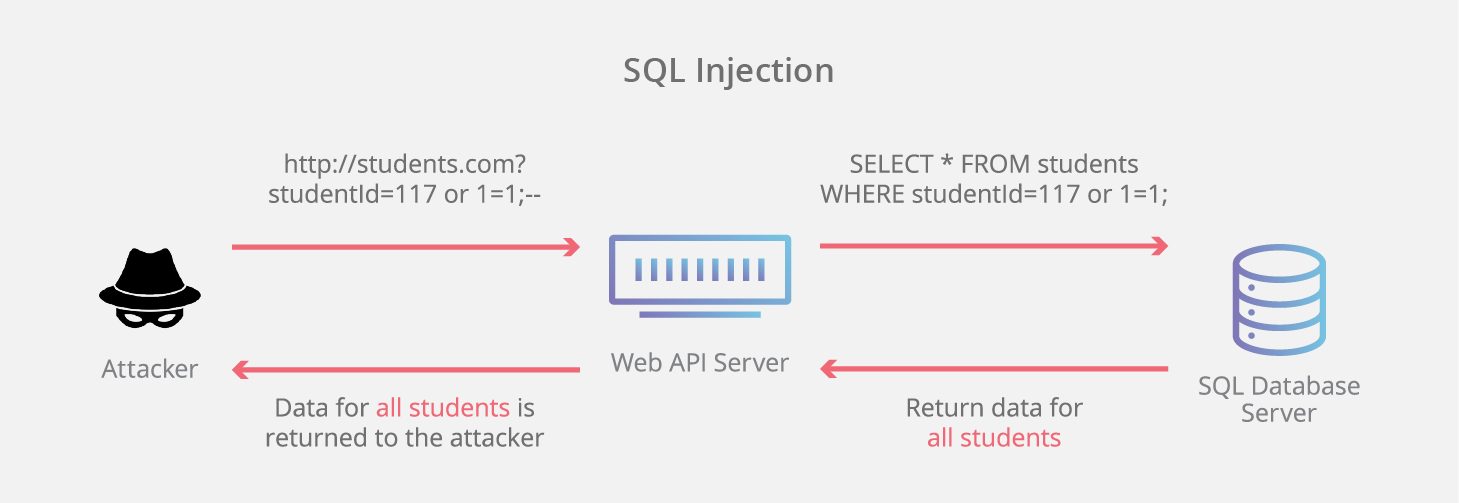
为了防止 SQL 注入,可以采取以下措施:
①、使用参数化查询
使用参数化查询,即使用PreparedStatement对象,通过setXxx方法设置参数值,而不是通过字符串拼接 SQL 语句。这样可以有效防止 SQL 注入。
String query = "SELECT * FROM users WHERE username = ?";
PreparedStatement pstmt = connection.prepareStatement(query);
pstmt.setString(1, userName); // userName 是用户输入
ResultSet rs = pstmt.executeQuery();
? 是一个参数占位符,userName 是外部输入。这样即便用户输入了恶意的 SQL 语句,也只会被视为参数的一部分,不会改变查询的结构。
②、限制用户输入
对用户输入进行验证和过滤,只允许输入预期的数据,不允许输入特殊字符或 SQL 关键字。
③、使用 ORM 框架
比如,在 MyBatis 中,使用#{}占位符来代替直接拼接 SQL 语句,MyBatis 会自动进行参数化处理。
<select id="selectUser" resultType="User">
SELECT * FROM users WHERE username = #{userName}
</select>
假如 userName 传入的值是 9;DROP TABLE SYS_USER;,传入的删除表 SQL 也不会执行,因为它会被当作参数值。
SELECT * FROM users WHERE username = '9;DROP TABLE SYS_USER;'
MySQL
1.MySQL 的内连接、左连接、右连接有什么区别?
①、inner join 内连接,在两张表进行连接查询时,只保留两张表中完全匹配的结果集。
只有当两个表中都有匹配的记录时,这些记录才会出现在查询结果中。如果某一方没有匹配的记录,则该记录不会出现在结果集中。
内联可以用来找出两个表中共同的记录,相当于两个数据集的交集。
②、left join 返回左表(FROM 子句中指定的表)的所有记录,以及右表中匹配记录的记录。如果右表中没有匹配的记录,则结果中右表的部分会以 NULL 填充。
③、right join 刚好与左联相反,返回右表(FROM 子句中指定的表)的所有记录,以及左表中匹配记录的记录。如果左表中没有匹配的记录,则结果中左表的部分会以 NULL 填充。
2.什么是三大范式,为什么要有三大范式,什么场景下不用遵循三大范式,举一个场景?
什么是三大范式?
数据库设计中的三大范式是指关系数据库的设计原则,用于减少数据冗余和提高数据一致性。三大范式分别是第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。
第一范式(1NF)
第一范式要求数据库表中的每一列都是原子性的,即每一列的数据都是不可再分的基本数据项。
示例:
| 学生ID | 姓名 | 电话号码 |
|---|---|---|
| 1 | 张三 | 1234567890 |
| 2 | 李四 | 0987654321 |
第二范式(2NF)
第二范式在满足第一范式的基础上,要求表中的每个非主键列都完全依赖于主键,而不能依赖于主键的一部分(消除部分依赖)。
示例:
将学生信息和课程信息分开存储:
学生表:
| 学生ID | 姓名 |
|---|---|
| 1 | 张三 |
| 2 | 李四 |
课程表:
| 课程ID | 课程名 |
|---|---|
| 101 | 数学 |
| 102 | 英语 |
选课表:
| 学生ID | 课程ID |
|---|---|
| 1 | 101 |
| 2 | 102 |
第三范式(3NF)
第三范式在满足第二范式的基础上,要求表中的每个非主键列都直接依赖于主键,而不能依赖于其他非主键列(消除传递依赖)。
示例:
将学生信息和班级信息分开存储:
学生表:
| 学生ID | 姓名 | 班级ID |
|---|---|---|
| 1 | 张三 | 1 |
| 2 | 李四 | 2 |
班级表:
| 班级ID | 班级名 |
|---|---|
| 1 | 一班 |
| 2 | 二班 |
为什么要有三大范式?
三大范式的主要目的是减少数据冗余、提高数据一致性和完整性。通过遵循三大范式,可以避免数据的重复存储和更新异常,从而提高数据库的设计质量和维护效率。
什么场景下不用遵循三大范式?
在某些特定场景下,为了提高查询性能或简化数据操作,可以适当放宽对三大范式的遵循。这种情况通常发生在数据量较大且查询频繁的场景中。
举一个场景
假设有一个电商系统,需要频繁查询订单及其对应的用户信息。为了提高查询性能,可以将订单信息和用户信息存储在同一个表中,而不是严格遵循第三范式将其分开存储。
示例:
订单表:
| 订单ID | 用户ID | 用户名 | 用户地址 | 商品ID | 商品名 | 订单金额 |
|---|---|---|---|---|---|---|
| 1 | 101 | 张三 | 北京市朝阳区 | 1001 | 手机 | 3000 |
| 2 | 102 | 李四 | 上海市浦东新区 | 1002 | 电脑 | 5000 |
在这个例子中,用户信息(用户名、用户地址)被重复存储在每个订单记录中,违反了第三范式的要求,但这样可以减少查询时的表连接操作,提高查询性能。
总结
三大范式是数据库设计的重要原则,用于减少数据冗余和提高数据一致性。然而,在某些特定场景下,为了提高查询性能或简化数据操作,可以适当放宽对三大范式的遵循。
3.varchar 与 char 的区别?
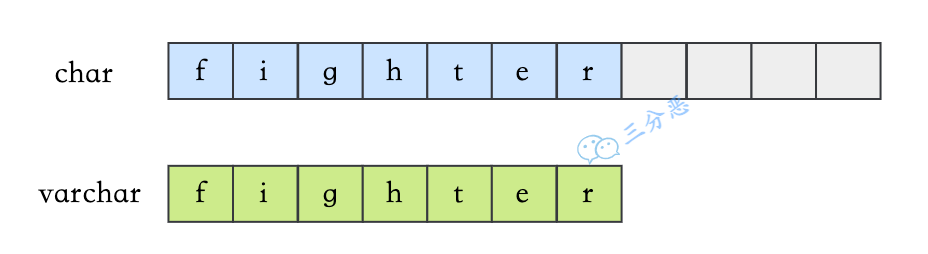
char:
- char 表示定长字符串,长度是固定的;
- 如果插入数据的长度小于 char 的固定长度时,则用空格填充;
- 因为长度固定,所以存取速度要比 varchar 快很多,甚至能快 50%,但正因为其长度固定,所以会占据多余的空间,是空间换时间的做法;
- 对于 char 来说,最多能存放的字符个数为 255,和编码无关
varchar:
- varchar 表示可变长字符串,长度是可变的;
- 插入的数据是多长,就按照多长来存储;
- varchar 在存取方面与 char 相反,它存取慢,因为长度不固定,但正因如此,不占据多余的空间,是时间换空间的做法;
- 对于 varchar 来说,最多能存放的字符个数为 65532
日常的设计,对于长度相对固定的字符串,可以使用 char,对于长度不确定的,使用 varchar 更合适一些。
4.blob 和 text 有什么区别?
- blob 用于存储二进制数据,而 text 用于存储大字符串。
- blob 没有字符集,text 有一个字符集,并且根据字符集的校对规则对值进行排序和比较
5.DATETIME 和 TIMESTAMP 的异同?
相同点:
- 两个数据类型存储时间的表现格式一致。均为
YYYY-MM-DD HH:MM:SS - 两个数据类型都包含「日期」和「时间」部分。
- 两个数据类型都可以存储微秒的小数秒(秒后 6 位小数秒)
区别:
DATETIME 和 TIMESTAMP 的区别
- 日期范围:DATETIME 的日期范围是
1000-01-01 00:00:00.000000到9999-12-31 23:59:59.999999;TIMESTAMP 的时间范围是1970-01-01 00:00:01.000000UTC到2038-01-09 03:14:07.999999UTC - 存储空间:DATETIME 的存储空间为 8 字节;TIMESTAMP 的存储空间为 4 字节
- 时区相关:DATETIME 存储时间与时区无关;TIMESTAMP 存储时间与时区有关,显示的值也依赖于时区
- 默认值:DATETIME 的默认值为 null;TIMESTAMP 的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP)
6.MySQL 中 in 和 exists 的区别?
MySQL 中的 in 语句是把外表和内表作 hash 连接,而 exists 语句是对外表作 loop 循环,每次 loop 循环再对内表进行查询。我们可能认为 exists 比 in 语句的效率要高,这种说法其实是不准确的,要区分情景:
- 如果查询的两个表大小相当,那么用 in 和 exists 差别不大。
- 如果两个表中一个较小,一个是大表,则子查询表大的用 exists,子查询表小的用 in。
- not in 和 not exists:如果查询语句使用了 not in,那么内外表都进行全表扫描,没有用到索引;而 not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用 not exists 都比 not in 要快。
7.MySQL 里记录货币用什么字段类型比较好?
货币在数据库中 MySQL 常用 Decimal 和 Numeric 类型表示,这两种类型被 MySQL 实现为同样的类型。他们被用于保存与货币有关的数据。
例如 salary DECIMAL(9,2),9(precision)代表将被用于存储值的总的小数位数,而 2(scale)代表将被用于存储小数点后的位数。存储在 salary 列中的值的范围是从-9999999.99 到 9999999.99。
DECIMAL 和 NUMERIC 值作为字符串存储,而不是作为二进制浮点数,以便保存那些值的小数精度。
之所以不使用 float 或者 double 的原因:因为 float 和 double 是以二进制存储的,所以有一定的误差。
8.MySQL 怎么存储 emoji?
MySQL 的 utf8 字符集仅支持最多 3 个字节的 UTF-8 字符,但是 emoji 表情(😊)是 4 个字节的 UTF-8 字符,所以在 MySQL 中存储 emoji 表情时,需要使用 utf8mb4 字符集。
ALTER TABLE mytable CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
MySQL 8.0 已经默认支持 utf8mb4 字符集,可以通过 SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE 'collation%'; 查看。
9.drop、delete 与 truncate 的区别?
三者都表示删除,但是三者有一些差别:
| 区别 | delete | truncate | drop |
|---|---|---|---|
| 类型 | 属于 DML | 属于 DDL | 属于 DDL |
| 回滚 | 可回滚 | 不可回滚 | 不可回滚 |
| 删除内容 | 表结构还在,删除表的全部或者一部分数据行 | 表结构还在,删除表中的所有数据 | 从数据库中删除表,所有数据行,索引和权限也会被删除 |
| 删除速度 | 删除速度慢,需要逐行删除 | 删除速度快 | 删除速度最快 |
因此,在不再需要一张表的时候,用 drop;在想删除部分数据行时候,用 delete;在保留表而删除所有数据的时候用 truncate。
10.UNION 与 UNION ALL 的区别?
- 如果使用 UNION,会在表链接后筛选掉重复的记录行
- 如果使用 UNION ALL,不会合并重复的记录行
- 从效率上说,UNION ALL 要比 UNION 快很多,如果合并没有刻意要删除重复行,那么就使用 UNION All
11.count(1)、count(*) 与 count(列名) 的区别?
执行效果:
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为 NULL
- count(1)包括了忽略所有列,用 1 代表代码行,在统计结果的时候,不会忽略列值为 NULL
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是指空字符串或者 0,而是表示 null)的计数,即某个字段值为 NULL 时,不统计。
执行速度:
- 列名为主键,count(列名)会比 count(1)快
- 列名不为主键,count(1)会比 count(列名)快
- 如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*)
- 如果有主键,则 select count(主键)的执行效率是最优的
- 如果表只有一个字段,则 select count(*)最优。
12.一条 SQL 查询语句的执行顺序?

- FROM:对 FROM 子句中的左表<left_table>和右表<right_table>执行笛卡儿积(Cartesianproduct),产生虚拟表 VT1
- ON:对虚拟表 VT1 应用 ON 筛选,只有那些符合<join_condition>的行才被插入虚拟表 VT2 中
- JOIN:如果指定了 OUTER JOIN(如 LEFT OUTER JOIN、RIGHT OUTER JOIN),那么保留表中未匹配的行作为外部行添加到虚拟表 VT2 中,产生虚拟表 VT3。如果 FROM 子句包含两个以上表,则对上一个连接生成的结果表 VT3 和下一个表重复执行步骤 1)~步骤 3),直到处理完所有的表为止
- WHERE:对虚拟表 VT3 应用 WHERE 过滤条件,只有符合<where_condition>的记录才被插入虚拟表 VT4 中
- GROUP BY:根据 GROUP BY 子句中的列,对 VT4 中的记录进行分组操作,产生 VT5
-
**CUBE ROLLUP**:对表 VT5 进行 CUBE 或 ROLLUP 操作,产生表 VT6 - HAVING:对虚拟表 VT6 应用 HAVING 过滤器,只有符合<having_condition>的记录才被插入虚拟表 VT7 中。
- SELECT:第二次执行 SELECT 操作,选择指定的列,插入到虚拟表 VT8 中
- DISTINCT:去除重复数据,产生虚拟表 VT9
- ORDER BY:将虚拟表 VT9 中的记录按照<order_by_list>进行排序操作,产生虚拟表 VT10。11)
- LIMIT:取出指定行的记录,产生虚拟表 VT11,并返回给查询用户
13.介绍一下 MySQL 的常用命令
MySQL 是一个广泛使用的关系数据库管理系统,提供了许多命令来管理数据库和数据。以下是一些常用的 MySQL 命令:
数据库操作命令
创建数据库
CREATE DATABASE database_name;
删除数据库
DROP DATABASE database_name;
选择数据库
USE database_name;
表操作命令
创建表
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...
);
删除表
DROP TABLE table_name;
修改表
- 添加列
ALTER TABLE table_name ADD column_name datatype;
- 删除列
ALTER TABLE table_name DROP COLUMN column_name;
- 修改列
ALTER TABLE table_name MODIFY COLUMN column_name datatype;
数据操作命令
插入数据
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);
更新数据
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;
删除数据
DELETE FROM table_name WHERE condition;
查询数据
SELECT column1, column2, ... FROM table_name WHERE condition;
用户和权限管理命令
创建用户
CREATE USER 'username'@'host' IDENTIFIED BY 'password';
删除用户
DROP USER 'username'@'host';
授予权限
GRANT ALL PRIVILEGES ON database_name.* TO 'username'@'host';
撤销权限
REVOKE ALL PRIVILEGES ON database_name.* FROM 'username'@'host';
刷新权限
FLUSH PRIVILEGES;
备份和恢复命令
备份数据库
mysqldump -u username -p database_name > backup_file.sql
恢复数据库
mysql -u username -p database_name < backup_file.sql
查看和管理命令
查看数据库
SHOW DATABASES;
查看表
SHOW TABLES;
查看表结构
DESCRIBE table_name;
查看当前用户
SELECT USER();
查看当前数据库
SELECT DATABASE();
事务管理命令
开始事务
START TRANSACTION;
提交事务
COMMIT;
回滚事务
ROLLBACK;
总结
这些是 MySQL 中一些常用的命令,涵盖了数据库和表的创建、修改、删除,数据的插入、更新、删除,用户和权限管理,以及备份和恢复等操作。通过熟练掌握这些命令,可以有效地管理和操作 MySQL 数据库。
14.介绍一下 MySQL bin 目录下的可执行文件
- mysql:客户端程序,用于连接 MySQL 服务器
- mysqldump:一个非常实用的 MySQL 数据库备份工具,用于创建一个或多个 MySQL 数据库级别的 SQL 转储文件,包括数据库的表结构和数据。对数据备份、迁移或恢复非常重要。
- mysqladmin:mysql 后面加上 admin 就表明这是一个 MySQL 的管理工具,它可以用来执行一些管理操作,比如说创建数据库、删除数据库、查看 MySQL 服务器的状态等。
- mysqlcheck:mysqlcheck 是 MySQL 提供的一个命令行工具,用于检查、修复、分析和优化数据库表,对数据库的维护和性能优化非常有用。
- mysqlimport:用于从文本文件中导入数据到数据库表中,非常适合用于批量导入数据。
- mysqlshow:用于显示 MySQL 数据库服务器中的数据库、表、列等信息。
- mysqlbinlog:用于查看 MySQL 二进制日志文件的内容,可以用于恢复数据、查看数据变更等。
15.MySQL 第 3-10 条记录怎么查?
在 MySQL 中,要查询第 3 到第 10 条记录,可以使用 limit 语句,结合偏移量 offset 和行数 row_count 来实现。
limit 语句用于限制查询结果的数量,偏移量表示从哪条记录开始,行数表示返回的记录数量。
SELECT * FROM table_name LIMIT 2, 8;
- 2:偏移量,表示跳过前两条记录,从第三条记录开始。
- 8:行数,表示从偏移量开始,返回 8 条记录。
偏移量是从 0 开始的,即第一条记录的偏移量是 0;如果想从第 3 条记录开始,偏移量就应该是 2。
16.用过哪些 MySQL 函数?
在 MySQL 中,有许多内置函数可以用于各种数据操作和查询。以下是一些常用的 MySQL 函数:
字符串函数
CONCAT:连接两个或多个字符串。
SELECT CONCAT('Hello', ' ', 'World');
SUBSTRING:从字符串中提取子字符串。
SELECT SUBSTRING('Hello World', 1, 5);
LENGTH:返回字符串的长度。
SELECT LENGTH('Hello World');
UPPER:将字符串转换为大写。
SELECT UPPER('hello world');
LOWER:将字符串转换为小写。
SELECT LOWER('HELLO WORLD');
数值函数
ABS:返回数值的绝对值。
SELECT ABS(-10);
ROUND:对数值进行四舍五入。
SELECT ROUND(123.456, 2);
CEIL:返回大于或等于指定数值的最小整数。
SELECT CEIL(123.456);
FLOOR:返回小于或等于指定数值的最大整数。
SELECT FLOOR(123.456);
MOD:返回两个数值相除的余数。
SELECT MOD(10, 3);
日期和时间函数
NOW:返回当前日期和时间。
SELECT NOW();
CURDATE:返回当前日期。
SELECT CURDATE();
CURTIME:返回当前时间。
SELECT CURTIME();
DATE_ADD:向日期添加指定的时间间隔。
SELECT DATE_ADD('2023-01-01', INTERVAL 1 DAY);
DATEDIFF:返回两个日期之间的天数差。
SELECT DATEDIFF('2023-01-10', '2023-01-01');
聚合函数
COUNT:返回结果集中的行数。
SELECT COUNT(*) FROM employees;
SUM:返回数值列的总和。
SELECT SUM(salary) FROM employees;
AVG:返回数值列的平均值。
SELECT AVG(salary) FROM employees;
MAX:返回数值列的最大值。
SELECT MAX(salary) FROM employees;
MIN:返回数值列的最小值。
SELECT MIN(salary) FROM employees;
条件函数
IF:返回条件为真的值,否则返回条件为假的值。
SELECT IF(salary > 5000, 'High', 'Low') FROM employees;
CASE:类似于 IF,但可以处理多个条件。
SELECT
CASE
WHEN salary > 5000 THEN 'High'
WHEN salary > 3000 THEN 'Medium'
ELSE 'Low'
END AS salary_level
FROM employees;
JSON 函数
JSON_EXTRACT:从 JSON 文档中提取数据。
SELECT JSON_EXTRACT('{"name": "John", "age": 30}', '$.name');
JSON_ARRAY:创建 JSON 数组。
SELECT JSON_ARRAY('apple', 'banana', 'cherry');
JSON_OBJECT:创建 JSON 对象。
SELECT JSON_OBJECT('name', 'John', 'age', 30);
类型转换函数
CAST: 将一个值转换为指定的数据类型。
SELECT CAST('2024-01-01' AS DATE) AS casted_date;
CANVERT: 类似于CAST(),用于类型转换。
SELECT CONVERT('123', SIGNED INTEGER) AS converted_number;
17.说说 SQL 的隐式数据类型转换?
在 SQL 中,当不同数据类型的值进行运算或比较时,会发生隐式数据类型转换。
比如说,当一个整数和一个浮点数相加时,整数会被转换为浮点数,然后再进行相加。
SELECT 1 + 1.0; -- 结果为 2.0
比如说,当一个字符串和一个整数相加时,字符串会被转换为整数,然后再进行相加。
SELECT '1' + 1; -- 结果为 2
数据类型隐式转换会导致意想不到的结果,所以要尽量避免隐式转换。
可以通过显式转换来规避这种情况。
SELECT CAST('1' AS SIGNED INTEGER) + 1; -- 结果为 2
18.说说 MySQL 的基础架构?
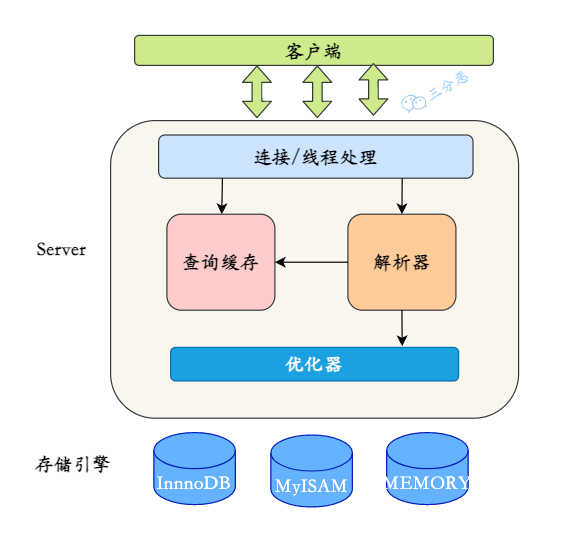
MySQL 逻辑架构图主要分三层:
- 客户端:最上层的服务并不是 MySQL 所独有的,大多数基于网络的客户端/服务器的工具或者服务都有类似的架构。比如连接处理、授权认证、安全等等。
- Server 层:大多数 MySQL 的核心服务功能都在这一层,包括查询解析、分析、优化、缓存以及所有的内置函数(例如,日期、时间、数学和加密函数),所有跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。
- 存储引擎层:第三层包含了存储引擎。存储引擎负责 MySQL 中数据的存储和提取。Server 层通过 API 与存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明。
19.一条 SQL 查询语句在 MySQL 中如何执行的?
在 MySQL 中,一条 SQL 查询语句的执行过程可以分为多个步骤。以下是一个典型的 SQL 查询语句在 MySQL 中的执行过程:
1. 客户端发送查询请求
客户端通过连接器(Connector)向 MySQL 服务器发送查询请求。
2. 连接处理
MySQL 服务器接收到查询请求后,首先会进行连接处理,包括用户身份验证和权限检查。通过身份验证和权限检查后,服务器会为该连接分配一个线程。
3. 查询缓存
MySQL 会检查查询缓存(Query Cache),如果查询缓存中存在相同的查询且缓存未失效,则直接返回缓存结果。否则,继续执行下一步。
4. 解析器
解析器(Parser)会对 SQL 语句进行词法分析和语法分析,生成解析树(Parse Tree)。解析器会检查 SQL 语句的语法是否正确,并将其转换为内部数据结构。
5. 预处理器
预处理器(Preprocessor)会进一步检查解析树,包括检查表和列是否存在,检查用户是否有权限访问这些表和列等。
6. 查询优化器
查询优化器(Optimizer)会对解析树进行优化,生成执行计划(Execution Plan)。优化器会选择最优的执行路径,包括选择合适的索引、确定表的连接顺序等。
7. 执行器
执行器(Executor)根据执行计划执行查询操作。执行器会调用存储引擎接口,逐步获取数据并进行处理。
8. 存储引擎
存储引擎(Storage Engine)负责实际的数据存储和提取。MySQL 支持多种存储引擎,如 InnoDB、MyISAM 等。存储引擎通过 API 与 Server 层进行通信,执行器会根据执行计划向存储引擎发出请求,存储引擎返回数据。
9. 返回结果
执行器将查询结果返回给客户端。
执行过程解析
- 客户端发送查询请求:客户端向 MySQL 服务器发送查询请求。
- 连接处理:MySQL 服务器进行用户身份验证和权限检查,通过后分配一个线程处理该请求。
- 查询缓存:检查查询缓存,如果缓存中存在相同的查询且未失效,则直接返回缓存结果。
- 解析器:解析器对 SQL 语句进行词法分析和语法分析,生成解析树。
- 预处理器:预处理器检查解析树,验证表和列是否存在,检查用户权限。
- 查询优化器:查询优化器对解析树进行优化,生成执行计划,选择最优的执行路径。
- 执行器:执行器根据执行计划执行查询操作,调用存储引擎接口获取数据。
- 存储引擎:存储引擎执行实际的数据存储和提取操作,返回数据给执行器。
- 返回结果:执行器将查询结果返回给客户端。
20.说说 MySQL 的数据存储形式
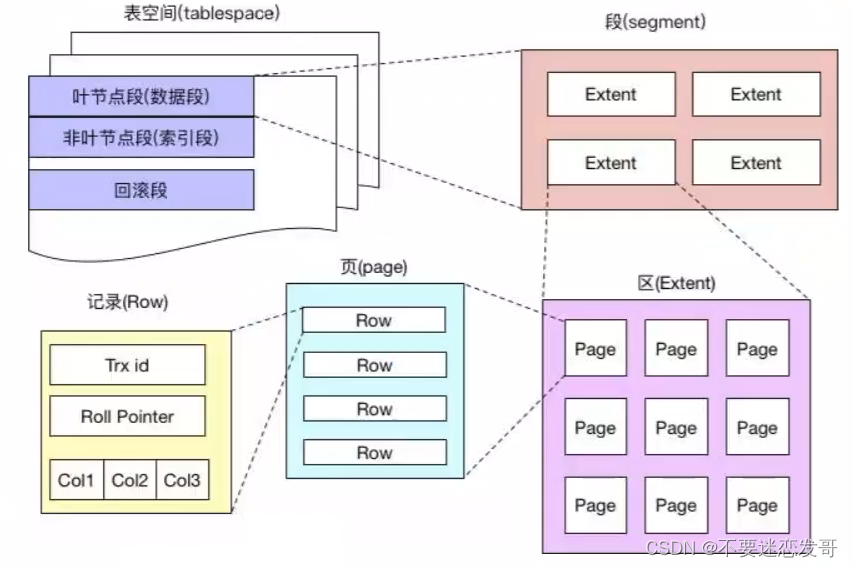
①、段(Segment):表空间由多个段组成,常见的段有数据段、索引段、回滚段等。
创建索引时会创建两个段,数据段和索引段,数据段用来存储叶子阶段中的数据;索引段用来存储非叶子节点的数据。
回滚段包含了事务执行过程中用于数据回滚的旧数据。
②、区(Extent):段由一个或多个区组成,区是一组连续的页,通常包含 64 个连续的页,也就是 1M 的数据。
使用区而非单独的页进行数据分配可以优化磁盘操作,减少磁盘寻道时间,特别是在大量数据进行读写时。
③、页(Page):页是 InnoDB 存储数据的基本单元,标准大小为 16 KB,索引树上的一个节点就是一个页。
也就意味着数据库每次读写都是以 16 KB 为单位的,一次最少从磁盘中读取 16KB 的数据到内存,一次最少写入 16KB 的数据到磁盘。
④、行(Row):InnoDB 采用行存储方式,意味着数据按照行进行组织和管理,行数据可能有多个格式,比如说 COMPACT、REDUNDANT、DYNAMIC 等。
MySQL 8.0 默认的行格式是 DYNAMIC,由COMPACT 演变而来,意味着这些数据如果超过了页内联存储的限制,则会被存储在溢出页中。
可以通过 show table status like '%article%' 查看行格式。
21.MySQL 有哪些常见存储引擎?
MySQL 支持多种存储引擎,常见的有 MyISAM、InnoDB、MEMORY 等。MEMORY 并不常用。
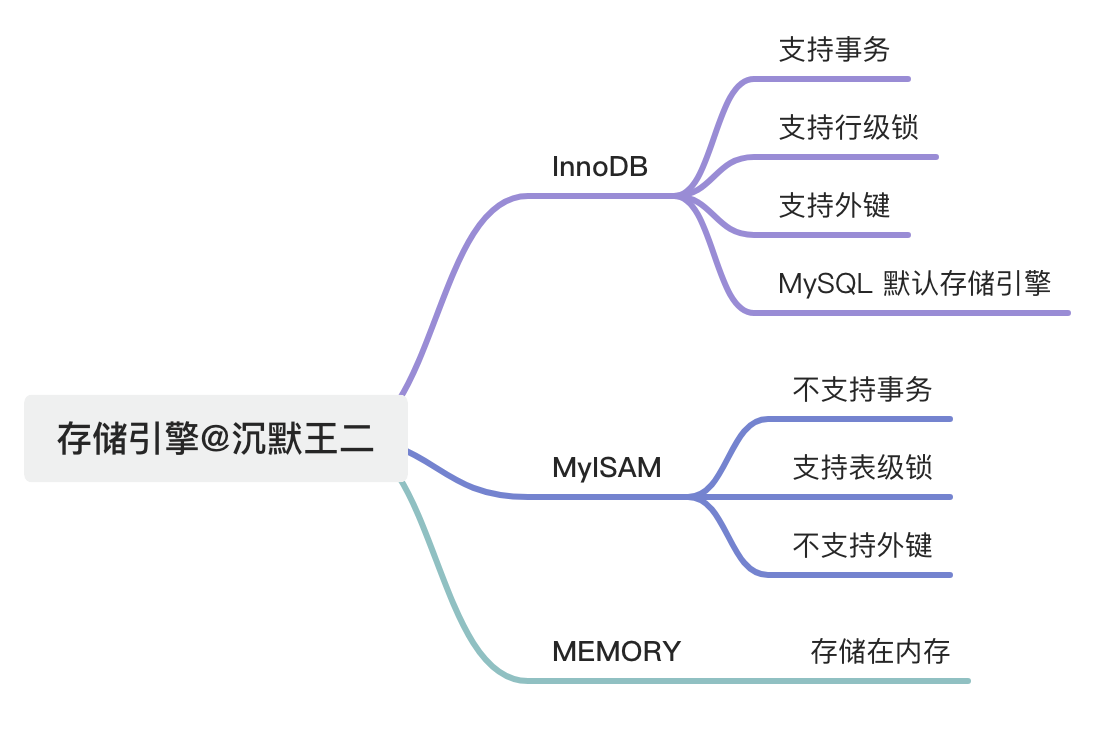
| 功能 | InnoDB | MyISAM | MEMORY |
|---|---|---|---|
| 支持事务 | Yes | No | No |
| 支持全文索引 | Yes | Yes | No |
| 支持 B+树索引 | Yes | Yes | Yes |
| 支持哈希索引 | Yes | No | Yes |
| 支持外键 | Yes | No | No |
除此之外,我还了解到:
①、MySQL 5.5 之前,默认存储引擎是 MyISAM,5.5 之后是 InnoDB。
②、InnoDB 支持的哈希索引是自适应的,不能人为干预。
③、InnoDB 从 MySQL 5.6 开始,支持全文索引。
④、InnoDB 的最小表空间略小于 10M,最大表空间取决于页面大小(page size)。
如何切换 MySQL 的数据引擎?
可以通过 alter table 语句来切换 MySQL 的数据引擎。
ALTER TABLE your_table_name ENGINE=InnoDB;
不过不建议,应该提前设计好到底用哪一种存储引擎。
22.存储引擎应该怎么选择?
- 大多数情况下,使用默认的 InnoDB 就对了,InnoDB 可以提供事务、行级锁等能力。
- MyISAM 适合读更多的场景。
- MEMORY 适合临时表,数据量不大的情况。由于数据都存放在内存,所以速度非常快。
23.InnoDB 和 MyISAM 主要有什么区别?
InnoDB 和 MyISAM 之间的区别主要表现在存储结构、事务支持、最小锁粒度、索引类型、主键必需、表的具体行数、外键支持等方面。
①、存储结构:
- MyISAM:用三种格式的文件来存储,.frm 文件存储表的定义;.MYD 存储数据;.MYI 存储索引。
- InnoDB:用两种格式的文件来存储,.frm 文件存储表的定义;.ibd 存储数据和索引。
②、事务支持:
- MyISAM:不支持事务。
- InnoDB:支持事务。
③、最小锁粒度:
- MyISAM:表级锁,高并发中写操作存在性能瓶颈。
- InnoDB:行级锁,并发写入性能高。
④、索引类型:
MyISAM 为非聚簇索引,索引和数据分开存储,索引保存的是数据文件的指针。
InnoDB 为聚簇索引,索引和数据不分开。
⑤、外键支持:MyISAM 不支持外键;InnoDB 支持外键。
⑥、主键必需:MyISAM 表可以没有主键;InnoDB 表必须有主键。
⑦、表的具体行数:MyISAM 表的具体行数存储在表的属性中,查询时直接返回;InnoDB 表的具体行数需要扫描整个表才能返回。
24.MySQL 日志文件有哪些?分别介绍下作用?
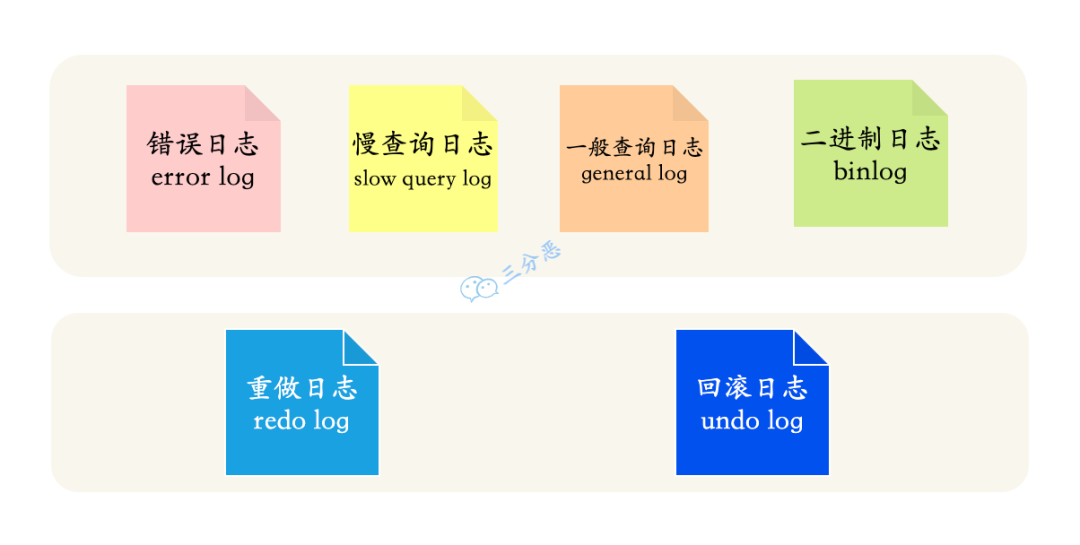
MySQL 的日志文件主要包括:
①、错误日志(Error Log):记录 MySQL 服务器启动、运行或停止时出现的问题。
②、慢查询日志(Slow Query Log):记录执行时间超过 long_query_time 值的所有 SQL 语句。这个时间值是可配置的,默认情况下,慢查询日志功能是关闭的。可以用来识别和优化慢 SQL。
③、一般查询日志(General Query Log):记录所有 MySQL 服务器的连接信息及所有的 SQL 语句,不论这些语句是否修改了数据。
④、二进制日志(Binary Log):记录了所有修改数据库状态的 SQL 语句,以及每个语句的执行时间,如 INSERT、UPDATE、DELETE 等,但不包括 SELECT 和 SHOW 这类的操作。
⑤、重做日志(Redo Log):记录了对于 InnoDB 表的每个写操作,不是 SQL 级别的,而是物理级别的,主要用于崩溃恢复。
⑥、回滚日志(Undo Log,或者叫事务日志):记录数据被修改前的值,用于事务的回滚。
请重点说说 binlog?
binlog 是一种物理日志,会在磁盘上记录下数据库的所有修改操作,以便进行数据恢复和主从复制。
- 当发生数据丢失时,binlog 可以将数据库恢复到特定的时间点。
- 主服务器(master)上的二进制日志可以被从服务器(slave)读取,从而实现数据同步。
binlog 包括两类文件:
- 二进制索引文件(.index)
- 二进制日志文件(.00000*)
binlog 默认是没有启用的。要启用它,需要在 MySQL 的配置文件(my.cnf 或 my.ini)中设置 log_bin 参数。
log_bin = mysql-bin //开启binlog
mysql-bin.*日志文件最大字节(单位:字节)
设置最大100MB
max_binlog_size=104857600
设置了只保留7天BINLOG(单位:天)
expire_logs_days = 7
binlog日志只记录指定库的更新
binlog-do-db=db_name
binlog日志不记录指定库的更新
binlog-ignore-db=db_name
写缓冲多少次,刷一次磁盘,默认0
sync_binlog=0
简单说一下这里面参数的作用:
①、log_bin = mysql-bin,启用 binlog,这样就可以在 MySQL 的数据目录中找到 db-bin.000001、db-bin.000002 等日志文件。
②、max_binlog_size=104857600
设置每个 binlog 文件的最大大小为 100MB(104857600 字节)。当 binlog 文件达到这个大小时,MySQL 会关闭当前文件并创建一个新的 binlog 文件。
③、expire_logs_days = 7
这条配置设置了 binlog 文件的自动过期时间为 7 天。过期的 binlog 文件将被自动删除。这有助于管理磁盘空间,防止长时间累积的 binlog 文件占用过多存储空间。
④、binlog-do-db=db_name
指定哪些数据库表的更新应该被记录。
⑤、binlog-ignore-db=db_name
指定忽略哪些数据库表的更新。
⑥、sync_binlog=0
这条配置设置了每多少次 binlog 写操作会触发一次磁盘同步操作。默认值 0 表示 MySQL 不会主动触发同步操作,而是依赖操作系统的磁盘缓存策略。
即当执行写操作时,数据会先写入操作系统的缓存,当缓存区满了再由操作系统将数据写入磁盘。
设置为 1 意味着每次 binlog 写操作后都会同步到磁盘,这可以提高数据安全性,但可能会对性能产生影响。
可以通过 show variables like '%log_bin%'; 查看 binlog 是否开启。
25.binlog 和 redo log 有什么区别?
binlog,即二进制日志,对所有存储引擎都可用,是 MySQL 服务器级别的日志,用于数据的复制、恢复和备份。而 redo log 主要用于保证事务的持久性,是 InnoDB 存储引擎特有的日志类型。
binlog 记录的是逻辑 SQL 语句,而 redo log 记录的是物理数据页的修改操作,不是具体的 SQL 语句。
redo log 是固定大小的,通常配置为一组文件,使用环形方式写入,旧的日志会在空间需要时被覆盖。binlog 是追加写入的,新的事件总是被添加到当前日志文件的末尾,当文件达到一定大小后,会创建新的 binlog 文件继续记录。
26.一条更新语句怎么执行的了解吗?
更新语句的执行是 Server 层和引擎层配合完成,数据除了要写入表中,还要记录相应的日志。
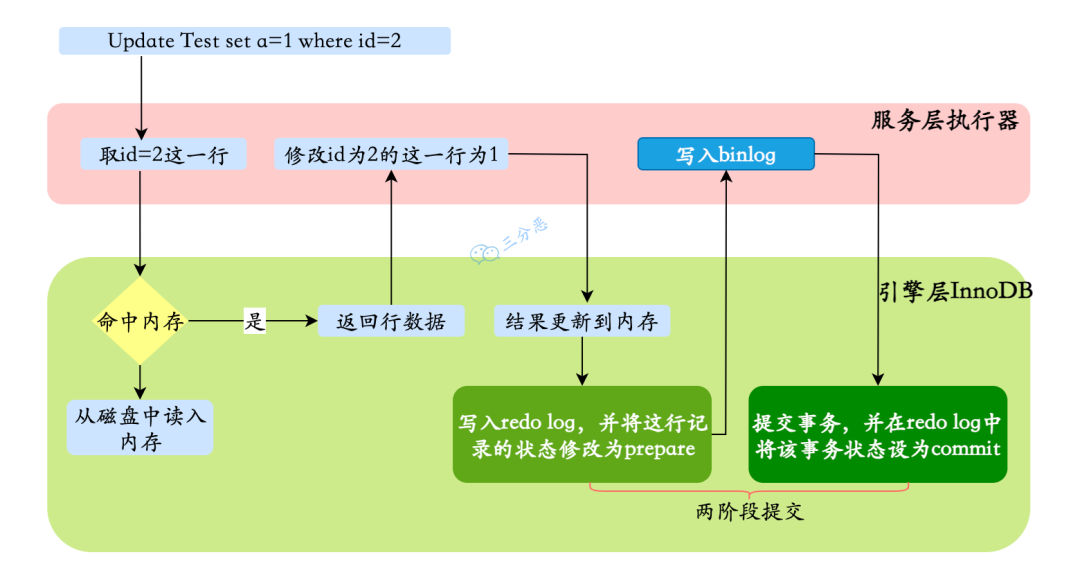
- 执行器先找引擎获取 ID=2 这一行。ID 是主键,存储引擎检索数据,找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
从上图可以看出,MySQL 在执行更新语句的时候,在服务层进行语句的解析和执行,在引擎层进行数据的提取和存储;同时在服务层对 binlog 进行写入,在 InnoDB 内进行 redo log 的写入。
不仅如此,在对 redo log 写入时有两个阶段的提交,一是 binlog 写入之前prepare状态的写入,二是 binlog 写入之后commit状态的写入。
为什么要两阶段提交呢?
我们可以假设不采用两阶段提交的方式,而是采用“单阶段”进行提交,即要么先写入 redo log,后写入 binlog;要么先写入 binlog,后写入 redo log。这两种方式的提交都会导致原先数据库的状态和被恢复后的数据库的状态不一致。
先写入 redo log,后写入 binlog:
在写完 redo log 之后,数据此时具有crash-safe能力,因此系统崩溃,数据会恢复成事务开始之前的状态。但是,若在 redo log 写完时候,binlog 写入之前,系统发生了宕机。此时 binlog 没有对上面的更新语句进行保存,导致当使用 binlog 进行数据库的备份或者恢复时,就少了上述的更新语句。从而使得id=2这一行的数据没有被更新。
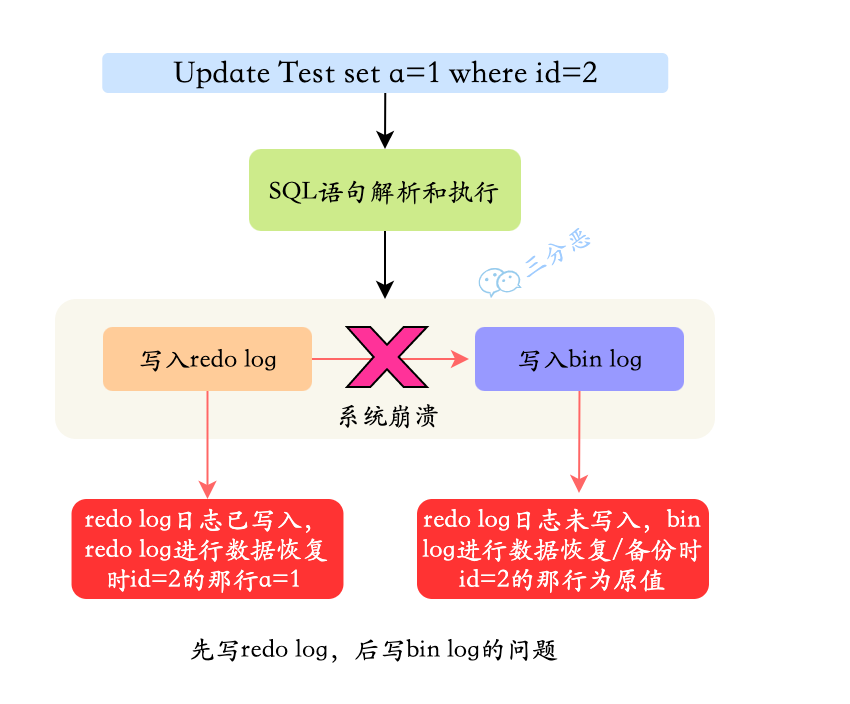
先写入 binlog,后写入 redo log:
写完 binlog 之后,所有的语句都被保存,所以通过 binlog 复制或恢复出来的数据库中 id=2 这一行的数据会被更新为 a=1。但是如果在 redo log 写入之前,系统崩溃,那么 redo log 中记录的这个事务会无效,导致实际数据库中id=2这一行的数据并没有更新。
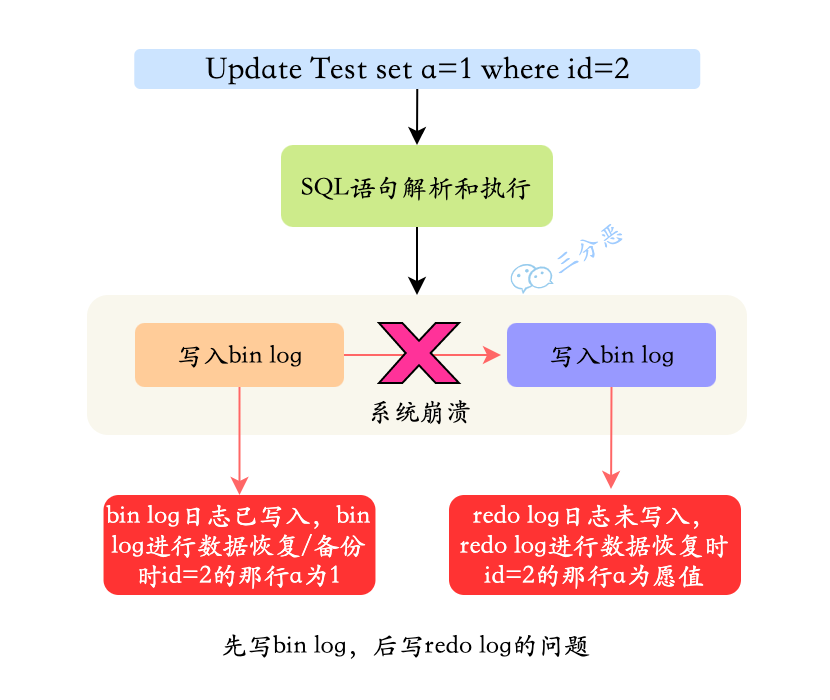
简单说,redo log 和 binlog 都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。
27.redo log 怎么刷入磁盘的知道吗?
redo log 的写入不是直接落到磁盘,而是在内存中设置了一片称之为redo log buffer的连续内存空间,也就是redo日志缓冲区。
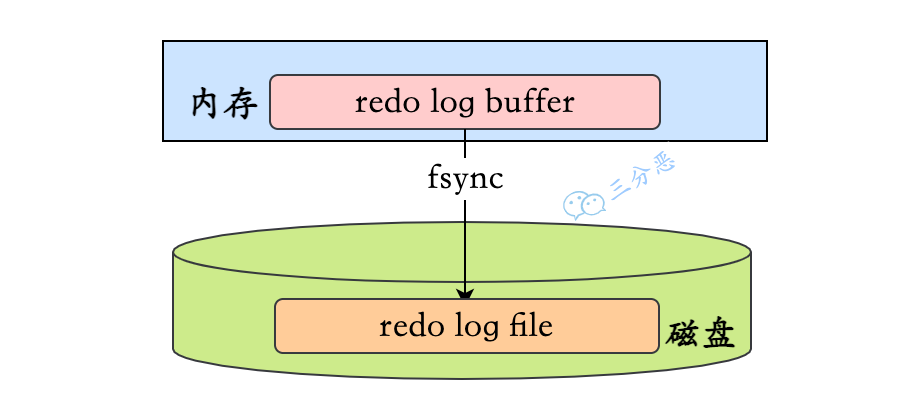
什么时候会刷入磁盘?
在如下的一些情况中,log buffer 的数据会刷入磁盘:
- log buffer 空间不足时
log buffer 的大小是有限的,如果不停的往这个有限大小的 log buffer 里塞入日志,很快它就会被填满。如果当前写入 log buffer 的 redo 日志量已经占满了 log buffer 总容量的大约一半左右,就需要把这些日志刷新到磁盘上。
- 事务提交时
在事务提交时,为了保证持久性,会把 log buffer 中的日志全部刷到磁盘。注意,这时候,除了本事务的,可能还会刷入其它事务的日志。
- 后台线程输入
有一个后台线程,大约每秒都会刷新一次log buffer中的redo log到磁盘。
- 正常关闭服务器时
- 触发 checkpoint 规则
重做日志缓存、重做日志文件都是以块(block)的方式进行保存的,称之为重做日志块(redo log block),块的大小是固定的 512 字节。我们的 redo log 它是固定大小的,可以看作是一个逻辑上的 log group,由一定数量的log block 组成。
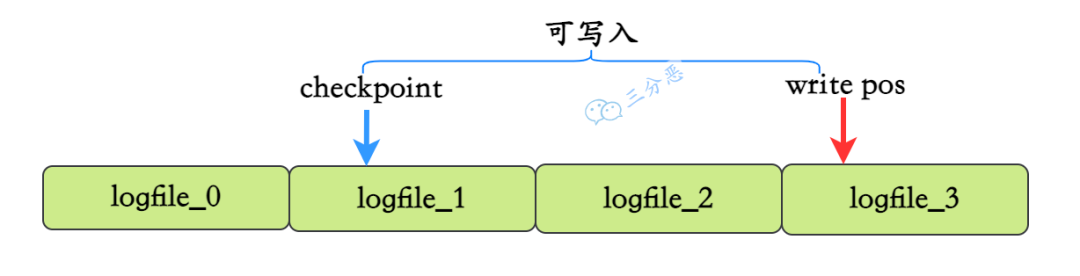
它的写入方式是从头到尾开始写,写到末尾又回到开头循环写。
其中有两个标记位置:
write pos是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到磁盘。
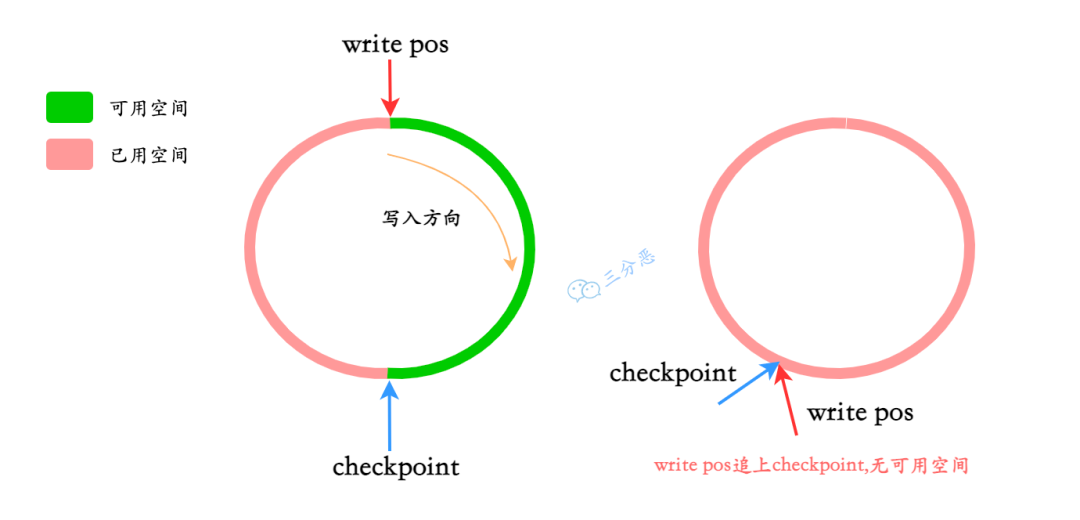
当write_pos追上checkpoint时,表示 redo log 日志已经写满。这时候就不能接着往里写数据了,需要执行checkpoint规则腾出可写空间。
所谓的checkpoint 规则,就是 checkpoint 触发后,将 buffer 中日志页都刷到磁盘。
28.慢 SQL 如何定位呢?
什么是慢 SQL?
顾名思义,慢 SQL 也就是执行时间较长的 SQL 语句,MySQL 中 long_query_time 默认值是 10 秒,也就是执行时间超过 10 秒的 SQL 语句会被记录到慢查询日志中。
可通过 show variables like ‘long_query_time’; 查看当前的 long_query_time 值。
生产环境中,10 秒太久了,超过 1 秒的都可以认为是慢 SQL 了。
那怎么定位慢 SQL 呢?
要想定位慢 SQL,需要了解一下 SQL 的执行过程:
- 客户端发送 SQL 语句给 MySQL 服务器。
- 如果查询缓存打开则会优先查询缓存,如果缓存中有对应的结果,直接返回给客户端。不过,MySQL 8.0 版本已经移除了查询缓存。
- 分析器对 SQL 语句进行语法分析,判断是否有语法错误。
- 搞清楚 SQL 语句要干嘛后,MySQL 还会通过优化器生成执行计划。
- 执行器调用存储引擎的接口,执行 SQL 语句。
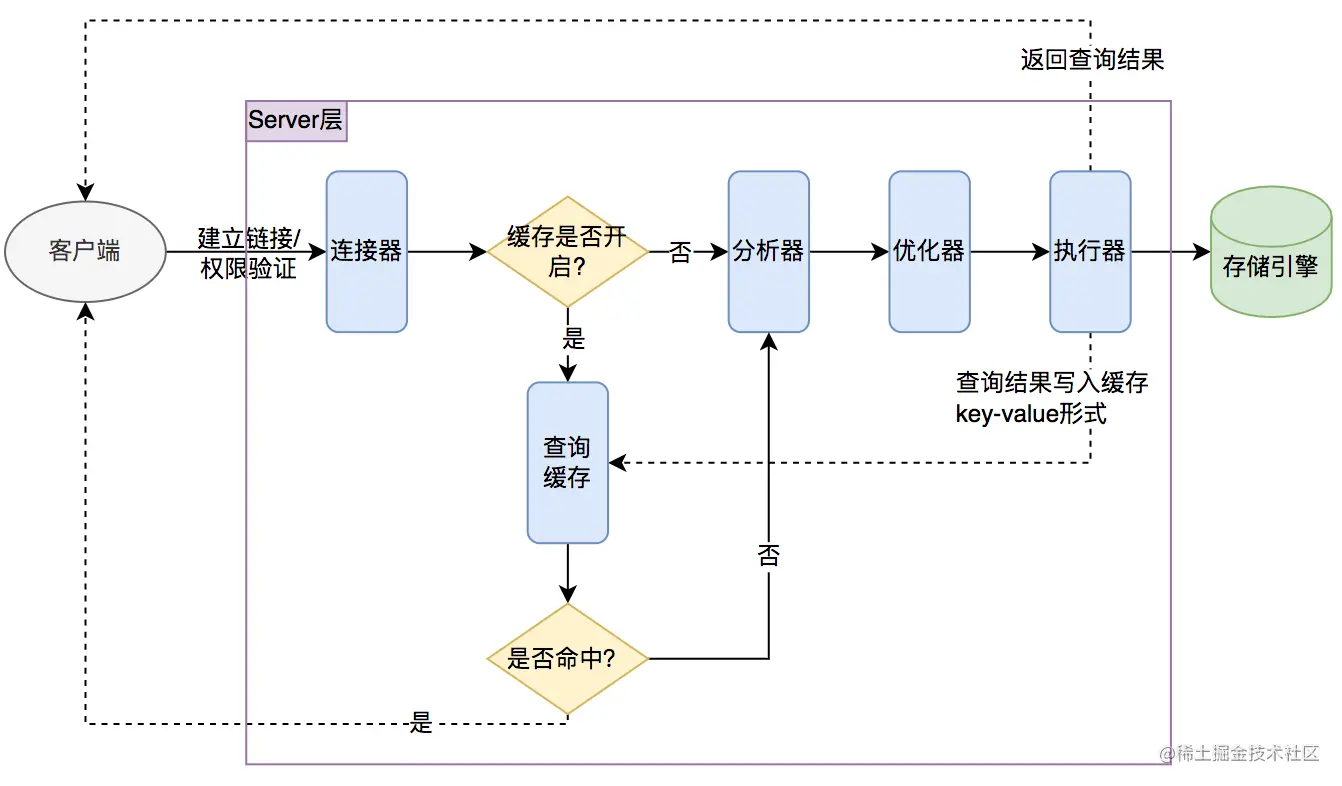
SQL 执行过程中,优化器通过成本计算预估出执行效率最高的方式,基本的预估维度为:
- IO 成本:从磁盘读取数据到内存的开销。
- CPU 成本:CPU 处理内存中数据的开销。
基于这两个维度,可以得出影响 SQL 执行效率的因素有:
①、IO 成本
- 数据量:数据量越大,IO 成本越高。所以要避免
select *;尽量分页查询。 - 数据从哪读取:尽量通过索引加快查询。
②、CPU 成本
- 尽量避免复杂的查询条件,如有必要,考虑对子查询结果进行过滤。
- 尽量缩减计算成本,比如说为排序字段加上索引,提高排序效率;比如说使用 union all 替代 union,减少去重处理。
排查 SQL 效率主要通过两种手段:
- 慢查询日志:开启 MySQL 慢查询日志,再通过一些工具比如 mysqldumpslow 去分析对应的慢查询日志,找出问题的根源。
- 服务监控:可以在业务的基建中加入对慢 SQL 的监控,常见的方案有字节码插桩、连接池扩展、ORM 框架过程,对服务运行中的慢 SQL 进行监控和告警。
也可以使用 show processlist; 查看当前正在执行的 SQL 语句,找出执行时间较长的 SQL。
找到对应的慢 SQL 后,使用 EXPLAIN 命令查看 MySQL 是如何执行 SQL 语句的,再根据执行计划对 SQL 进行优化。
EXPLAIN SELECT * FROM your_table WHERE conditions;
慢sql日志怎么开启?
慢 SQL 日志的开启方式有多种,比如说直接编辑 MySQL 的配置文件 my.cnf 或 my.ini,设置 slow_query_log 参数为 1,设置 slow_query_log_file 参数为慢查询日志的路径,设置 long_query_time 参数为慢查询的时间阈值。
[mysqld]
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 2 // 记录执行时间超过2秒的查询
然后重启 MySQL 服务就好了,也可以通过 set global 命令动态设置。
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';
SET GLOBAL long_query_time = 2;
29.有哪些方式优化 SQL?
在进行 SQL 优化的时候,主要通过以下几个方面进行优化:
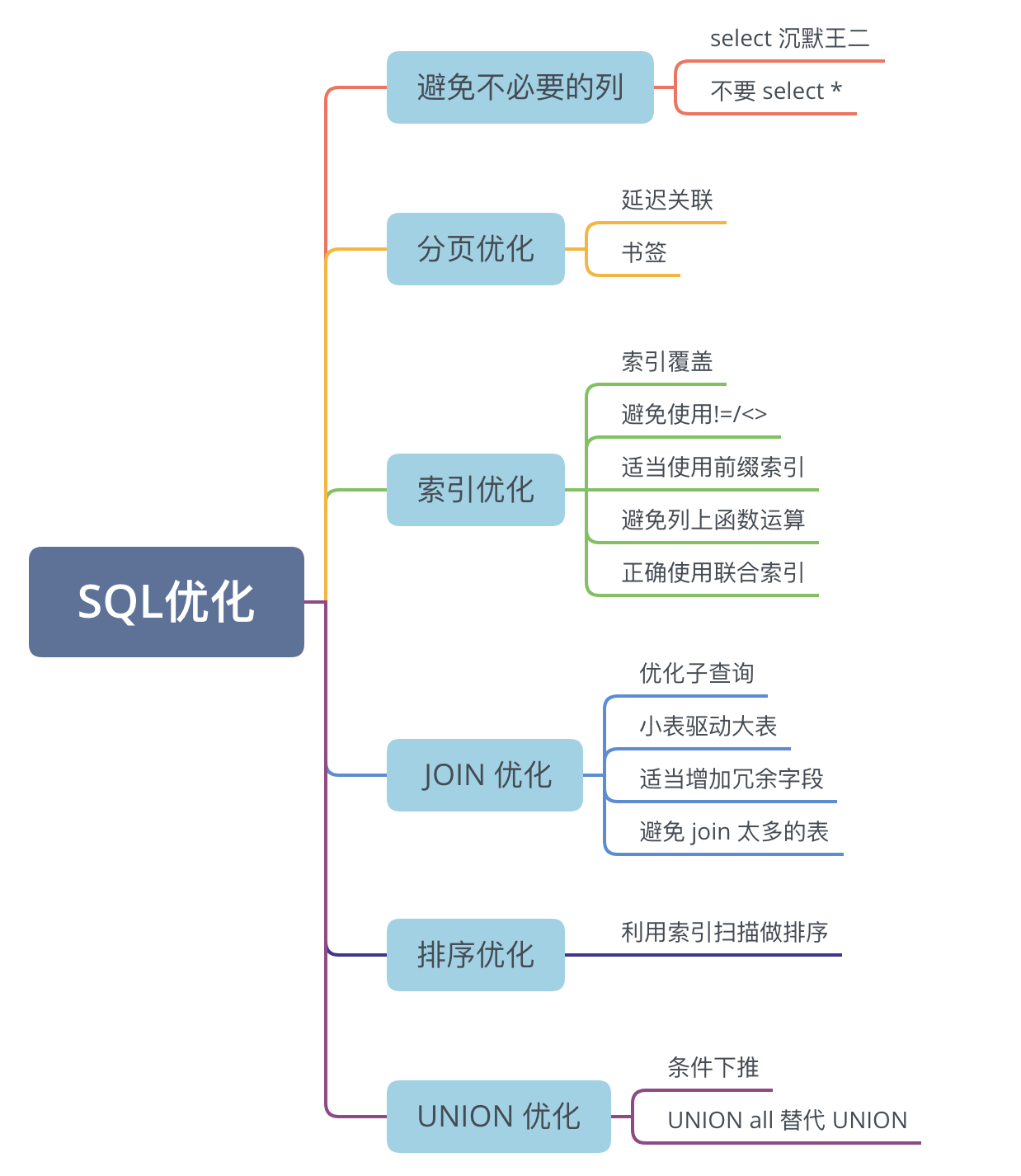
如何避免不必要的列?
比如说尽量避免使用 select *,只查询需要的列,减少数据传输量。
SELECT * FROM employees WHERE department_id = 5;
改成:
SELECT employee_id, first_name, last_name FROM employees WHERE department_id = 5;
如何进行分页优化?
当数据量巨大时,传统的LIMIT和OFFSET可能会导致性能问题,因为数据库需要扫描OFFSET + LIMIT数量的行。
延迟关联(Late Row Lookups)和书签(Seek Method)是两种优化分页查询的有效方法。
①、延迟关联
延迟关联适用于需要从多个表中获取数据且主表行数较多的情况。它首先从索引表中检索出需要的行 ID,然后再根据这些 ID 去关联其他的表获取详细信息。
SELECT e.id, e.name, d.details
FROM employees e
JOIN department d ON e.department_id = d.id
ORDER BY e.id
LIMIT 1000, 20;
延迟关联后:
SELECT e.id, e.name, d.details
FROM (
SELECT id
FROM employees
ORDER BY id
LIMIT 1000, 20
) AS sub
JOIN employees e ON sub.id = e.id
JOIN department d ON e.department_id = d.id;
首先对employees表进行分页查询,仅获取需要的行的 ID,然后再根据这些 ID 关联获取其他信息,减少了不必要的 JOIN 操作。
②、书签(Seek Method)
书签方法通过记住上一次查询返回的最后一行的某个值,然后下一次查询从这个值开始,避免了扫描大量不需要的行。
假设需要对用户表进行分页,根据用户 ID 升序排列。
SELECT id, name
FROM users
ORDER BY id
LIMIT 1000, 20;
书签方式:
SELECT id, name
FROM users
WHERE id > last_max_id -- 假设last_max_id是上一页最后一行的ID
ORDER BY id
LIMIT 20;
优化后的查询不再使用OFFSET,而是直接从上一页最后一个用户的 ID 开始查询。这里的last_max_id是上一次查询返回的最后一行的用户 ID。这种方法有效避免了不必要的数据扫描,提高了分页查询的效率。
如何进行索引优化?
正确地使用索引可以显著减少 SQL 的查询时间,通常可以从索引覆盖、避免使用 != 或者 <> 操作符、适当使用前缀索引、避免列上函数运算、正确使用联合索引等方面进行优化。
①、利用覆盖索引
使用非主键索引查询数据时需要回表,但如果索引的叶节点中已经包含要查询的字段,那就不会再回表查询了,这就叫覆盖索引。
举个例子,现在要从 test 表中查询 city 为上海的 name 字段。
select name from test where city='上海'
如果仅在 city 字段上添加索引,那么这条查询语句会先通过索引找到 city 为上海的行,然后再回表查询 name 字段,这就是回表查询。
为了避免回表查询,可以在 city 和 name 字段上建立联合索引,这样查询结果就可以直接从索引中获取。
alter table test add index index1(city,name);
②、避免使用 != 或者 <> 操作符
!= 或者 <> 操作符会导致 MySQL 无法使用索引,从而导致全表扫描。
例如,可以把column<>'aaa',改成column>'aaa' or column<'aaa',就可以使用索引了。
优化策略就是尽可能使用 =、>、<、BETWEEN等操作符,它们能够更好地利用索引。
为什么 != 或 <> 操作符会导致无法使用索引?
- 索引的工作原理:索引是通过排序和查找来加速数据访问的。对于等值查询(如 =)、范围查询(如 BETWEEN、<、>)等,索引可以快速定位到符合条件的记录。
- 不等查询的特性:!= 或 <> 操作符表示不等于某个值,这意味着需要查找所有不等于该值的记录。由于这些记录可能分布在整个数据集中,索引无法有效地利用排序特性来快速定位这些记录。
③、适当使用前缀索引
适当使用前缀索引可以降低索引的空间占用,提高索引的查询效率。
比如,邮箱的后缀一般都是固定的@xxx.com,那么类似这种后面几位为固定值的字段就非常适合定义为前缀索引:
alter table test add index index2(email(6));
需要注意的是,MySQL 无法利用前缀索引做 order by 和 group by 操作。
④、避免列上使用函数
在 where 子句中直接对列使用函数会导致索引失效,因为数据库需要对每行的列应用函数后再进行比较,无法直接利用索引
select name from test where date_format(create_time,'%Y-%m-%d')='2021-01-01';
可以改成:
select name from test where create_time>='2021-01-01 00:00:00' and create_time<'2021-01-02 00:00:00';
通过日期的范围查询,而不是在列上使用函数,可以利用 create_time 上的索引。
⑤、正确使用联合索引
正确地使用联合索引可以极大地提高查询性能,联合索引的创建应遵循最左前缀原则,即索引的顺序应根据列在查询中的使用频率和重要性来安排。
select * from messages where sender_id=1 and receiver_id=2 and is_read=0;
那就可以为 sender_id、receiver_id 和 is_read 这三个字段创建联合索引,但是要注意索引的顺序,应该按照查询中的字段顺序来创建索引。
alter table messages add index index3(sender_id,receiver_id,is_read);
如何进行 JOIN 优化?
对于 JOIN 操作,可以通过优化子查询、小表驱动大表、适当增加冗余字段、避免 join 太多表等方式来进行优化。
①、优化子查询
子查询,特别是在 select 列表和 where 子句中的子查询,往往会导致性能问题,因为它们可能会为每一行外层查询执行一次子查询。
使用子查询:
select name from A where id in (select id from B);
使用 JOIN 代替子查询:
select A.name from A join B on A.id=B.id;
②、小表驱动大表
在执行 JOIN 操作时,应尽量让行数较少的表(小表)驱动行数较多的表(大表),这样可以减少查询过程中需要处理的数据量。
比如 left join,左表是驱动表,所以 A 表应小于 B 表,这样建立连接的次数就少,查询速度就快了。
select name from A left join B;
③、适当增加冗余字段
在某些情况下,通过在表中适当增加冗余字段来避免 JOIN 操作,可以提高查询效率,尤其是在高频查询的场景下。
比如,我们有一个订单表和一个商品表,查询订单时需要显示商品名称,如果每次都通过 JOIN 操作查询商品表,会降低查询效率。这时可以在订单表中增加一个冗余字段,存储商品名称,这样就可以避免 JOIN 操作。
select order_id,product_name from orders;
④、避免使用 JOIN 关联太多的表
《阿里巴巴 Java 开发手册》上就规定,不要使用 join 关联太多的表,最多不要超过 3 张表。
因为 join 太多表会降低查询的速度,返回的数据量也会变得非常大,不利于后续的处理。
如果业务逻辑允许,可以考虑将复杂的 JOIN 查询分解成多个简单查询,然后在应用层组合这些查询的结果。
如何进行排序优化?
MySQL 生成有序结果的方式有两种:一种是对结果集进行排序操作,另外一种是按照索引顺序扫描得出的自然有序结果。
因此在设计索引的时候要充分考虑到排序的需求。
select id, name from users order by name;
如果 name 字段上有索引,那么 MySQL 可以直接利用索引的有序性,避免排序操作。
如何进行 UNION 优化?
UNION 操作用于合并两个或者多个 SELECT 语句的结果集。
①、条件下推
条件下推是指将 where、limit 等子句下推到 union 的各个子查询中,以便优化器可以充分利用这些条件进行优化。
假设我们有两个查询分支,需要合并结果并过滤:
SELECT * FROM (
SELECT * FROM A
UNION
SELECT * FROM B
) AS sub
WHERE sub.id = 1;
可以改写成:
SELECT * FROM A WHERE id = 1
UNION
SELECT * FROM B WHERE id = 1;
通过将查询条件下推到 UNION 的每个分支中,每个分支查询都只处理满足条件的数据,减少了不必要的数据合并和过滤。
30.怎么看执行计划 explain,如何理解其中各个字段的含义?
explain 是 MySQL 提供的一个用于查看查询执行计划的工具,可以帮助我们分析查询语句的性能瓶颈,找出慢 SQL 的原因。
使用方式也非常简单,在 select 语句前加上 explain 关键字就可以了。
explain select * from students where id =9
接下来,我们需要理解 explain 输出结果中各个字段的含义。
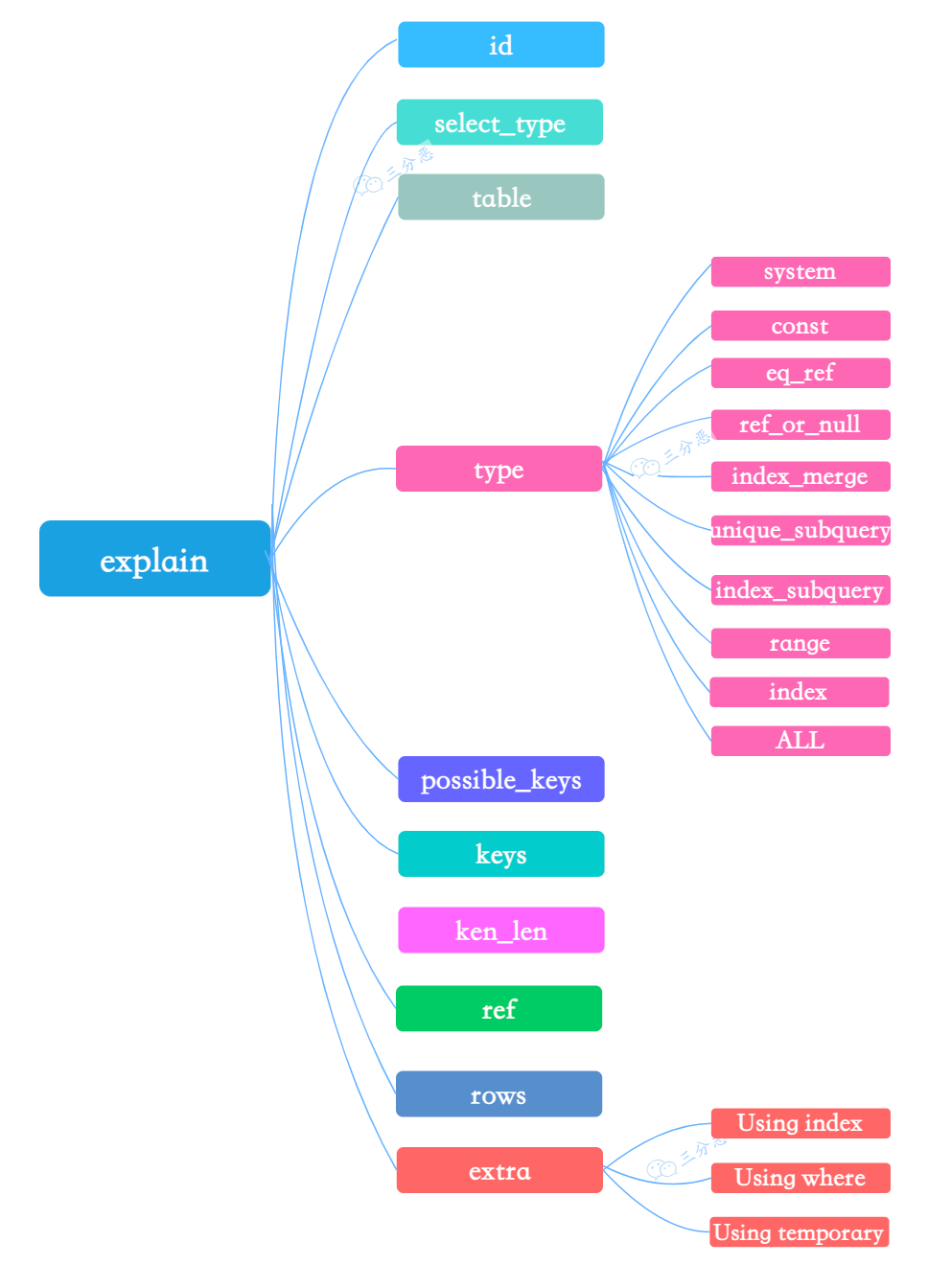
①、id 列:查询的标识符。
②、select_type 列:查询的类型。常见的类型有:
- SIMPLE:简单查询,不包含子查询或者 UNION 查询。
- PRIMARY:查询中如果包含子查询,则最外层查询被标记为 PRIMARY。
- SUBQUERY:子查询。
- DERIVED:派生表的 SELECT,FROM 子句的子查询。
③、table 列:查的哪个表。
④、type 列:表示 MySQL 在表中找到所需行的方式,性能从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL。
- system,表只有一行,一般是系统表,往往不需要进行磁盘 IO,速度非常快
- const、eq_ref、ref:这些类型表示 MySQL 可以使用索引来查找单个行,其中 const 是最优的,表示查询最多返回一行。
- range:只检索给定范围的行,使用索引来检索。在
where语句中使用bettween...and、<、>、<=、in等条件查询type都是range。 - index:遍历索引树读取。
- ALL:全表扫描,效率最低。
⑤、possible_keys 列:可能会用到的索引,但并不一定实际被使用。
⑥、key 列:实际使用的索引。如果为 NULL,则没有使用索引。
⑦、key_len 列:MySQL 决定使用的索引长度(以字节为单位)。当表有多个索引可用时,key_len 字段可以帮助识别哪个索引最有效。通常情况下,更短的 key_len 意味着数据库在比较键值时需要处理更少的数据。
⑧、ref 列:用于与索引列比较的值来源。
- const:表示常量,这个值是在查询中被固定的。例如在 WHERE
column = 'value'中。 - 一个或多个列的名称,通常在 JOIN 操作中,表示 JOIN 条件依赖的字段。
- NULL,表示没有使用索引,或者查询使用的是全表扫描。
⑨、rows 列:估算查到结果集需要扫描的数据行数,原则上 rows 越少越好。
⑩、Extra 列:附加信息。
- Using index:表示只利用了索引。
- Using where:表示使用了 WHERE 过滤。
- Using temporary :表示使用了临时表来存储中间结果。
示例:
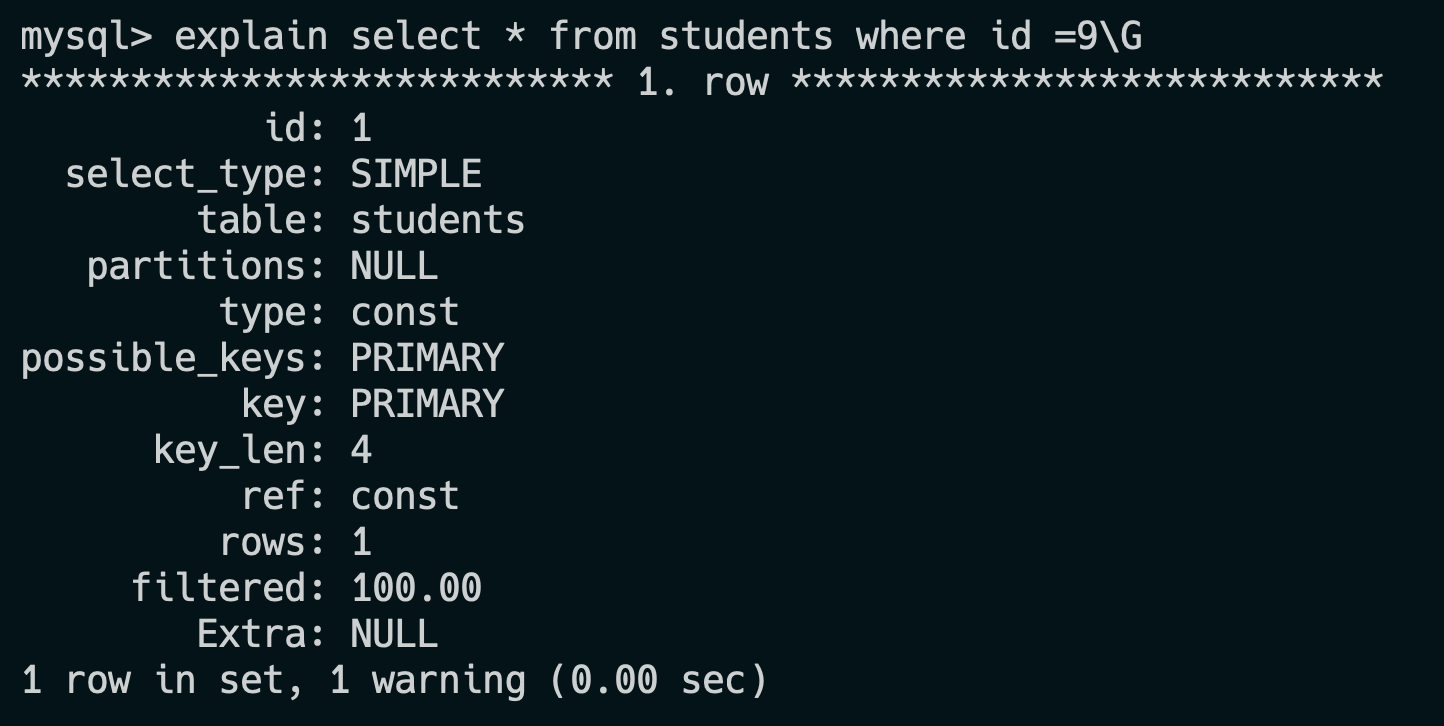
31.为什么使用索引会加快查询?
数据库文件是存储在磁盘上的,磁盘 I/O 是数据库操作中最耗时的部分之一。没有索引时,数据库会进行全表扫描(Sequential Scan),这意味着它必须读取表中的每一行数据来查找匹配的行(时间效率为 O(n))。当表的数据量非常大时,就会导致大量的磁盘 I/O 操作。
有了索引,就可以直接跳到索引指示的数据位置,而不必扫描整张表,从而大大减少了磁盘 I/O 操作的次数。
MySQL 的 InnoDB 存储引擎默认使用 B+ 树来作为索引的数据结构,而 B+ 树的查询效率非常高,时间复杂度为 O(logN)。
索引文件相较于数据库文件,体积小得多,查到索引之后再映射到数据库记录,查询效率就会高很多。
索引就好像书的目录,通过目录去查找对应的章节内容会比一页一页的翻书快很多。
可通过 create index 创建索引,比如:
create index idx_name on students(name);
32.能简单说一下索引的分类吗?
MySQL 的索引可以显著提高查询的性能,可以从三个不同的维度对索引进行分类(功能、数据结构、存储位置):
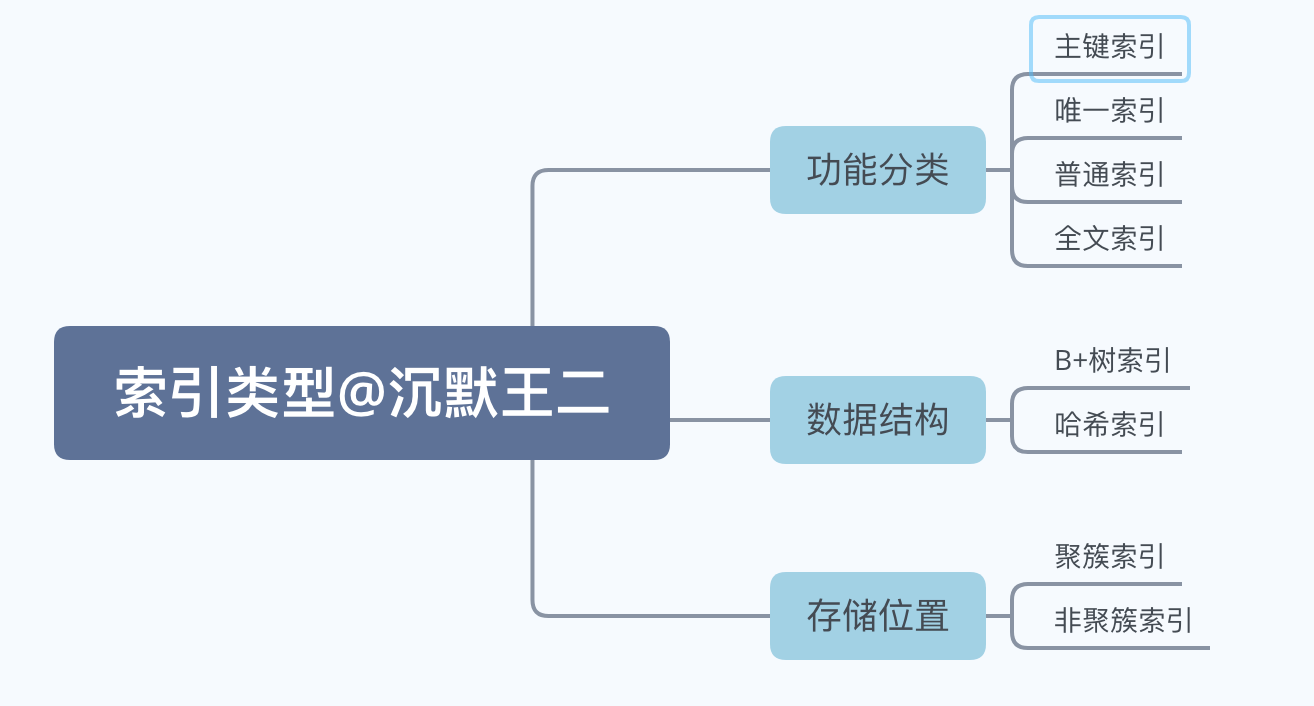
功能上的分类
①、主键索引: 表中每行数据唯一标识的索引,强调列值的唯一性和非空性。
当创建表的时候,可以直接指定主键索引:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255)
);
id 列被指定为主键索引,同时,MySQL 会自动为这个列创建一个聚簇索引(主键索引一定是聚簇索引)。
可以通过 show index from table_name 查看索引信息,比如前面创建的 users 表:
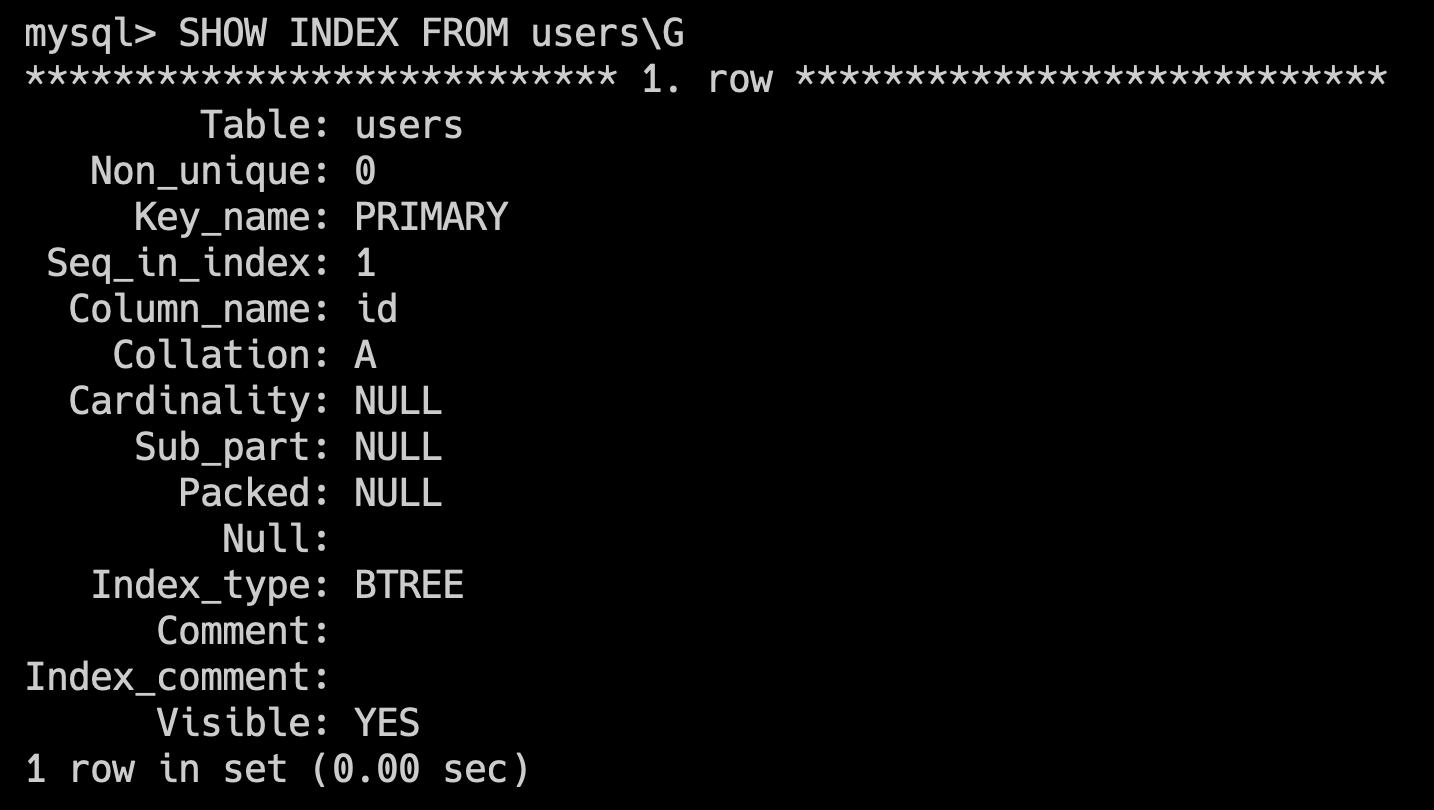
Non_unique如果索引不能包含重复词,则为 0;如果可以,则为 1。这可以帮助我们区分是唯一索引还是普通索引。Key_name索引的名称。如果索引是主键,那么这个值是 PRIMARY。Column_name索引所包含的字段名。Index_type索引的类型,比如 BTREE、HASH 等。
②、唯一索引: 保证数据列中每行数据的唯一性,但允许有空值。
可以通过下面的语句创建唯一索引:
CREATE UNIQUE INDEX idx_username ON users(username);
同样可以通过 show index from table_name 确认索引信息
Non_unique 为 0,表示这是一个唯一索引。
③、普通索引: 基本的索引类型,用于加速查询。
可以通过下面的语句创建普通索引:
CREATE INDEX idx_email ON users(email);
这次我们通过下面的语句一起把三个索引的关键信息查出来:
SELECT `TABLE_NAME` AS `Table`, `NON_UNIQUE`, `INDEX_NAME` AS `Key_name`, `COLUMN_NAME` AS `Column_name`, `INDEX_TYPE` AS `Index_type`
FROM information_schema.statistics
WHERE `TABLE_NAME` = 'users' AND `TABLE_SCHEMA` = DATABASE();
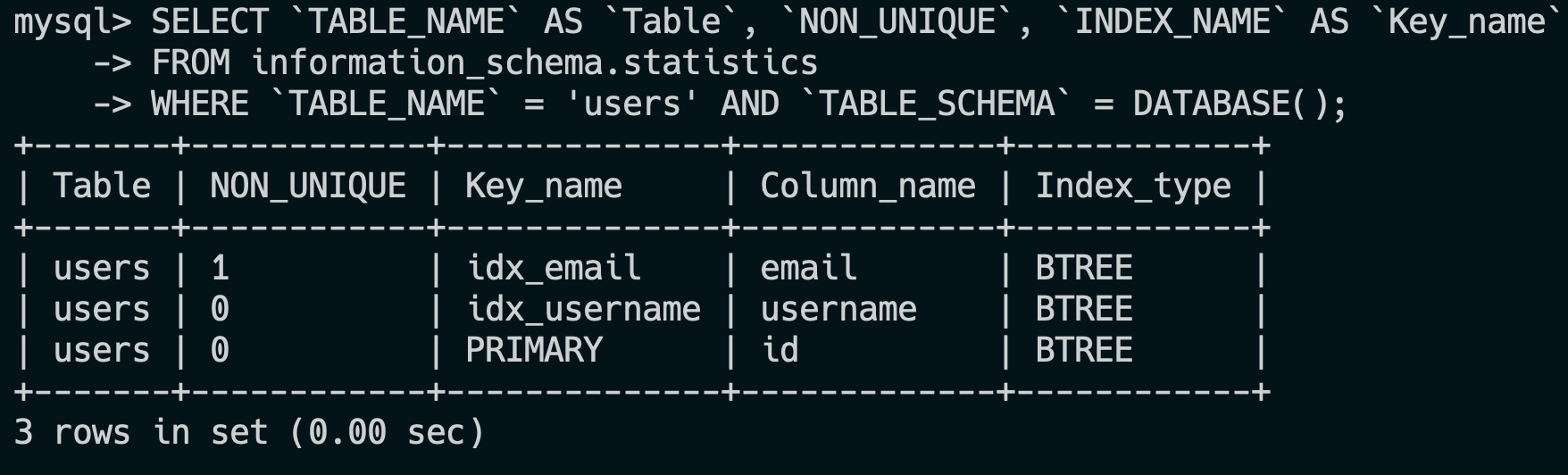
可以确定 idx_email 是一个普通索引,因为 Non_unique 为 1。
④、全文索引:特定于文本数据的索引,用于提高文本搜索的效率。
假设有一个名为 articles 的表,下面这条语句在 content 列上创建了一个全文索引。
CREATE FULLTEXT INDEX idx_article_content ON articles(content);
数据结构上分类
①、B+树索引:最常见的索引类型,一种将索引值按照一定的算法,存入一个树形的数据结构中(二叉树),每次查询都从树的根节点开始,一次遍历叶子节点,找到对应的值。查询效率是 O(logN)。
也是 InnoDB 存储引擎的默认索引类型。
B+ 树是 B 树的升级版,B+ 树中的非叶子节点都不存储数据,只存储索引。叶子节点中存储了所有的数据,并且构成了一个从小到大的有序双向链表,使得在完成一次树的遍历定位到范围查询的起点后,可以直接通过叶子节点间的指针顺序访问整个查询范围内的所有记录,而无需对树进行多次遍历。这在处理大范围的查询时特别高效。
因为 B+ 树是 InnoDB 的默认索引类型,所以创建 B+ 树的时候不需要指定索引类型。
CREATE TABLE example_btree (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
INDEX name_index (name)
) ENGINE=InnoDB;
②、Hash 索引:基于哈希表的索引,查询效率可以达到 O(1),但是只适合 = 和 in 查询,不适合范围查询。
Hash 索引在原理上和 Java 中的 HashMap 类似,当发生哈希冲突的时候也是通过拉链法来解决
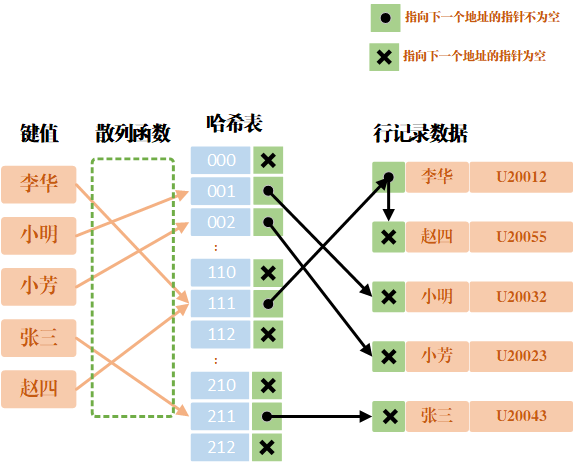
可以通过下面的语句创建哈希索引:
CREATE TABLE example_hash (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
UNIQUE HASH (name)
) ENGINE=MEMORY;
注意,我们这里创建的是 MEMORY 存储引擎,InnoDB 并不提供直接创建哈希索引的选项,因为 B+ 树索引能够很好地支持范围查询和等值查询,满足了大多数数据库操作的需要。
不过,InnoDB 存储引擎内部使用了一种名为“自适应哈希索引”(Adaptive Hash Index, AHI)的技术。
自适应哈希索引并不是由用户显式创建的,而是 InnoDB 根据数据访问的模式自动建立和管理的。当 InnoDB 发现某个索引被频繁访问时,会在内存中创建一个哈希索引,以加速对这个索引的访问。
SHOW VARIABLES LIKE 'innodb_adaptive_hash_index';
如果返回的值是 ON,说明自适应哈希索引是开启的。
从存储位置上分类
①、聚簇索引:聚簇索引的叶子节点保存了一行记录的所有列信息。也就是说,聚簇索引的叶子节点中,包含了一个完整的记录行。
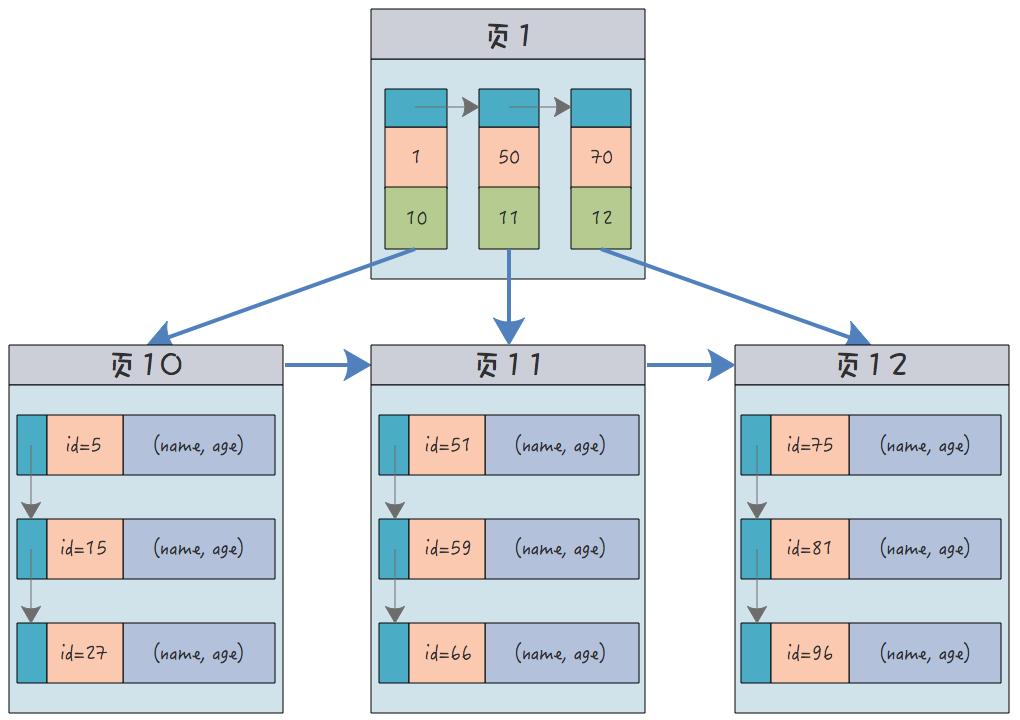
②、非聚簇索引:它的叶子节点只包含一个主键值,通过非聚簇索引查找记录要先找到主键,然后通过主键再到聚簇索引中找到对应的记录行,这个过程被称为回表。
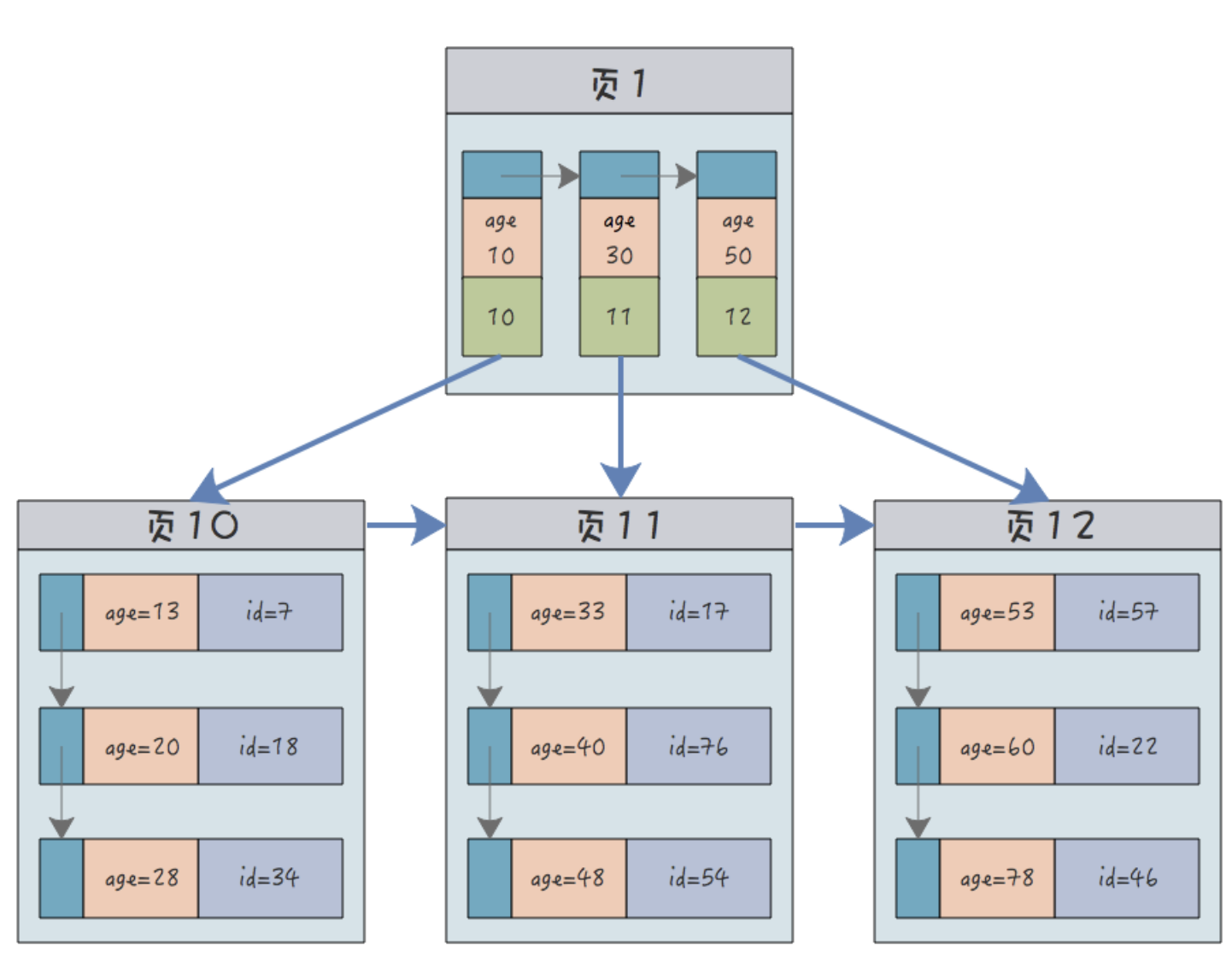
InnoDB 存储引擎的主键使用的是聚簇索引,MyISAM 存储引擎不管是主键索引,还是二级索引使用的都是非聚簇索引。
33.创建索引有哪些注意点?
尽管索引能提高查询性能,但不当的使用也会带来一系列问题。在加索引时需要注意以下几点:
①、选择合适的列作为索引
- 经常作为查询条件(WHERE 子句)、排序条件(ORDER BY 子句)、分组条件(GROUP BY 子句)的列是建立索引的好候选。
- 区分度低的字段,例如性别,不要建索引
- 频繁更新的字段,不要作为主键或者索引
- 不建议用无序的值(例如身份证、UUID )作为索引,当主键具有不确定性,会造成叶子节点频繁分裂,出现磁盘存储的碎片化
②、避免过多的索引
- 每个索引都需要占用额外的磁盘空间。
- 更新表(INSERT、UPDATE、DELETE 操作)时,所有的索引都需要被更新。
- 维护索引文件需要成本;还会导致页分裂,IO 次数增多。
③、利用前缀索引和索引列的顺序
- 对于字符串类型的列,可以考虑使用前缀索引来减少索引大小。
- 在创建复合索引时,应该根据查询条件将最常用作过滤条件的列放在前面。
34.索引哪些情况下会失效呢?
- 在索引列上使用函数或表达式:如果在查询中对索引列使用了函数或表达式,那么索引可能无法使用,因为数据库无法预先计算出函数或表达式的结果。例如:
SELECT * FROM table WHERE YEAR(date_column) = 2021。 - 使用不等于(
<>)或者 NOT 操作符:这些操作符通常会使索引失效,因为它们会扫描全表。 - 使用 LIKE 操作符,但是通配符在最前面:如果 LIKE 的模式串是以“%”或者“_”开头的,那么索引也无法使用。例如:
SELECT * FROM table WHERE column LIKE '%abc'。 - OR 操作符:如果查询条件中使用了 OR,并且 OR 两边的条件分别涉及不同的索引,那么这些索引可能都无法使用。
- 联合索引不满足最左前缀原则时,索引会失效。
35.索引不适合哪些场景呢?
- 数据表较小:当表中的数据量很小,或者查询需要扫描表中大部分数据时,数据库优化器可能会选择全表扫描而不是使用索引。在这种情况下,维护索引的开销可能大于其带来的性能提升。
- 频繁更新的列:对于经常进行更新、删除或插入操作的列,使用索引可能会导致性能下降。因为每次数据变更时,索引也需要更新,这会增加额外的写操作负担。
性别字段要建立索引吗?
性别字段通常不适合建立索引。因为性别字段的选择性(区分度)较低,独立索引效果有限。
如果性别字段又很少用于查询,表的数据规模较小,那么建立索引反而会增加额外的存储空间和维护成本。
如果性别字段确实经常用于查询条件,数据规模也比较大,可以将性别字段作为复合索引的一部分,与选择性较高的字段一起加索引,会更好一些。
什么是区分度?
区分度(Selectivity)是衡量一个字段在数据库表中唯一值的比例,用来表示该字段在索引优化中的有效性。
区分度 = 字段的唯一值数量 / 字段的总记录数;接近 1,字段值大部分是唯一的。例如,用户的唯一 ID,一般都是主键索引。接近 0,则说明字段值重复度高。
例如,一个表中有 1000 条记录,其中性别字段只有两个值(男、女),那么性别字段的区分度只有 0.002。
高区分度的字段更适合拿来作为索引,因为索引可以更有效地缩小查询范围。
MySQL查看字段区分度的命令?
在 MySQL 中,可以通过 COUNT(DISTINCT column_name) 和 COUNT(*) 的比值来计算字段的区分度。例如:
SELECT
COUNT(DISTINCT gender) / COUNT(*) AS gender_selectivity
FROM
users;
索引是不是建的越多越好呢?
当然不是。
- 索引会占据磁盘空间
- 索引虽然会提高查询效率,但是会降低更新表的效率。比如每次对表进行增删改操作,MySQL 不仅要保存数据,还有保存或者更新对应的索引文件。